Способ перевода информации и устройство для осуществления этого способа







Формула / Реферат
1. Способ машинного перевода информации, представленной в виде последовательности символов первого языка, в последовательность символов второго языка, включающий
сохранение в базе знаний шаблонных сегментов в виде последовательностей символов указанного первого языка, а также в логической связи с ними шаблонных сегментов в виде последовательностей символов второго языка,
разделение последовательности символов указанного первого языка на структурные сегменты (102),
сравнение структурного сегмента с сохраненными шаблонными сегментами (104) в виде последовательностей символов первого языка,
выполнение попытки выбора одного шаблонного сегмента (110) по наибольшему сходству со структурным сегментом на основе указанного сравнения,
считывание шаблонного, т.е. эквивалентного, сегмента (121), логически связанного с выбранным шаблонным сегментом, в виде последовательности символов второго языка и
перевод указанного структурного сегмента в сегмент перевода в виде последовательности символов второго языка с использованием указанного эквивалентного сегмента (122),
характеризующийся тем, что он включает идентификацию промежуточного слова и/или суффикса, а указанная стадия разделения последовательности символов на структурные сегменты основана, по существу, на идентификации указанных промежуточного слова и/или суффикса, которые образуют таким образом начало или конец структурного сегмента.
2. Способ по п.1, характеризующийся тем, что указанную информацию, подлежащую представлению в виде последовательности символов второго языка, получают путем сочетания сегментов перевода (124).
3. Способ по п.1 или 2, характеризующийся тем, что, когда в результате сравнения структурных сегментов шаблонный сегмент, подлежащий выбору, не найден, структурный сегмент отображают при помощи интерфейса пользователя, а эквивалентный сегмент отображенного структурного сегмента сохраняют в базе знаний посредством интерфейса пользователя.
4. Способ по одному из пп.1-3, характеризующийся тем, что указанный структурный сегмент содержит знак препинания.
5. Способ по одному из пп.1-4, характеризующийся тем, что в логической связи с шаблонным сегментом сохраняют идентификатор типа шаблонного сегмента.
6. Способ по одному из пп.1-5, характеризующийся тем, что логически связывают друг с другом более двух шаблонных сегментов разных языков.
7. Способ по одному из пп.1-6, характеризующийся тем, что при переводе первой информации через интерфейс пользователя вводят данные для обновления базы знаний, а указанные введенные данные используют в базе знаний для обновления иных данных, чем те, которые требуются для перевода указанной первой информации.
8. Способ по одному из пп.1-7, характеризующийся тем, что он включает стадии
считывания первой информации, представленной в виде последовательности символов первого языка,
перевода первой информации, представленной в виде последовательности символов указанного первого языка, на основе данных базы знаний в первую информацию, представленную в виде последовательности символов второго языка, в объеме, заданном имеющимися в базе знаний данными,
определения дополнительных данных, требуемых для завершения перевода первой информации, представленной в виде последовательности символов первого языка, в первую информацию в виде последовательности символов второго языка,
ввода указанных дополнительных данных в базу знаний для ее обновления,
завершения перевода первой информации, представленной в виде последовательности символов первого языка, в первую информацию, представленную в виде последовательности символов второго языка,
сохранения указанной первой информации, представленной на втором языке,
считывания второй информации, представленной в виде последовательности символов первого языка,
перевода второй информации, представленной в виде последовательности символов указанного первого языка, во вторую информацию, представленную в виде последовательности символов второго языка, на основе указанных обновленных данных базы знаний.
9. Устройство для перевода информации, представленной в виде последовательности символов первого языка, в последовательность символов второго языка, содержащее
средства базы знаний (20, 25) для хранения шаблонных сегментов в виде последовательностей символов первого языка и, в логической связи с ними, эквивалентных сегментов в виде последовательностей символов второго языка,
средства (20, 24) для разделения информации, представленной в виде последовательности символов указанного первого языка, на структурные сегменты,
средства (20, 25) для сравнения указанного структурного сегмента с шаблонными сегментами, сохраненными в виде последовательностей символов первого языка,
средства (20) для выбора одного шаблонного сегмента по наибольшему сходству со структурным сегментом на основе указанного сравнения,
средства (20, 25) для считывания шаблонного, то есть эквивалентного, сегмента, логически связанного с выбранным шаблонным сегментом в указанной базе знаний, в виде последовательности символов второго языка и
средства (20, 24) для перевода указанного структурного сегмента в сегмент перевода, отображающий подлежащую представлению на указанном втором языке информацию, в виде последовательности символов второго языка с использованием указанного эквивалентного сегмента,
характеризующееся тем, что указанные средства (20, 24) для разделения информации, представленной в виде последовательности символов первого языка, на структурные сегменты снабжены средствами для идентификации промежуточного слова и/или суффикса, причем указанное разделение основано, по существу, на указанной идентификации промежуточного слова и/или суффикса, которые образуют таким образом начало или конец структурного сегмента.
