Система автоматической идентификации языка для многоязычного оптического распознавания символов
Номер патента: 1689
Опубликовано: 25.06.2001
Авторы: Янг Дзун, Чой Кеннет Чан, Канунго Тапас, Пон Леонард К., Боксер Минди Р.










Формула / Реферат
1. Способ автоматического определения одного или более языков, сопоставляемых с текстом документа, включающий в себя этапы
сегментации документа на совокупность словоформ,
формирования, по крайней мере, одной гипотезы относительно символов в упомянутых словоформах,
задания словаря каждого из нескольких языков,
определения для упомянутой гипотезы слова показателей доверительности по упомянутым нескольким языкам, причем показатели определяют исходя из того, содержится ли данная гипотеза слова в соответствующих словарях,
задания в документе совокупности областей, каждая из которых содержит, по крайней мере, одно слово,
определения показателя доверительности по языку для каждой области, исходя из показателей доверительности, сопоставляемых со словами данной области, и
кластеризации областей, имеющих относительно высокие показатели доверительности по данному языку, с целью формирования подзоны, которую идентифицируют данным языком.
2. Способ по п.1, согласно которому гипотезу формируют только относительно слов, минимальная длина которых составляет, по крайней мере, два символа.
3. Способ по п.1, согласно которому упомянутые показатели доверительности для слов, относительно которых сформированы гипотезы, взвешиваются в соответствии с длинами слов, относительно которых сформированы гипотезы.
4. Способ по п.1, дополнительно включающий в себя этапы определения вероятности распознавания для каждой гипотезы и взвешивания упомянутых показателей доверительности в соответствии с вероятностями распознавания.
5. Способ по п.1, согласно которому упомянутые показатели доверительности для слов, относительно которых сформированы гипотезы, взвешивают в соответствии с частотами, с которыми слова, относительно которых сформированы гипотезы, встречаются в соответствующих языках.
6. Способ по п.1, согласно которому упомянутую первоначальную гипотезу формируют с помощью классификатора, который является общим по отношению к каждому из упомянутых нескольких языков.
7. Способ автоматической сегментации документа на однородные по языку подзоны, включающий в себя этапы
задания в документе, по крайней мере, одной зоны, которая содержит совокупность слов,
задания словаря каждого из нескольких языков,
определения для каждого слова данной зоны показателя доверительности по каждому из упомянутых нескольких языков, причем показатель определяют, исходя из того, содержится ли данное слово в соответствующих словарях,
идентификации зонального языка для данной зоны, исходя из показателей доверительности, сопоставляемых со словами данной зоны,
выбора в данной зоне локальной области, которая содержит, по крайней мере, одно слово,
идентификации областного языка для данной локальной области, исходя из показателя доверительности, сопоставляемого со словами данной области;
определения, совпадает ли областной язык с зональным языком, и
сегрегации данной локальной области от других областей данной зоны, если ее областной язык не совпадает с зональным языком.
8. Способ автоматического определения одного или нескольких языков, сопоставляемых с текстом документа, включающий в себя этапы
сегментации документа на совокупность зон, содержащих области, состоящие из словоформ,
формирования, по крайней мере, одной гипотезы относительно символов в упомянутых словоформах,
задания словаря каждого из нескольких языков,
для каждого слова, относительно которого сформирована гипотеза, определения, какие из упомянутых словарей содержат гипотезу слова, и определения значения доверительности каждому языку,
идентификации зонального языка для каждой зоны, исходя из значений доверительности, сопоставляемых со словами данной зоны,
идентификации областного языка для каждой области, исходя из значений доверительности, сопоставляемых словами данной области,
указания зонального языка в качестве областного языка, если значения доверительности, сопоставляемые со словами данной области, недостаточно высоки, и
кластеризации областей зоны, которые имеют один и тот же областной язык, с целью формирования подзоны, которая идентифицируется тем или иным языком.
9. Способ по п.8, согласно которому гипотезу формируют только относительно слов, для которых заранее определено минимальное количество символов, превышающее единицу.
10. Способ по п.8, дополнительно включающий в себя этап взвешивания упомянутых значений доверительности в соответствии с длинами слов, относительно которых сформированы гипотезы.
11. Способ по п.8, дополнительно включающий в себя этапы определения вероятности распознавания для каждой гипотезы и взвешивания упомянутых значений доверительности в соответствии с вероятностями распознавания.
12. Способ по п.8, согласно которому упомянутую первоначальную гипотезу формируют с помощью классификатора, который является общим по отношению к каждому из упомянутых нескольких языков.
13. Способ автоматического определения одного или нескольких языков, сопоставляемых с текстом документа, включающий в себя этапы
сегментации документа на совокупность словоформ,
формирования, по крайней мере, одной гипотезы относительно символов в упомянутых словоформах,
определения для каждой гипотезы слова показателя доверительности, который указывает, содержится ли данное слово в каждом из упомянутых нескольких языков,
задания в документе совокупности областей, каждая из которых содержит, по крайней мере, одно слово,
определения показателя доверительности по языку для каждой области, исходя из показателей доверительности, сопоставляемых со словами данной области, и
кластеризации областей, имеющих относительно высокие показатели доверительности по данному языку, с целью формирования подзоны, которую идентифицируют данным языком.
14. Способ автоматической сегментации документа на однородные по языку подзоны, включающий в себя этапы
задания в документе, по крайней мере, одной зоны, которая содержит совокупность слов,
определения для каждого слова данной зоны показателя доверительности, который указывает, содержится ли данное слово в каждом из упомянутых нескольких языков,
идентификации зонального языка для данной зоны, исходя из показателей доверительности, сопоставляемых со словами данной зоны,
выбора в данной зоне локальной области, которая содержит, по крайней мере, одно слово,
идентификации областного языка для данной локальной области, исходя из показателя доверительности, сопоставляемого со словами данной области,
определения, совпадает ли областной язык с зональным языком, и
сегрегации данной локальной области от других областей данной зоны, если ее областной язык не совпадает с зональным языком.