10. Устройство по п.9, характеризующееся тем, что оно снабжено средствами (20, 25) для формирования информации, подлежащей представлению в виде последовательности символов второго языка, на основе по крайней мере двух сегментов перевода.
11. Устройство по п.9 или 10, характеризующееся тем, что оно снабжено элементами (22, 23) интерфейса пользователя для подключения пользователя к указанным средствам базы знаний.
12. Устройство по п.11, характеризующееся тем, что элементы интерфейса пользователя подключены к указанным средствам базы знаний через сеть передачи данных.
13. Устройство по одному из пп.9-12, характеризующееся тем, что указанные средства базы знаний содержат средства первой базы знаний, доступные для индивидуальных пользователей, и средства второй базы знаний, доступные только для некоторых из указанных индивидуальных пользователей.
14. Устройство по одному из пп.9-13, характеризующееся тем, что указанные средства базы знаний содержат средства первой базы знаний, средства второй базы знаний, средства для данных, вводимых со средств интерфейса пользователя в указанные средства второй базы знаний, и средства для выборочной передачи данных, сохраненных в указанной второй базе знаний, в указанные средства первой базы знаний.

Текст
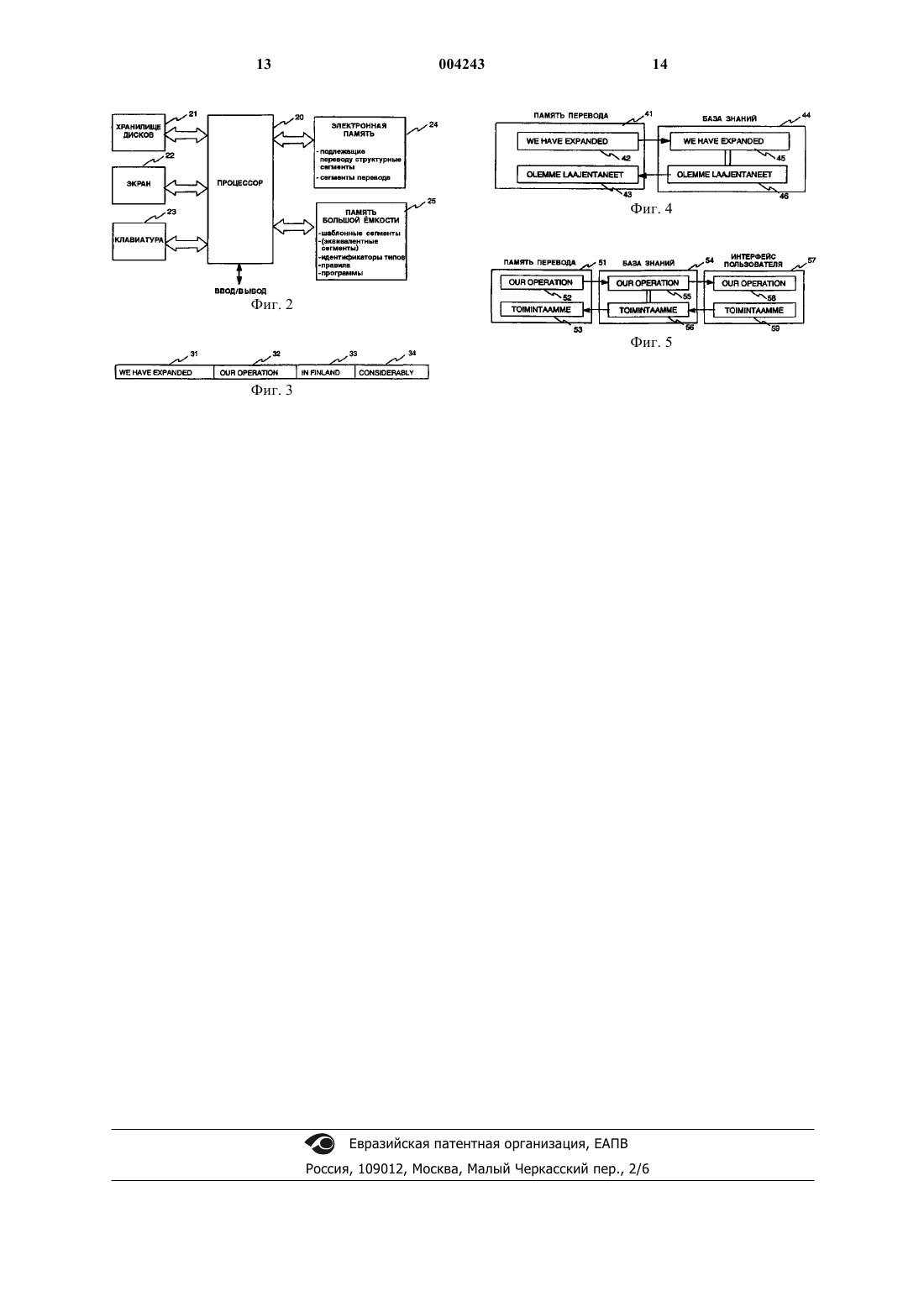
1 Изобретение относится к способу перевода информации, представленной в виде последовательности символов одного языка, в последовательность символов другого языка, а также к устройству для осуществления этого способа. Изобретение реализуется преимущественно при машинном переводе текстовой информации. Известны способы лингвистического машинного перевода текстовой информации. В этих способах синтаксис каждого языка полностью запрограммирован, поэтому каждый язык требует своего собственного программного алгоритма. Для хранения словарей различных языков используется централизованная память перевода большой емкости. В качестве примера такого способа может быть указана система перевода Европейского Союза, именуемая EuroTra. Подобные известные способы имеют ряд недостатков. Точное синтаксическое программирование требует большего числа программируемых операций. Такой синтаксический алгоритм, так же как и необходимость указанной памяти для перевода, требует большой области памяти в базе данных. Так как осуществляемый указанным образом способ перевода сложен,для выполнения перевода в течение приемлемого периода времени требуется компьютер очень большой мощности. Из-за этих недостатков пригодное для перевода оборудование является дорогим. Недостаток известных способов связан также с тем, что каждая корректировка алгоритма перевода требует модернизации компьютерной программы. Целью настоящего изобретения является создание способа перевода информации, который позволяет преодолеть недостатки, имеющиеся в вышеуказанном уровне техники. Идеей изобретения является разделение предназначенной для перевода информации на структурные сегменты и осуществление перевода по этим сегментам. Перевод выполняют на основе шаблонных сегментов и правил, хранящихся в базе знаний. Данные, содержащиеся в базе знаний, по преимуществу возрастают, так как всякий раз, когда это необходимо в процессе перевода, пользователь запрашивается через интерфейс пользователя о создании переводов новых структурных сегментов, и эти переводы запоминаются затем в базе знаний в качестве шаблонных сегментов. Благодаря решению по данному изобретению оборудование для перевода требует меньшего объема памяти и меньшего быстродействия процессора. Кроме того,программное обеспечение требуется в гораздо меньшем объеме, а функционирование оборудования может быть усовершенствовано без программного обновления. Предложенный в изобретении способ машинного перевода информации, представленной в виде последовательности символов на одном языке, в последовательность символов на другом языке включает в себя 2 сохранение в базе знаний шаблонных сегментов в виде последовательностей символов первого языка, а также в логической связи с ними шаблонных сегментов в виде последовательностей символов второго языка,разделение последовательности символов указанного первого языка на структурные сегменты,сравнение указанного структурного сегмента с сохраненными шаблонными сегментами в виде последовательностей символов первого языка,выполнение попытки выбора одного шаблонного сегмента по наибольшему сходству со структурным сегментом на основе указанного сравнения,считывание шаблонного, т.