Текст
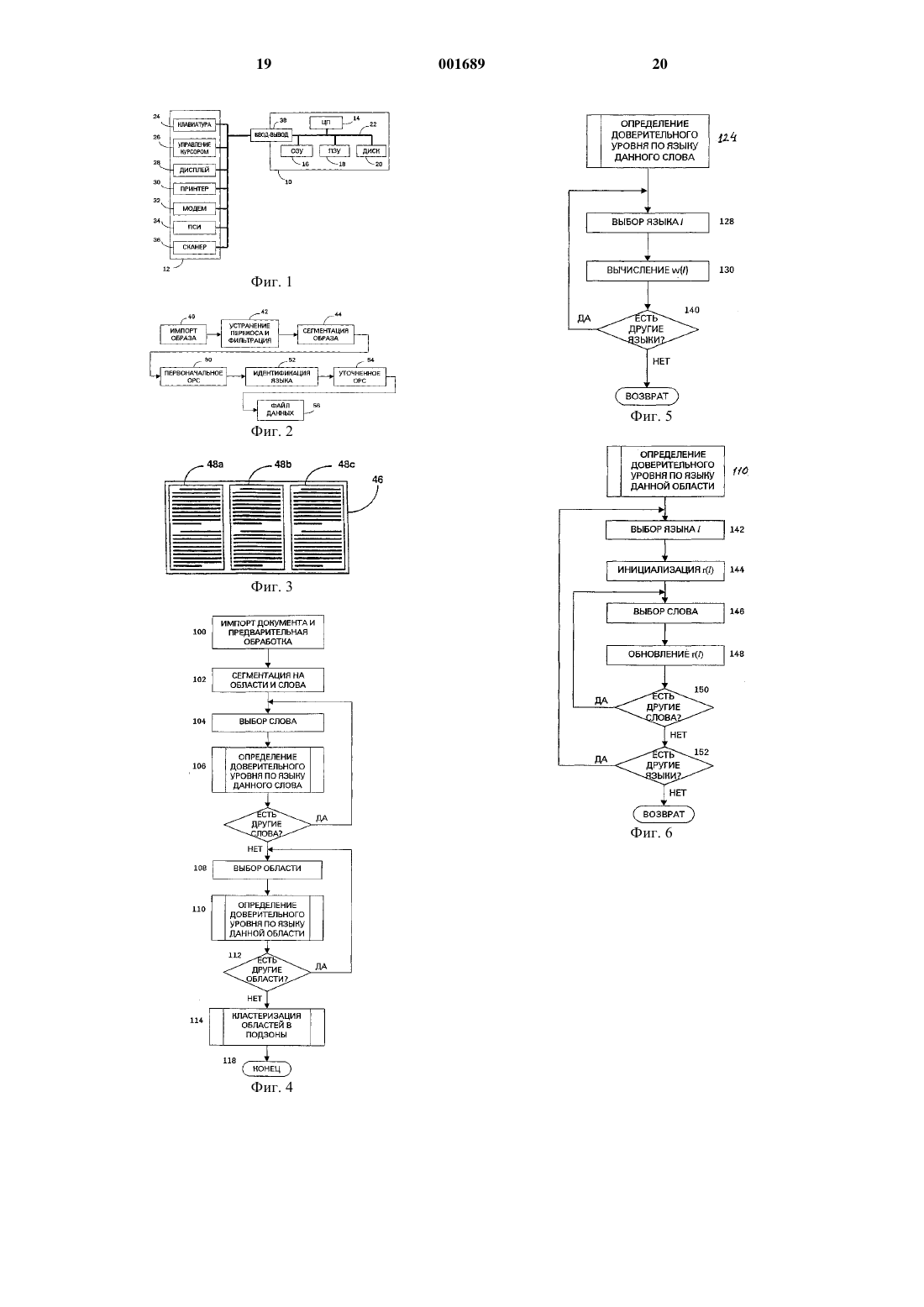
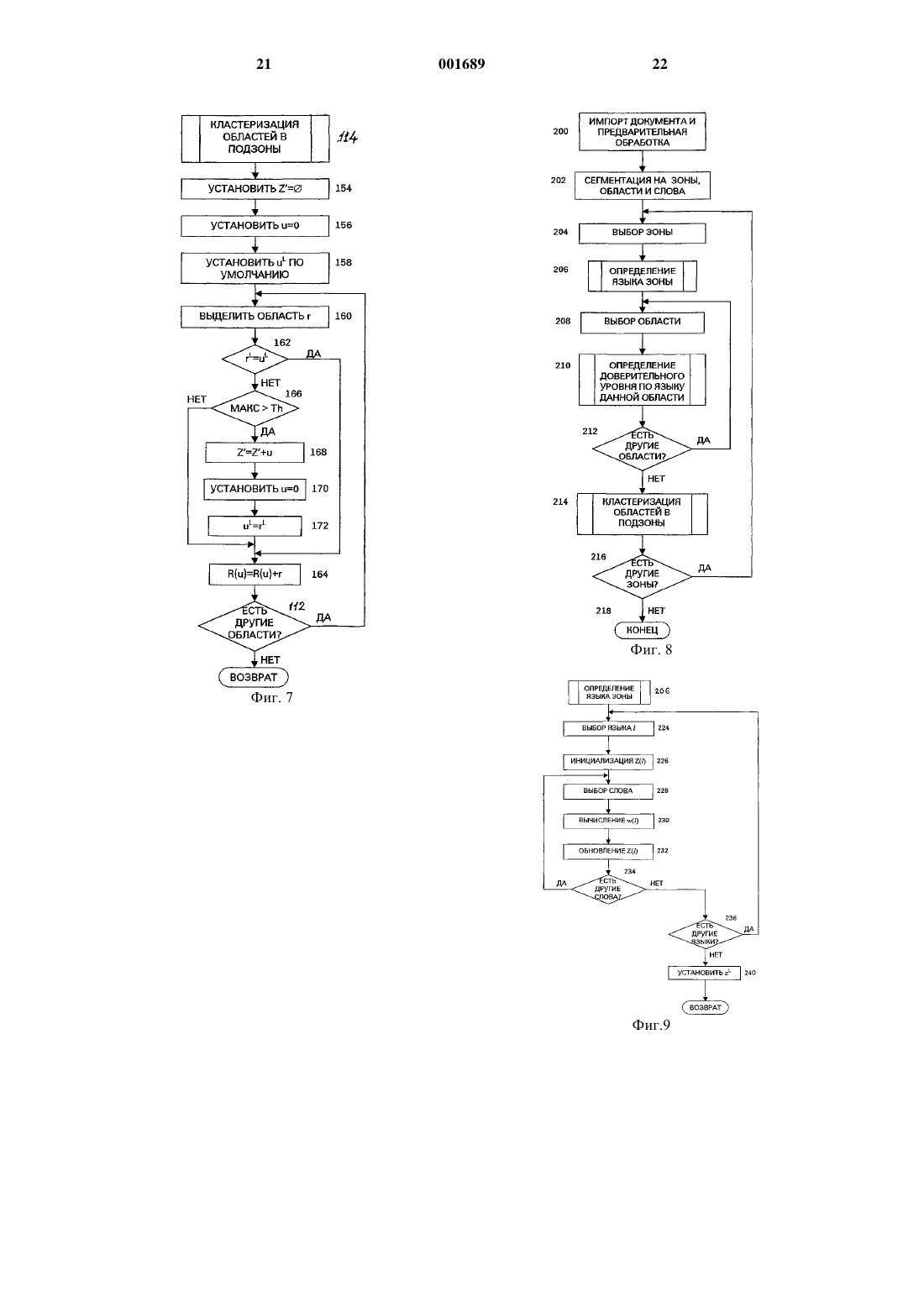
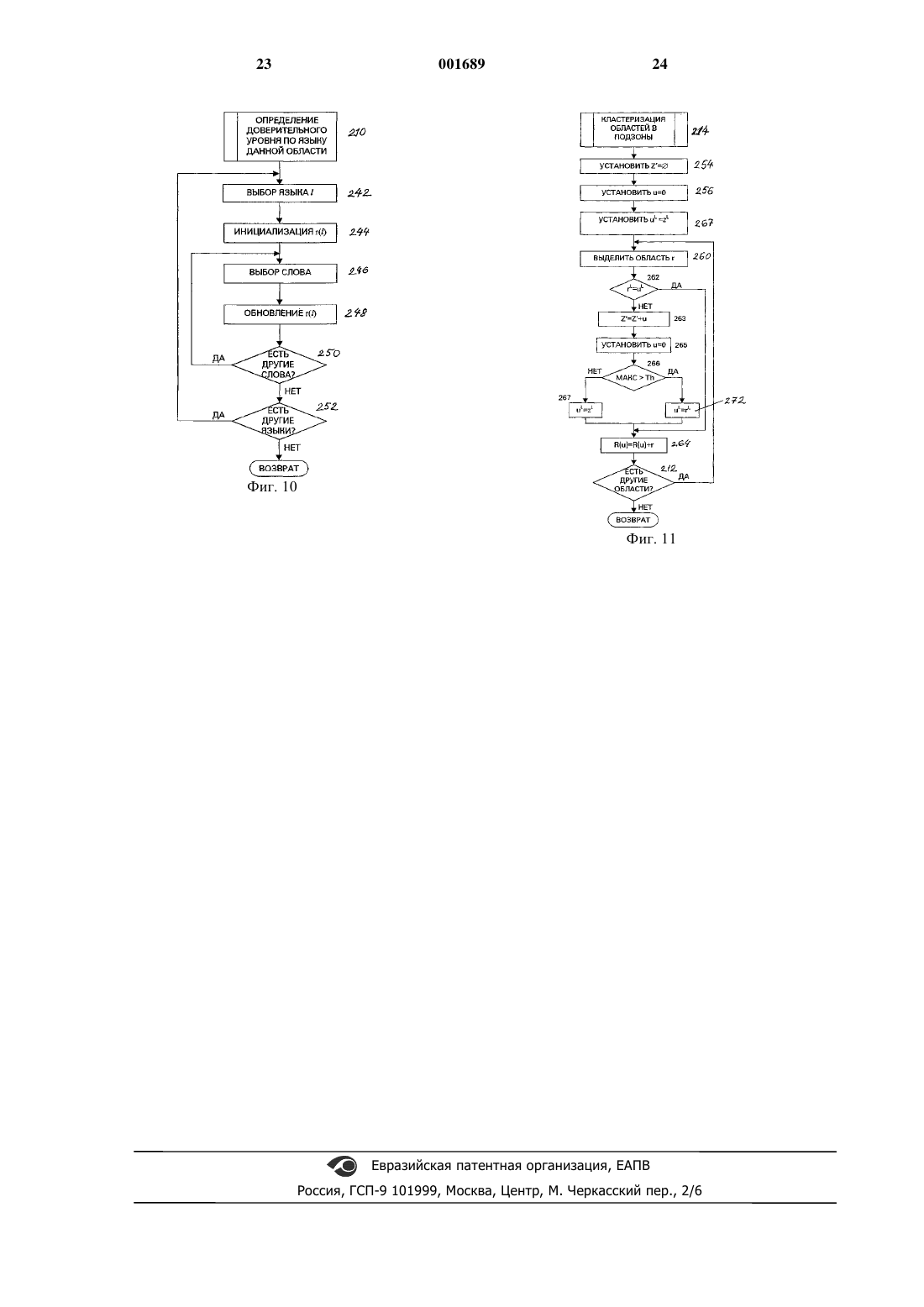
1 Область техники, к которой относится изобретение Настоящее изобретение, в общем случае,относится к различению языков, употребляемых при общении и, более конкретно, к автоматическому распознаванию различных языков в многоязычном документе в целях оптического распознавания символов и т.п. Уровень техники В целом, оптическое распознавание символов предполагает разбиение образа документа на отдельные знаки и группы знаков и сравнение образов знаков с шаблонной информацией,представляющей различные символы, например,буквы алфавита, цифры и т.п. Для повышения точности процесса распознавания, в подсистемах ОРС (оптического распознавания символов) применяются методики, которые базируются на особенностях того или иного языка. Например,языковую информацию можно использовать для выбора надлежащих классификаторов, словарей, вероятностей биграфных и триграфных символов, а также распознавания характерных для того или иного языка форматов дат, цифр и т.д. Раньше пользователю, применяющему систему ОРС, если она способна распознавать текст на разных языках, приходилось вручную задавать язык текста в сканируемом образе,чтобы система ОРС могла точно распознавать знаки и слова в образе документа. Применительно к одноязычному документу эта задача была относительно проста. Однако для оптимальной ОРС-обработки многоязычных страниц необходимо было разграничивать различные зоны, содержащие текст на том или ином языке,и идентифицировать каждую зону ярлыком правильного языка. Вследствие необходимости такого непосредственного вмешательства могут увеличиваться затраты труда, что приводит к удорожанию и значительному замедлению всего процесса преобразования образа в текст. По мере глобального нарастания деловой активности многоязычные документы становятся обычным явлением. Примерами таких документов могут служить руководства пользователя, предназначенные для многих стран и, по этой причине, содержащие на одной странице фрагменты текста на разных языках, а также туристические брошюры, предоставляющие сжатую информацию в ряде многоязычных схем. В такого рода документах однотипная информация может быть представлена на разных языках и размещаться в разных абзацах,колонках или на разных страницах. В качестве других примеров многоязычных документов могут выступать проспекты авиалиний, предоставляющие информацию для международных туристов и лиц, совершающих деловые поездки,международная деловая переписка, где шапка может быть выполнена на языке страны отправителя, а содержательная часть - на языке стра 001689 2 ны адресата, а также иммиграционные документы, содержащие инструкции на нескольких языках. Все это обусловливает растущую необходимость в автоматическом различении и идентификации различных языков в одном документе. Предшествующие разработки по автоматической идентификации языка строились на одном из двух общих подходов. Согласно одному подходу идентификация языка опирается на признаки, извлекаемые из образов словоформ. Варианты применения этого подхода описаны,например,в следующих публикациях: Т.Накаяма (Nakayama) и А.Л. Шпиц (Spitz) Определение европейских языков на основании образа ("European Language DeterminationFrom Image"), Труды международной конференции по анализу и распознаванию документов, Цукуба, Япония, 1993; П. Сибун (Sibun) и А. Л. Шпиц Определение языка: обработка естественного языка на основании сканированных образов документов ("Language Determination: Natural Language Processing From ScannedDocument Images"), Труды конференции по применению обработки естественного языка,Штутгарт, Германия, 1994; и А.Л. Шпиц Определение шрифта и языка на основании образов документов("Script And Language DeterminationFrom Document Images"), Труды симпозиума по анализу документов и извлечению информации,Лас-Вегас, Невада, 1994. Для того, чтобы идентификация с помощью методик, подобных тем,что описаны в этих ссылочных материалах, была достоверной, требуется значительный объем текста на определяемом языке. Если смена языка текста происходит с относительно большой частотой, например, от строки к строке, то получить статистические данные по признакам,которые позволяли бы отличить один язык от другого, не представляется возможным. Второй подход к идентификации языка основан на частотности слова и вероятности биграфа. Варианты применения этого подхода описаны в следующих публикациях: Х.С. Баирд(Ittner) Семейство устройств считывания страниц на европейских языках ("Family Of European Page Readers"), Труды международной конференции по распознаванию образов, Иерусалим, Израиль, 1994; и Д. Ли (Lee), К. Ноль (С.Nohl) и X. Баирд Идентификация языка в образах сложных, неориентированых и низкокачественных документов ("Language IdentificationIn Complex, And Degraded Document Images",Труды рабочей группы IAPR по системам анализа документов, Малверн, Пенсильвания,США, 1996. Этот подход применим лишь к таким документам, в которых каждая станица содержит текст на одном языке. Он не дает возможности различить два языка в пределах одной страницы, если не производить предварительной сегментации вручную. Кроме того, чтобы с 3 уверенностью получить вероятности переходов между языковыми моделями, к образам документов предъявляются относительно высокие требования по верности. Таким образом, существует необходимость в системе автоматического различения нескольких и идентификации языков, которая не требует предварительного ручного ввода и способна разделять образ на однородные по языку области, с целью уверенной идентификации различных языков, совокупно представленных на одной странице, и, тем самым, позволяет эффективно производить оптическое распознавание символов с более