е. эквивалентного, сегмента, логически связанного с выбранным шаблонным сегментом, в виде последовательности символов второго языка и перевод указанного структурного сегмента в сегмент перевода в виде последовательности символов второго языка с использованием указанного эквивалентного сегмента, при этом заявленный способ включает в себя идентификацию промежуточного слова и/или суффикса, а указанное разделение последовательности символов на структурные сегменты основано, по существу, на идентификации указанных промежуточного слова и/или суффикса, которые образуют таким образом начало или конец структурного сегмента. Предложенное устройство для перевода информации, представленной в виде последовательности символов первого языка, в последовательность символов второго языка содержит средства базы знаний для хранения шаблонных сегментов в виде последовательностей символов первого языка и, в логической связи с ними,эквивалентных сегментов в виде последовательностей символов второго языка, средства для разделения информации, представленной в виде последовательности символов первого языка, на структурные сегменты, средства для сравнения указанного структурного сегмента с шаблонными сегментами, сохраненными в виде последовательностей символов первого языка,средства для выбора одного шаблонного сегмента по наибольшему сходству со структурным сегментом на основе указанного сравнения,средства для считывания шаблонного, то есть эквивалентного, сегмента, логически связанного с выбранным шаблонным сегментом в указанной базе знаний, в виде последовательности символов второго языка и средства для перевода указанного структурного сегмента в сегмент перевода, отображающий подлежащую представлению на указанном втором языке информацию, в виде последовательности символов второго языка с использованием указанного эквивалентного сегмента, причем указанные средства для разделения информации, представленной в виде последовательности символов 3 первого языка, на структурные сегменты снабжены средствами для идентификации промежуточного слова и/или суффикса, а указанное разделение основано, по существу, на указанной идентификации промежуточного слова и/или суффикса, которые образуют таким образом начало или конец структурного сегмента. Предпочтительные варианты осуществления изобретения описаны в зависимых пунктах формулы изобретения. Ниже следует более подробное описание изобретения со ссылкой на прилагаемые чертежи. На фиг. 1 представлена технологическая схема способа перевода информации в соответствии с изобретением; на фиг. 2 - блок-схема устройства для перевода информации в соответствии с изобретением; на фиг. 3 показана текстовая информация,разделенная на структурные сегменты; фиг. 4 иллюстрирует процесс перевода одного структурного сегмента с использованием сходного шаблонного сегмента, обнаруженного в базе знаний; фиг. 5 иллюстрирует процесс перевода структурного сегмента при отсутствии в базе знаний сходного шаблонного сегмента. На фиг. 1 изображена схема осуществления способа перевода информации в соответствии с изобретением. Подлежащая переводу информация сначала считывается на стадии 101 и разделяется на структурные сегменты на стадии 102 в соответствии с первым правилом. Затем на стадии 103 считывается первый непереведенный структурный сегмент. Прочитанный структурный сегмент сравнивается с шаблонными сегментами, хранящимися в базе знаний (стадии 104, 110). При этом сравнение выполняется в соответствии со вторым правилом, которое устанавливает, является ли шаблонный сегмент сходным с предназначенным для перевода структурным сегментом. Если в базе знаний найден шаблонный сегмент, близко соответствующий данному отдельному структурному сегменту, то на стадии 121 в базе знаний прочитывается шаблонный, т.е. эквивалентный сегмент второго языка, логически связанный со сходным шаблоном. После этого на стадии 122 в соответствии с третьим правилом из предназначенного для перевода структурного сегмента на основе прочитанного эквивалентного сегмента формируется переведенный на второй язык сегмент перевода. Затем на стадии 123 проверяется наличие оставшихся непереведенных структурных сегментов. Если еще имеются непереведенные структурные сегменты, процесс возвращается на стадию 103, где следующий непереведенный структурный сегмент прочитывается для его перевода. Если непереведенные структурные сегменты на стадии 123 отсутствуют, то сегменты перевода компонуются в предложения согласно четвертому правилу и переведенная информация затем сохраняется. 4 Далее переведенная информация на стадии 124 может быть отображена, например, на дисплее,распечатана на бумаге или сохранена на диске. Если шаблонный сегмент, сходный со структурным сегментом, не найден в базе знаний на стадии 110, то этот отдельный структурный сегмент на стадии 131 отображается интерфейсом пользователя, например, на экране дисплея. Затем на стадии 132 пользователь вводит перевод структурного сегмента, т.е. эквивалентный сегмент. На стадиях 133, 134 структурный и эквивалентный сегменты сохраняются в базе знаний в качестве шаблонных сегментов для последующего использования. После этого процесс переходит на стадию 123 для продолжения,как описано выше. В данном случае эквивалентный сегмент обычно является сразу сегментом перевода, если пользователь был запрошен о вводе перевода структурного сегмента в виде исходной информации, поэтому стадия 122 не является здесь необходимой. Указанное первое правило, с помощью которого идентифицируются структурные сегменты, может быть основано, например, на идентификации "промежуточных слов", или падежей. Промежуточные слова это, например, предлоги и частицы, образующие обычно стандартные последовательности символов, поэтому они могут быть идентифицированы путем простого сравнения последовательностей символов, образующих каждое слово, например, с указанными выше известными последовательностями символов, образующих промежуточное слово. Идентификация падежей может быть выполнена, например, с помощью суффиксов путем сравнения последних символов слова с известными суффиксами. Общеизвестно, что образующие слово последовательности символов могут быть разделены посредством пунктуации. Так как структурный сегмент может содержать, в основном, несколько слов, то он может включать в себя также один или более знаков препинания. В своем наиболее простом варианте указанное второе правило, с помощью которого структурный сегмент сравнивается с шаблонным сегментом, может быть аналогичным. В данном случае в базе знаний отыскивается точно такой же шаблонный сегмент, как подлежащий переводу имеющийся структурный сегмент. Однако, учитывая область памяти, требующуюся для базы знаний, при выполнении второго правила целесообразно не сохранять отдельно в базе знаний различные падежи, например, шаблонного сегмента, а идентифицировать также шаблонный сегмент, имеющий различный падеж. В данной ситуации эквивалентный сегмент, логически связанный с шаблонным сегментом, должен быть учтен в падеже,требуемом для формирования сегмента перевода. Это реализуется в соответствии с третьим правилом, которое поэтому в запросе содержит информацию о падежах языка. 5 Во многих случаях указанное четвертое правило, с помощью которого сегменты переводa формируются в переведенные предложения, заключается в размещении сегментов перевода в том же порядке, в каком находились предназначенные для перевода структурные сегменты первого языка. Этот порядок может зависеть еще и от языка, поэтому указанное четвертое правило ориентировано на конкретный язык. При сохранении шаблонных сегментов предпочтительно сохранять также идентификатор шаблонного сегмента. В данном случае идентификатор типа сохраняется в логической связи с каждым шаблонным сегментом. Если используются идентификаторы типа, то для идентификации и перевода структурного сегмента на основе шаблонного сегмента могут быть применены разные правила в зависимости от типа структурного сегмента. Типами структурных сегментов являются, например, дополнение, имя собственное, глагол, обстоятельство места, прилагательное или идиома. При переводе структурного сегмента с использованием идентификаторов типа пользователь также запрашивается об индикации типа, к которому относятся отдельный структурный сегмент и его перевод. Одной из идей изобретения является обновление базы знаний в интерактивно управляемом процессе перевода. Следует отметить,что обновление базы знаний не обязательно ограничивается сохранением новых шаблонных или эквивалентных сегментов; вышеуказанные правила преимущественно также могут обновляться. Это обновление осуществляется, например, в связи с переводом нового структурного сегмента, вводимого пользователем путем идентификации правильности исходного перевода. Выше был описан перевод порции информации с одного языка на другой. Предшествующее обновление базы данных используется преимущественно для перевода следующих порций информации. Таким образом, способ перевода двух последовательных порций информации в соответствии с изобретением может включать в себя следующие стадии: чтение первой информации, представленной в виде последовательности символов первого языка,перевод первой информации, представленной в виде последовательности символов указанного первого языка, на основе данных базы знаний в первую информацию, представленную в виде последовательности символов второго языка, в объеме, выполнимом в терминах данных, имеющихся в базе знаний,определение дополнительных данных, требуемых для завершения перевода первой информации, представленной в виде последовательности символов первого языка, в первую информацию, представленную в виде последовательности символов второго языка, 004243 6 ввод указанных дополнительных данных в базу знаний с целью ее обновления,завершение перевода первой информации,представленной в виде последовательности символов первого языка, в первую информацию, представленную в виде последовательности символов второго языка,сохранение указанной первой информации, представленной в виде последовательности символов второго языка,сохранение второй информации, представленной в виде последовательности символов первого языка,перевод второй информации, представленной в виде последовательности символов указанного первого языка, на основе указанных обновленных данных базы знаний во вторую информацию, представленную в виде последовательности символов второго языка. На фиг. 2 изображена блок-схема заявленного устройства для перевода информации. Устройство содержит хранилище 21 дисков,экран 22 индикатора и клавиатуру 23 в качестве средств сопряжения, подключенных к процессору 20. С помощью хранилища дисков подлежащая переводу