высокой скоростью и точностью. Сущность изобретения Для достижения вышеизложенных целей,настоящее изобретение предусматривает применение словарного подхода к разделению различных фрагментов документа на однородные по языку области. Разделение документа можно выполнять с использованием нисходящего подхода, восходящего подхода или смешанного подхода. Нисходящий подход предусматривает сегментацию образа документа на зоны и словоформы с использованием подходящих геометрических свойств. Внутри каждой зоны осуществляется сравнение словоформ со словарями, соответствующими каждому из различных языков-кандидатов, с целью определения показателя доверительности по каждому языку. Первоначально, с языком данной зоны идентифицируется язык, характеризующийся наивысшим показателем доверительности. Каждая зона разделяется на локальные области, каждая из которых может представлять собой одно слово или группировку слов, например, строку. Идентификация языка каждой локальной области осуществляется с использованием словарного показателя доверительности для слов этой области. После этого локальные области разделяются в соответствии с языком, который сопоставляется каждой из них. Восходящий подход предусматривает разбиение образа документа на отдельные словоформы, для каждой из которых определяется показатель доверительности по каждому языкукандидату. Образ документа делится на локальные области, каждая из которых, опять же, может представлять собой одно слово или группировку слов, например, строку. Идентификация языка для каждой локальной области осуществляется с использованием словарного показателя доверительности для слов этой области. После этого локальные области, имеющие общий язык,группируются в соответствии с языком, который сопоставляется каждой из них, с целью формирования однородных по языку областей. Смешанный подход предусматривает,прежде всего, сегментацию образа документа на одну или несколько зон, и идентификацию языка для каждой зоны. После этого реализуется 4 восходящий подход, в соответствии с которым зональный язык применяется при определении группировок локальных областей с целью формирования однородных по языку областей. Дополнительные признаки изобретения и обеспечиваемые ими преимущества подробно описаны со ссылкой на иллюстративные варианты реализации, представленные на прилагаемых чертежах. Краткое описание чертежей Фиг.1 представляет собой блок-схему компьютерной системы, которая предусматривает применение настоящего изобретения,Фиг. 2 представляет собой блок-схему, иллюстрирующую основные этапы оптического распознавания символов документа,Фиг.3 представляет собой схематическое изображение многоязычного документа,Фиг.4 представляет собой блок-схему алгоритма всего процесса согласно первому варианту реализации настоящего изобретения,Фиг. 5 представляет собой блок-схему алгоритма выполнения подпрограммы определения статистики доверительности по языку слова,Фиг. 6 представляет собой блок-схему алгоритма выполнения подпрограммы определения статистики доверительности по языку области,Фиг. 7 представляет собой блок-схему алгоритма выполнения подпрограммы кластеризации областей в подзоны,Фиг. 8 представляет собой блок-схему алгоритма всего процесса согласно второму варианту реализации настоящего изобретения,Фиг. 9 представляет собой блок-схему алгоритма выполнения подпрограммы определения зонального языка,Фиг.10 представляет собой блок-схему алгоритма выполнения подпрограммы определения областного языка,Фиг.11 представляет собой блок-схему алгоритма выполнения подпрограммы сегрегации областей по подзонам. Подробное описание вариантов реализации настоящего изобретения Для облегчения понимания настоящего изобретения ниже приведен частный случай оптического распознавания символов страницы документа, содержащей текст на нескольких языках. Хотя настоящее изобретение особенно подходит для такого применения, следует учитывать, что оно не ограничивается этим отдельным случаем использования. Напротив, принципы, лежащие в основе изобретения, можно использовать в самых разных случаях, когда требуется различать и идентифицировать языки. Автоматическую идентификацию языков и, в целом, оптическое распознавание символов можно осуществлять на различных компьютерных системах. Хотя те или иные аппаратные компоненты компьютерной системы сами по 5 себе не являются предметом изобретения, ниже приведено их краткое описание, позволяющее лучше понять, как признаки изобретения должны сочетаться с компонентами компьютерной системы, чтобы достичь желаемых результатов. Согласно фиг.1 иллюстративная компьютерная система включает в себя компьютер 10, к которому подключена совокупность 12 внешних периферийных устройств. Компьютер 10 включает в себя центральный процессор (ЦП) 14 и соответствующую память. Эта память, в общем случае, включает в себя основную или оперативную память, обычно выполненную в виде оперативного запоминающего устройства 16,статическую память, которая может представлять собой постоянное запоминающее устройство IS, и накопительное устройство, например,магнитный или оптический диск 20. ЦП сообщается с каждым из этих видов памяти через внутреннюю шину 22. Периферийные устройства 12 включают в себя устройство ввода данных, например, клавиатуру 24 и устройство 26 позиционирования или управления курсором,например, мышь, перо и т.п. Дисплейное устройство 28, например, монитор с ЭЛТ (электронно-лучевой трубкой) или экран ЖКД (жидкокристаллического дисплея) обеспечивает визуальное отображение информации, обрабатываемой компьютером, например, образ документа, на котором производится оптическое распознавание символов. Принтер 30 или аналогичное устройство может выдавать твердую копию информации. Связь с другими компьютерами может осуществляться с помощью модема 32 и/или платы сетевого интерфейса 34. Для преобразования твердой копии документа в электронный формат, подлежащий хранению,манипулированию и обработке на компьютере,можно использовать сканер 36. Каждое из этих внешних периферийных устройств обменивается данными с ЦП 14 посредством одного или нескольких портов ввода-вывода 38, установленных на компьютере. В ходе работы пользователь может сканировать документ с помощью сканера 36, в результате чего файл данных, который описывает образ документа, сохраняется в основной памяти 16. Сканированный документ может также отображаться на мониторе 28. В то время, когда содержимое файла образа хранится в основной памяти 16, над ним может осуществляться ОРСобработка с целью извлечения символьных данных для текстуального фрагмента образа. В результате оптического распознавания символов создается отдельный файл данных, например,файл ASCII. Оба файла - образа и символьных данных, либо один из них можно направить на хранение в накопительное устройство 20 и/или передать на другой компьютер через модем 32 или сеть. На фиг. 2 представлены основные этапы,осуществляемые ЦП компьютера в ходе типич 001689 6 ного процесса оптического распознавания символов. Согласно фигуре, на начальном этапе 40 образ документа импортируется в компьютер,например, с помощью сканера 36 или путем загрузки через коммуникационную сеть. На этапе 42 необязательной предварительной обработки образ документа корректируется с целью устранения перекоса и фильтруется тем или иным способом с целью удаления артефактов,которые могут создавать помехи для программы распознавания символов. Например, если в результате неисправности сканера возникает вертикальная линия, проходящая по всему образу,эту линию можно обнаружить и надлежащим образом удалить перед дальнейшей обработкой. После этого на этапе 44 производится сегментация образа документа на некоторое количество зон. Пример такой сегментации приведен на фиг. 3. В примере, представленном на этой фигуре, страница 46 содержит три колонки текста,каждая из которых состоит из двух абзацев. Если документ представляет собой многоязычное руководство пользователя, то, например, каждый столбец или каждый абзац в отдельности может содержать текст на отдельном языке. В результате сегментации образа документ может быть разделен на три зоны 48 а, 48b и 48 с, которые соответствуют трем колонкам. В зависимости от необходимой степени точности, документ может быть подвергнут более тонкому разделению на меньшие зоны. Например, отдельную зону может составлять каждый абзац или даже каждая строка или полустрока. В общем, зоной может быть любой фрагмент документа, содержащий две или более словоформы. Этапы предварительной обработки для коррекции перекоса и удаления артефактов, как и сегментации документа можно осуществлять в соответствии с любой из разнообразных общеизвестных методик. Примеры таких методик описаны в работе Л. О'Гормана (О'German) и Р. Кастури (Kasturi), Анализ образа документаPress, 1995, в частности, в главе 4, содержание которой используется здесь для ссылки. Когда документ поделен на сегменты, производится идентификация отдельных словоформ, т.е. группировок символьных знаков, в отношении которых можно предположить, что они образуют отдельные слова, опять же с использованием общепринятых методик оптического распознавания символов. На этапе 50 для каждой словоформы с использованием классификатора знаков генерируется одна или несколько гипотез относительно возможных символьных последовательностей, которые составляют словоформу. Подробную информацию по подобным классификаторам и работе с ними можно найти в работе Дуды (Duda) и Харта 7 первоначального ОРС является оценка символов в каждой из отдельных словоформ. Каждой оценке слова или гипотезе можно сопоставить вероятность распознавания, которая указывает степень правдоподобия правильности оценки по отношению к другим оценкам слова одной и той же словоформы. В общем случае, при оптическом распознавании символов применяется классификатор,который распознает шаблоны или знаки, которые соответствуют символам алфавита, цифрам,знакам препинания и т.д. Когда конкретный язык обрабатываемого документа известен,классификатор можно настроить на этот язык. Однако пример, представленный на фиг. 3, предусматривает наличие нескольких языков, причем, каких именно, заранее неизвестно. В этом случае предпочтительно, чтобы классификатор символов, используемый для создания первоначальной гипотезы слова, был общим для всех языков-кандидатов, подлежащих распознаванию. Например, если методика оптического распознавания символов рассчитана на идентификацию и различение романских языков, общий классификатор знаков можно настроить на распознавание всех или большинства знаков,используемых в этих языках. В качестве альтернативы использованию общего классификатора,возможно применение классификатора, приспособленного к одному конкретному языку, но при этом он должен обладать возможностями дополнительной обработки для распознавания знаков, которых может не оказаться в данном языке. После осуществления первоначальной оценки слов, на этапе 52 производится идентификация языка, сопоставляемого с текстом в каждой из зон, которая более подробно описана ниже. Это позволяет производить на следующем этапе 54 более активное оптическое распознавание символов, которое обеспечивает более высокую степень точности, с использованием классификаторов, предназначенных для каждого идентифицированного языка. Конечным продуктом этого процесса является файл данных 56, который представляет отдельные символы текста в исходном образе, например файл ASCII. В целом, настоящее изобретение предусматривает применение словарного подхода,который состоит в том, что словарь слов, найденных в том или ином языке, используется для идентификации