информация может быть введена с диска в устройство, а переведенная информация может быть сохранена на диске для использования в других устройствах. Через шину ввода-вывода эта информация может также передаваться между данным устройством и другим оборудованием для обработки данных. Экран 22 индикатора может быть использован с целью отображения для пользователя тех структурных сегментов, перевод которых в базе знаний не найден. С клавиатуры 23 пользователь может вводить перевод такого структурного сегмента. Вышеуказанные средства сопряжения могут также применяться для проверки и исправления переведенной информации. Показанное на фиг. 2 устройство содержит также электронную память 24 для временного хранения структурных сегментов и сегментов перевода наряду с прочим. Кроме того, устройство содержит память 25 большой емкости для хранения базы знаний, т.е. шаблонных сегментов, идентификаторов типа и правил, а также программ. В качестве памяти большой емкости может быть использован, например, накопитель на жестком или оптическом диске. В качестве вышеуказанных компонентов могут быть применены известные компьютерные элементы, функционирующие согласно изобретению на основе специального программного обеспечения. Последовательности символов и другие данные передаются между этими элементами преимущественно в виде электрических сигналов. Осуществление изобретения не ограничено использованием вышеописанных компонентов. Наоборот, устройство в соответствии с изобретением может иметь много различных конфигу 7 раций, которые может спроектировать специалист в данной области техники. Фиг. 3 иллюстрирует английское предложение, разделенное на структурные сегменты 31, 32, 33 и 34. Как видно из фигуры, структурный сегмент содержит обычно последовательность непосредственно связанных слов в предложении. Поэтому структурный сегмент часто содержит также знак препинания, разделяющий слова. Фиг. 4 поясняет перевод первого структурного сегмента показанного на фиг. 3 предложения при помощи одного аспекта изобретения. Согласно фиг. 4 подлежащий переводу структурный сегмент 42 запоминается в памяти 41 перевода и сравнивается с шаблонными сегментами, хранящимися в базе знаний 44. В случае, показанном на фиг. 4, этот отдельный структурный сегмент был заранее сохранен в базе знаний в качестве шаблонного сегмента 45,который был найден в процессе сравнения. Если, например, данная информация должна быть переведена на финский язык, то в базе знаний прочитывается финский шаблонный сегмент 46,логически связанный с вышеуказанным английским шаблонным сегментом. На фиг. 4 логическая связь показана двойной линией, соединяющей шаблонные сегменты 45 и 46. По прочтении финского шаблонного сегмента он запоминается в памяти перевода как сегмент перевода. Фиг. 5 поясняет перевод показанного на фиг. 3 второго структурного сегмента с помощью аспекта изобретения. В данном случае ни подлежащий переводу английский структурный сегмент, ни какой-либо финский эквивалентный сегмент не сохранены заранее в базе знаний в качестве шаблонного сегмента. В данном случае подлежащий переводу структурный сегмент 52,запомненный в памяти перевода, сравнивается с шаблонными сегментами базы знаний и, если требуемый эквивалентный сегмент не найден в базе знаний, подлежащий переводу структурный сегмент 58 отображается на экране дисплея интерфейса 57. После этого пользователь через интерфейс вводит перевод 59 структурного сегмента 58 в базу 54 знаний. Этим способом в базе знаний английский и финский структурные сегменты сохраняются в их логической связи. Затем в памяти 51 перевода финский перевод структурного сегмента запоминается в качестве сегмента 53 перевода. В случае повторного появления вышеотмеченного структурного сегмента во входящей информации в базе знаний будут найдены соответствующие шаблонные и эквивалентные сегменты и не нужно будет запрашивать пользователя об их повторном вводе. Однако если в последующей входящей информации будет содержаться предложение "we have expanded ouroperation largely in Finland", то слово "largely" будет являться новым структурным сегментом. Если в базе знаний не сохранен заранее сходный 8 шаблонный сегмент, пользователю предлагается дать перевод этого нового сегмента, в базе знаний слово "largely" сохраняется в качестве шаблонного сегмента, а в логической связи с ним пользователь вводит также его исходный перевод. Следует отметить, что работа устройства может быть организована так, чтобы сначала процесс перевода был выполнен машиной для всей информации в объеме сохраненных в базе знаний шаблонных сегментов. После этого пользователь может ввести в базу знаний требуемые переводы новых структурных сегментов. Такой порядок имеет преимущество в том,что пользователь может не находиться за компьютером в ожидании завершения процесса перевода, а обновить базу знаний за один раз в какое-либо удобное время. Шаблонные сегменты могут сохраняться в базе знаний в виде отдельных пар для каждой пары языков. По-другому, можно логически связать шаблонные сегменты нескольких языков так, чтобы при переводе в нескольких парах языков можно было использовать одни и те же шаблонные сегменты. В этом случае шаблонные сегменты каждого языка можно вводить в базу знаний каждый раз, когда они для данного языка впервые появляются в запросе. Затем, когда в базу знаний вносится новая информация при переводе в одной паре языков, имеющаяся в базе знаний информация будет автоматически распространяться также и на другие пары языков. Решение по данному изобретению принципиально не ориентировано на конкретный язык и применимо для любой пары языков. Осуществление изобретения не ограничено также естественными языками, использующимися для обычной передачи информации, и может применяться для перевода любого состоящего из последовательностей символов языка в другой язык, состоящий из последовательности символов. В качестве примеров таких других языков можно назвать языки программирования и протоколы обмена данными. Решение по данному изобретению имеет много преимуществ перед известными решениями. Для разделения языковой информации на структурные сегменты требуется незначительный объем данных применительно к конкретному языку. Вторым преимуществом изобретения является накапливание дополнительной информации в памяти устройства в процессе его работы, вследствие чего устройство "узнает" новые пары шаблонных сегментов и правила. Таким образом, при простом составе оборудования и небольшом объеме программирования и его обновления можно обеспечить эффективное средство для машинного перевода. Решение по данному изобретению хорошо приспособлено для использования в ситуациях,где устройство по изобретению применяется для удовлетворения потребностей нескольких пользователей. В этом случае устройство содержит 9 преимущественно несколько интерфейсов, которые могут взаимодействовать с базой знаний,например, через сеть передачи данных. Кроме того, желательно, чтобы база знаний могла быть децентрализована таким образом, что ее первая,т.е. основная, часть могла быть использована определенной группой пользователей, а вторая часть, т.е. подбаза знаний, использовалась бы только несколькими пользователями из данной группы. Это позволяет разным пользователям обновлять их собственные базы знаний для специальных целей, например, со специальными словарями или выражениями, без использования таких баз знаний другими пользователями. В подобной децентрализованной базе знаний обновление ее первой основной части может выполняться из других частей, т.е. из подбаз знаний. Сохраненные в подбазах данные передаются затем в основную часть базы знаний на заранее заданных условиях. Одним из таких условий может быть область применения специальных данных. Обмен данными между базами знаний может также осуществляться при помощи одного общего главного администратора базы знаний, проверяющего каждые данные и санкционирующего их передачу. Выше было описано несколько примеров осуществления данного изобретения. В пределах объема защиты, определенного формулой изобретения, принцип изобретения может, конечно, варьироваться, например, в подробностях реализации и областях применения. ФОРМУЛА ИЗОБРЕТЕНИЯ 1. Способ машинного перевода информации, представленной в виде последовательности символов первого языка, в последовательность символов второго языка, включающий сохранение в базе знаний шаблонных сегментов в виде последовательностей символов указанного первого языка, а также в логической связи с ними шаблонных сегментов в виде последовательностей символов второго языка,разделение последовательности символов указанного первого языка на структурные сегменты (102),сравнение структурного сегмента с сохраненными шаблонными сегментами (104) в виде последовательностей символов первого языка,выполнение попытки выбора одного шаблонного сегмента (110) по наибольшему сходству со структурным сегментом на основе указанного сравнения,считывание шаблонного, т.е. эквивалентного, сегмента (121), логически связанного с выбранным шаблонным сегментом, в виде последовательности символов второго языка и перевод указанного структурного сегмента в сегмент перевода в виде последовательности символов второго языка с использованием указанного эквивалентного сегмента (122), 004243 10 характеризующийся тем, что он включает идентификацию промежуточного слова и/или суффикса, а указанная стадия разделения последовательности символов на структурные сегменты основана, по существу, на идентификации указанных промежуточного слова и/или суффикса, которые образуют таким образом начало или конец структурного сегмента. 2. Способ по п.1, характеризующийся тем,что указанную информацию, подлежащую представлению в виде последовательности символов второго языка, получают путем сочетания сегментов перевода (124). 3. Способ по п.1 или 2, характеризующийся тем, что, когда в результате сравнения структурных сегментов шаблонный сегмент, подлежащий выбору, не найден, структурный сегмент отображают при помощи интерфейса пользователя, а эквивалентный сегмент отображенного структурного сегмента сохраняют в базе знаний посредством интерфейса пользователя. 