текста на этом языке. Для каждого языка-кандидата, подлежащего идентификации, назначается словарь слов этого языка. Таким образом, например, если нужно идентифицировать языки, в основе которых лежат латинские алфавиты, можно назначить словарь каждого из следующих языков: американский английский, британский английский, французский, итальянский, немецкий, шведский, норвежский, финский, датский, португальский, бра 001689 8 зильский португальский, испанский и голландский. Каждый словарь может представлять собой либо элементарный словарь, содержавший только наиболее употребительные слова данного языка, либо полный словарь, который содержит более полное множество слов языка. Словарь может также содержать статистическую информацию о словах, например, частоту, с которой они обычно встречаются в языке. В качестве альтернативы использованию отдельного словаря для каждого языка-кандидата, возможно применение единого словаря, который содержит все слова различных языков-кандидатов. В этом случае каждая статья словаря возвращает данные, указывающие языки, в которых встречается это слово. Согласно одному варианту реализации изобретения для каждой из зон 48 а-48 с документа вычисляют статистику доверительности по каждому языку-кандидату. Один достаточно простой вариант осуществления изобретения предусматривает вычисление статистики доверительности путем подсчета в зоне числа слов,обнаруженных в каждом из соответствующих словарей. Для вычисления статистики доверительности можно применять и другие, более сложные подходы, которые подробно описаны ниже. Выявляют язык с наивысшей статистикой доверительности и его используют в качестве первоначальной оценки языка зоны. В зависимости от степени детализации при осуществлении сегментации может случиться так, что не каждая зона содержит один единственный язык. На примере документа, изображенного на фиг. 3, можно представить, что каждый из двух абзацев в каждой из зон 48 а-48 с набран на отдельном языке. Поэтому, после первоначальной идентификации зонального языка, каждую зону дополнительно расщепляют на локальные области. Локальная область может быть сколь угодно мала, вплоть до отдельной словоформы. Предпочтительно однако, чтобы локальная область состояла из логической группы слов, например,из одной или нескольких строк документа. Идентификацию языка каждой области осуществляют с использованием словарной статистики доверительности для данной области. Затем производят объединение следующих друг за другом областей с той же языковой характеристикой. Если в какой-либо области ни один из языков-кандидатов не имеет высокой языковой статистики доверительности, то в качестве областной языковой характеристики, принятой по умолчанию, используют зональный язык, сопоставленный с этой областью. Вышеописанную программу сегментации документа на однородные по языку области согласно настоящему изобретению могут осуществлять по-разному. Более подробно варианты реализации изобретения, в которых находят свое применение различные подходы, проиллю 9 стрированы блок-схемами алгоритма, изображенными на фиг. 4-11. Уместна следующая общая классификация этих различных подходов: восходящий подход, нисходящий подход и смешанный подход, сочетающий в себе концепции двух первых подходов. На фиг. 4 представлена вся процедура распознавания языка, отвечающая восходящему подходу. На этапе 100 документ сканируют, или образ документа тем или иным способом импортируют в оперативное запоминающее устройство 16 компьютера. Возможна также предварительная обработка образа документа, например, для коррекции перекоса с тем, чтобы строки текста были ориентированы в горизонтальном направлении, а также для того, чтобы тем или иным способом отфильтровать явные артефакты. На этапе 102,производят сегментацию образа документа на словоформы и локальные области на основании геометрических свойств образа с использованием общепринятых методик. Для облегчения понимания изобретения в нижеприведенном примере каждая локальная область документа представляет собой одну строку текста. Однако следует заметить, что локальная область может иметь сколь угодно малый размер, вплоть до отдельного слова. По завершении сегментации документа на слова и локальные области, выполняют подпрограмму 106, определяющую для каждого слова,выбранного на этапе 104, статистику доверительности по языку. Затем на этапе 108 выбирают первую область, после чего выполняют еще одну подпрограмму 110, которая определяет для данной области статистику доверительности по языку. На этапе 112 производят проверку, остались ли в документе области, не прошедшие обработку, и, если да, то этапы 108 и 110 повторяют до тех пор, пока статистика доверительности по языку не будет определена для всех областей. По завершении определения статистики доверительности для каждой области, подпрограммой 114 осуществляют кластеризацию соседних областей, например, следующих друг за другом строк, характеризующихся достаточно высокими доверительными уровнями по данному языку, в подзоны. После того,как все области прошли подобную обработку,процедуру оканчивают на этапе 118. Результатом этой процедуры является упорядоченное множество подзон, каждая из которых имеет однородную языковую характеристику. Выполняемая на этапе 106 подпрограмма определения статистики доверительности по языку для каждого слова иллюстрируется более подробной блок-схемой алгоритма, изображенной на фиг. 5. На этапе 124 выбирают первую словоформу в зоне и на этапе 128 выбирают первый язык-кандидат 1. На этапе 130 вычисляют статистику w(1), которая указывает степень доверительности того, что данное слово содержится в выбранном языке. Согласно одно 001689 10 му варианту реализации статистика может представлять собой просто единицу или нуль в зависимости от того, найдено ли данное слово в словаре данного языка. Можно также использовать другие, более изощренные подходы. Например,статистика доверительности w(l) для каждого слова может быть взвешена в соответствии с длиной слова. Этот подход особенно полезен для языков, в которых употребляются относительно длинные, уникальные слова, например,немецкого и норвежского. Для значения, вычисленного для каждого слова, можно также использовать весовой коэффициент, являющийся функцией вероятности распознавания, сопоставляемой с отдельными символами в словоформе, которые определяют по классификатору. При таком подходе оценки слов, имеющие относительно низкую вероятность распознавания,не оказывают на статистику доверительности по языку столь сильного влияния, как те, которые идентифицированы с большей определенностью. Помимо указания того, найдено ли данное слово в словаре, статистика доверительности может учитывать и другие показатели. Например, для взвешивания статистики доверительности может потребоваться использовать nграфную информацию или информацию по частотности слова, т.е. указывать, насколько правдоподобно, что последовательность символов в словоформе появляется в выбранном языке. На этапе 140 производят проверку, остались ли языки, не прошедшие обработку в отношении данного слова. Если да, то этапы 128 и 130 повторяются до тех пор, пока слово не будет сравнено со словарем каждого из языковкандидатов, и по каждому языку не будет вычислена статистика доверительности. После проверки всех языков и вычисления показателей доверительности выбирают следующее слово, и этапы 124-140 повторяют. После вычисления для каждого слова статистики доверительности по каждому языку-кандидату подпрограмму возвращают к основному процессу. Выполняемая на этапе 110 подпрограмма определения статистики доверительности по языку для данной области, подробно иллюстрируется блок-схемой алгоритма, изображенной на фиг. 6. Согласно этой фигуре на этапе 142 выбирают первый язык-кандидат l и на этапе 144 производят инициализацию, т.е. обнуление,статистики доверительности для области r(l). На этапе 146 выбирают первое слово в данной области, и на этапе 148 производят обновление показателя доверительности по выбранному языку r(1) для данной области. Например, показатель доверительности для области можно сохранять в сумматоре. Обновление показателя можно производить путем сложения статистики доверительности по языку данного слова w(l) со значением, хранящимся в накопителе. Затем процесс переходит к этапу 150, на котором производят проверку, остались ли в 11 области слова, не прошедшие обработку. Этапы 146 и 150 повторяются для каждого слова в области с целью получения статистики доверительности r(1), по отношению к словам в области, которые найдены в словаре выделенного языка 1. После проверки всех слов обновленное значение r(1) сохраняют в качестве показателя доверительности по выделенному языку в области. На этапе 152 производят проверку, остались ли языки, подлежащие обработке для зоны. Если да, то этапы 142-150 повторяют до тех пор,пока каждое слово в зоне не будет сравнено со словарем каждого языка-кандидата. Результатом этой процедуры является определение показателя доверительности r(1) по каждому языку для данной области. После проверки всех языков и определения всех показателей доверительности подпрограмму возвращают к основному процессу. Выполняемая на этапе 114 подпрограмма кластеризации областей в однородные по языку подзоны более подробно иллюстрируется блоксхемой алгоритма, изображенной на фиг. 7. На этапе 154 множество подзон Z' первоначально определяют как пустое множество или множество меры нуль. На этапе 156 значение временной переменной и для текущей подзоны также первоначально устанавливают равным нулю, и на этапе 158 язык текущей подзоны, uL, первоначально устанавливают равным любому языку,заданному по умолчанию. Затем, на этапе 160 выбирают первую область r и на этапе 162 производят проверку, указывают ли показатели доверительности по языку r(1) для данной области, что язык uL текущей подзоны, скорее всего,является языком области, rL. Другими словами,производят сравнение показателей доверительности по каждому из языков-кандидатов и проверку, является ли языковой показатель доверительности r(1) по языку текущей подзоны наивысшим или, по крайней мере, достаточно высоким по отношению к другим показателям доверительности для данной области. Если да, то на этапе 164 данную область r присоединяют к множеству областей R(u) текущей подзоны. Если язык текущей ползоны uL не является языком данной области, т.е. показатель доверительности r(1) по языку подзоны недостаточно высок по сравнению с другими показателями доверительности для рассматриваемой области,то на этапе 166 производят проверку, превышает ли наивысший показатель доверительностиr(l)max для данной области пороговое значениеTh. Если да, то можно начинать определение новой подзоны. Поэтому, на этапе 168 язык подзоны uL заменяют языком с наивысшей доверительностью для данной области. После этого на этапе 170 только что определенную подзону u присоединяют к множеству подзон Z', и на этапе 172 производят инициализацию переменной и текущей подзоны с целью начать определение новой подзоны. Затем на этапе 164 выбранную в 12 данный момент область r присоединяют к новой текущей подзоне. Если на этапе 166 выясняется, что наивысший показатель доверительности для области не превышает порогового значения, начинать определение новой подзоны не следует. Согласно варианту реализации, представленному на блок-схеме алгоритма, выбранную область присоединяют к множеству областей R(u) текущей подзоны. В альтернативном варианте присоединение этой области можно временно отложить,пока не будет проверена следующая область. Если показатели доверительности для