4. Способ по одному из пп.1-3, характеризующийся тем, что указанный структурный сегмент содержит знак препинания. 5. Способ по одному из пп.1-4, характеризующийся тем, что в логической связи с шаблонным сегментом сохраняют идентификатор типа шаблонного сегмента. 6. Способ по одному из пп.1-5, характеризующийся тем, что логически связывают друг с другом более двух шаблонных сегментов разных языков. 7. Способ по одному из пп.1-6, характеризующийся тем, что при переводе первой информации через интерфейс пользователя вводят данные для обновления базы знаний, а указанные введенные данные используют в базе знаний для обновления иных данных, чем те, которые требуются для перевода указанной первой информации. 8. Способ по одному из пп.1-7, характеризующийся тем, что он включает стадии считывания первой информации, представленной в виде последовательности символов первого языка,перевода первой информации, представленной в виде последовательности символов указанного первого языка, на основе данных базы знаний в первую информацию, представленную в виде последовательности символов второго языка, в объеме, заданном имеющимися в базе знаний данными,определения дополнительных данных,требуемых для завершения перевода первой информации, представленной в виде последовательности символов первого языка, в первую информацию в виде последовательности символов второго языка,ввода указанных дополнительных данных в базу знаний для ее обновления,завершения перевода первой информации,представленной в виде последовательности 11 символов первого языка, в первую информацию, представленную в виде последовательности символов второго языка,сохранения указанной первой информации, представленной на втором языке,считывания второй информации, представленной в виде последовательности символов первого языка,перевода второй информации, представленной в виде последовательности символов указанного первого языка, во вторую информацию, представленную в виде последовательности символов второго языка, на основе указанных обновленных данных базы знаний. 9. Устройство для перевода информации,представленной в виде последовательности символов первого языка, в последовательность символов второго языка, содержащее средства базы знаний (20, 25) для хранения шаблонных сегментов в виде последовательностей символов первого языка и, в логической связи с ними, эквивалентных сегментов в виде последовательностей символов второго языка,средства (20, 24) для разделения информации, представленной в виде последовательности символов указанного первого языка, на структурные сегменты,средства (20, 25) для сравнения указанного структурного сегмента с шаблонными сегментами, сохраненными в виде последовательностей символов первого языка,средства (20) для выбора одного шаблонного сегмента по наибольшему сходству со структурным сегментом на основе указанного сравнения,средства (20, 25) для считывания шаблонного, то есть эквивалентного, сегмента, логически связанного с выбранным шаблонным сегментом в указанной базе знаний, в виде последовательности символов второго языка и средства (20, 24) для перевода указанного структурного сегмента в сегмент перевода, отображающий подлежащую представлению на указанном втором языке информацию, в виде последовательности символов второго языка с использованием указанного эквивалентного сегмента,характеризующееся тем, что указанные средства (20, 24) для разделения информации,представленной в виде последовательности символов первого языка, на структурные сегменты снабжены средствами для идентификации промежуточного слова и/или суффикса,причем указанное разделение основано, по существу, на указанной идентификации промежуточного слова и/или суффикса, которые образуют таким образом начало или конец структурного сегмента. 10. Устройство по п.9, характеризующееся тем, что оно снабжено средствами (20, 25) для формирования информации, подлежащей представлению в виде последовательности символов 12 второго языка, на основе по крайней мере двух сегментов перевода. 11. Устройство по п.9 или 10, характеризующееся тем, что оно снабжено элементами(22, 23) интерфейса пользователя для подключения пользователя к указанным средствам базы знаний. 12. Устройство по п.11, характеризующееся тем, что элементы интерфейса пользователя подключены к указанным средствам базы знаний через сеть передачи данных. 13. Устройство по одному из пп.9-12, характеризующееся тем, что указанные средства базы знаний содержат средства первой базы знаний, доступные для индивидуальных пользователей, и средства второй базы знаний, доступные только для некоторых из указанных индивидуальных пользователей. 14. Устройство по одному из пп.9-13, характеризующееся тем, что указанные средства базы знаний содержат средства первой базы знаний, средства второй базы знаний, средства для данных, вводимых со средств интерфейса пользователя в указанные средства второй базы знаний, и средства для выборочной передачи данных, сохраненных в указанной второй базе знаний, в указанные средства первой базы знаний.