следующей области указывают, что следует начать определение новой подзоны, то предыдущую область может повторно проверить на предмет того, не следует ли включить ее в новую подзону. Таким образом, на переходном участке между двумя подзонами можно применять программу упреждающей выборки, которая позволяет определить, язык какой из двух подзон наиболее близок к языку переходной области. На этапах 160-172 процедуру повторяют для каждой области r, пока не будет определено множество подзон Z'. Каждая подзона представляет собой одну или несколько следующих друг за другом областей, которые были идентифицированы как содержащие текст на одном и том же языке. Таким образом, в случае, когда каждая область является строкой текста, подзона представляет собой следующие друг за другом строки текста. Когда встречается следующая строка, имеющая другой язык, например, в начале нового абзаца, назначается новая подзона. В предыдущем варианте реализации изобретения при определении областного показателя доверительности по словарям соответствующих языков рассматривалась каждая словоформа, и все они имели равные весовые коэффициенты. В некоторых случаях, с целью повышения точности, может понадобиться более избирательно присваивать различным словам соответствующие значения. Например, словоформы,которые состоят только из одного символа,можно исключить из рассмотрения, учитывая тот факт, что они могут представлять скорее шум, чем значимую информацию. Восходящий подход, лежащий в основе рассмотренного выше варианта реализации,предусматривает, что анализ образа документа с целью сегрегации различных языковых областей начинают с наименьшего общего элемента,а именно, словоформы. Альтернативный, нисходящий подход предусматривает возможность первоначально назначать язык для более крупной зоны, а затем производить разделение на более мелкие однородные по языку области. На фиг. 8 изображена блок-схема алгоритма, представляющая весь процесс, отвечающий этому варианту реализации изобретения. Согласно фигуре, на этапе 200 образ документа импортируют в оперативное запоминающее устройство 13 16 компьютера и его опять же подвергают предварительной обработке с целью коррекции перекоса и отфильтровки явных артефактов. На этапе 202 производят сегментацию образа документа на зоны, области и словоформы, исходя из геометрических свойств образа. В примере,изображенном на фиг. 3, для определения отдельных зон можно легко идентифицировать три вертикальные колонки текста на основании широких белых полос, которые их разделяют. Внутри каждой колонки отдельные строки текста идентифицируют по горизонтальным полоскам белого цвета, которые разграничивают разные области. Аналогично, внутри каждой строки отдельные словоформы идентифицируют по относительно широким пробелам между символами. Хотя в примере, изображенном на фиг. 3,представлено несколько зон, вполне возможно,чтобы вся страница представляла собой одну зону. По завершении сегментации документа, на этапе 204 выбирают одну зону. Затем выполняют подпрограмму 206 определения языка для зоны. После этого на этапе 208 выбирают первую область и выполняют подпрограмму 210 определения статистики доверительности по языку для данной области. На этапе 212 производят проверку, остались ли в зоне области, не прошедшие обработку, и, если да, то этапы 208 и 210 повторяют до тех пор, пока будет определена статистика доверительности по языку для всех областей. После определения статистики доверительности для каждой области подпрограмма 214 отделяет области, имеющие сходные доверительные уровни по данному языку, от других областей, которые не сопоставляются с этим языком, с целью формирования однородных подзон. На этапе 216 производят проверку,остались ли зоны, не прошедшие обработку. Если да, то этапы 204-216 повторяют для каждой оставшейся зоны. После того, как все зоны прошли подобную обработку, процедуру заканчивают на этапе 218. Результатом этой процедуры является упорядоченное множество однородных по языку подзон в каждой зоне. Выполняемая на этапе 206 подпрограмма определения зонального языка более подробно иллюстрируется блок-схемой алгоритма, изображенной на фиг. 9. На этапе 224 выбирают первый язык-кандидат l, и на этапе 226 производят инициализацию статистики по данному языку z(l). На этапе 228 выбирают первое слово в зоне и на этапе 230 производят вычисления статистики доверительности для данного словаw(l), зависящей от того, удалось ли найти в словаре данного языка 1 последовательность символов в этой словоформе. Затем на этапе 232 производят обновление языковой статистикиz(l) в соответствии с выявленным значением доверительности. Например, языковую статистику z(l) можно получить суммированием отдельных значений доверительности w(l) для 14 слов зоны по данному языку. Затем процесс переходит к этапу 234 с целью проверки, остались ли в зоне слова, не прошедшие обработку. Этапы 228-232 повторяют для каждого слова зоны, пока не будет получено окончательное значение z(l) по данному языку. В относительно простом варианте осуществления, статистика может быть получена подсчетом в зоне числа слов, найденных в словаре данного языкаl. После обработки всех слов на этапе 236 производят проверку, остались ли языки, не прошедшие обработку для данной зоны. Если да, то этапы 224-234 повторяют до тех пор, пока каждое из слов в зоне не будет сравнено со словарем каждого из языков-кандидатов. По окончании подобной проверки языков, на этапе 240 производят выбор зонального языка ZL, исходя из языковой статистики z(l), которая представляет собой наивысшее значение доверительности. В простом варианте осуществления, описанном выше, язык, имеющий наивысшую частотность слов в данной зоне, т.