МПК / Метки
МПК: G06F 17/28
Метки: способ, информации, способа, перевода, осуществления, этого, устройство
Код ссылки
<a href="https://eas.patents.su/8-4243-sposob-perevoda-informacii-i-ustrojjstvo-dlya-osushhestvleniya-etogo-sposoba.html" rel="bookmark" title="База патентов Евразийского Союза">Способ перевода информации и устройство для осуществления этого способа</a>
Способ очистки резервуара для хранения нефти и устройство для осуществления этого способа

Номер патента: 3659
Опубликовано: 28.08.2003
Автор: Уартел Майк
МПК: B08B 9/093
Метки: способа, этого, нефти, устройство, резервуара, способ, очистки, осуществления, хранения
Формула / Реферат:
1. Способ восстановления в состояние суспензии осадка (3), представляющего собой образованный вследствие оседания слой на дне резервуара (1) с плавающей крышей (2), снабженной множеством стержневых отверстий (4), распределенных равномерно по ее поверхности и позволяющих закрепить в ней стержни, способные удерживать крышу (2), опираясь на дно резервуара (1b), когда уровень сырой нефти в резервуаре (1) становится ниже длины (D) стержней, при...
Способ изготовления литьевой заготовки в вакуумной камере и устройство для осуществления этого способа.

Номер патента: 40
Опубликовано: 26.02.1998
Авторы: Реслер Йоахим, Кац Эдуард Лейбович, Контер Максим Лианович, Лубенец Владимир Платонович
МПК: B22D 27/04
Метки: способ, литьевой, камере, осуществления, устройство, заготовки, способа, вакуумной, изготовления, этого
Формула / Реферат:
1. Способ изготовления литьевой заготовки в вакуумной камере (2) путем подачи жидкого сплава в литейную форму и перемещения вместе с нею из нагреваемой камеры в охлаждающую камеру, где сплав направленно затвердевает, причем нагреваемая камера отделена от охлаждающей камеры экраном, в котором выполнено отверстие, отличающийся тем, что литейную форму под экраном (3) дополнительно охлаждают снаружи потоком газа. 2. Способ по п.1, отличающийся тем,...
Способ запирания и пломбирования объектов, содержащих детали с совмещающимися отверстиями, и контрольно-охранное устройство для осуществления этого способа

Номер патента: 193
Опубликовано: 24.12.1998
Автор: Ханинс Жан Борисович
МПК: G09F 3/03, E05B 39/02
Метки: запирания, способ, контрольно-охранное, устройство, совмещающимися, этого, объектов, содержащих, пломбирования, способа, детали, осуществления, отверстиями
Формула / Реферат:
1. Способ запирания и пломбирования объектов, содержащих детали с совмещающимися отверстиями, включающий установку стальной отожженной скобы в отверстия деталей с совмещающимися отверстиями, например дверных накладок, установку металлической пластины с двумя отверстиями на концы упомянутой скобы и закручивания концов скобы не менее чем на два витка, отличающийся тем, что, с целью повышения надежности и упрощения запирания, после установки...
Способ сушки листа целлюлозного материала при помощи горячего воздуха, перемещающегося в высоком вакууме, устройство для осуществления этого способа

Номер патента: 216
Опубликовано: 24.12.1998
Авторы: Маршал Поль, Леза Клод, Кьенс Эмманюэль, Лерве Жан
МПК: D21F 5/18
Метки: воздуха, листа, материала, этого, высоком, горячего, способа, способ, помощи, целлюлозного, сушки, перемещающегося, устройство, вакууме, осуществления
Формула / Реферат:
1. Способ обезвоживания целлюлозосодержащего листового материала, в частности влажного бумажного листа с массой от 10 до 80 г/м2 в высушенном состоянии и с исходной степенью сухости от 8 до 30%, получаемой, например, после обезвоживания на формующей сетке, заключающийся в закреплении листового материала на проницаемом полотне и пропускании через него, по крайней мере, одного потока горячего воздуха с высокой скоростью, отличающийся тем, что...
Способ двусторонней обработки бумажного полотна и каландр для осуществления этого способа

Номер патента: 317
Опубликовано: 29.04.1999
Авторы: Ротфусс Ульрих, Кайзер Франц, Ван Хааг Рольф
МПК: D21G 1/00
Метки: двусторонней, каландр, бумажного, способ, этого, способа, полотна, осуществления, обработки
Формула / Реферат:
1. Способ двухсторонней обработки бумажного полотна, преимущественно для производства бумаги для глубокой печати, с применением каландра путем пропускания бумажного полотна между жесткими и мягкими валками, часть из которых нагревают, причем крайние валки создают необходимое напряжение сжатия между валками, а, по меньшей мере, один из крайних валков выполнен с возможностью регулирования возникающего в нем прогиба, отличающийся тем, что...
Предыдущий патент: Избирательное сжатие данных для цифровой изобразительной информации
Следующий патент: Новый стабильный кристалл производного тиазолидиндиона и способ его получения
Случайный патент: Способ приготовления гранулянта, содержащего активный при пероральном введении бета-лактамный антибиотик