е. язык, словарь которого генерирует наивысший счет, окончательно выбирают в качестве зонального языкаZL для этой зоны. По завершении проверки всех языков и идентификации зонального языка подпрограмму возвращают к основному процессу. Выполняемая на этапе 210 подпрограмма определения областного языка подробно иллюстрируется блок-схемой алгоритма, изображенной на фиг. 10. Согласно фигуре, на этапе 242 областной язык rL первоначально устанавливают равным ранее определенному зональному языку zL. Затем в процедуре, аналогичной той,что выполняют на этапах 224-236 блок-схемы алгоритма, изображенной на фиг. 9, каждое слово области проверяют на предмет определения его значения доверительности r(l) по выбранному языку l. После того, как определено значение доверительности для каждой области, процесс возвращают к основной программе. После этого подпрограммой 214 осуществляют сегрегацию областей по однородным по языку подзонам. Этот процесс может проходить, например, аналогично процедуре кластеризации, представленной блок-схемой алгоритма, изображенной на фиг. 7. Однако согласно данному варианту реализации при определении подзон используют зональный язык zL. Это различие явствует из фиг. 11. Согласно фигуре, если на этапе 266 выясняют, что значение доверительности r(l) для области недостаточно велико, чтобы обуславливать переход к новой подзоне, то на этапе 267 подзональный язык uL для новой подзоны по умолчанию устанавливают равным зональному языку zL. Другими словами, в случае неопределенности относительно превалирующего языка области, делают предположение, что это преобладающий язык зоны, в которой находится данная область, и ее группируют в подзону, сопоставляемую с этим языком. Таким образом, пер 15 воначальное определение зонального языка позволяет применять в процессе кластеризации более консервативный критерий в отношении того, следует ли переходить к другой подзоне,столкнувшись с низким значением доверительности. Третий вариант реализации изобретения,основанный на применении смешанного подхода, предусматривает использование отдельных методик, осуществляемых в каждом из первых двух вариантах реализации. В частности, согласно этому варианту реализации, сначала определяют зональный язык для каждой зоны документа, как предписывает нисходящий подход. После этого процесс осуществляют согласно восходящему подходу, определяя показатель доверительности для каждого слова, а затем областной язык для каждой области. В этом случае, как и в нисходящем подходе, можно использовать зональный язык, чтобы способствовать кластеризации областей в подзоны. Любому специалисту должно быть ясно,что настоящее изобретение можно реализовать в других конкретных формах, выходя за рамки его сущности или характерных особенностей. Например, в конкретных вариантах осуществления, которые иллюстрируются прилагаемыми блок-схемами алгоритма, статистику доверительности вычисляют для каждого слова зоны по каждому из языков-кандидатов. После этого все вычисленные доверительные уровни используются для определения зонального языка и областного языка. Однако оптимальный вариант осуществления не предусматривает необходимости вычисления статистики доверительности для каждого слова или по каждому языку. Напротив, если статистика доверительности по одному языку достаточно высока, чтобы уверенно определить, что для данного слова идентифицирован правильный язык, то на этом вычисление можно закончить, не вычисляя значения доверительности по каким-либо другим языкам. Аналогично, если достаточное количество слов в зоне или области определены как слова одного и того же языка, то для выбора языка данной зоны или области уже не требуется проверять каждое из оставшихся слов. По этой причине вышеописанные варианты реализации следует рассматривать исключительно как иллюстративные, но не ограничительные. Объем изобретения определяется прилагаемой формулой изобретения, но не вышеприведенным описанием, и охватывает все изменения,находящиеся в рамках ее значения и диапазона эквивалентности. ФОРМУЛА ИЗОБРЕТЕНИЯ 1. Способ автоматического определения одного или более языков, сопоставляемых с текстом документа, включающий в себя этапы 16 сегментации документа на совокупность словоформ,формирования, по крайней мере, одной гипотезы относительно символов в упомянутых словоформах,задания словаря каждого из нескольких языков,определения для упомянутой гипотезы слова показателей доверительности по упомянутым нескольким языкам, причем показатели определяют, исходя из того, содержится ли данная гипотеза слова в соответствующих словарях,задания в документе совокупности областей, каждая из которых содержит, по крайней мере, одно слово,определения показателя доверительности по языку для каждой области, исходя из показателей доверительности, сопоставляемых со словами данной области, и кластеризации областей, имеющих относительно высокие показатели доверительности по данному языку, с целью формирования подзоны, которую идентифицируют данным языком. 2. Способ по п.1, согласно которому гипотезу формируют только относительно слов, минимальная длина которых составляет, по крайней мере, два символа. 3. Способ по п.1, согласно которому упомянутые показатели доверительности для слов,относительно которых сформированы гипотезы,взвешиваются в соответствии с длинами слов,относительно которых сформированы гипотезы. 4. Способ по п.1, дополнительно включающий в себя этапы определения вероятности распознавания для каждой гипотезы и взвешивания упомянутых показателей доверительности в соответствии с вероятностями распознавания. 5. Способ по п.1, согласно которому упомянутые показатели доверительности для слов,относительно которых сформированы гипотезы,взвешивают в соответствии с частотами, с которыми слова, относительно которых сформированы гипотезы, встречаются в соответствующих языках. 6. Способ по п.1, согласно которому упомянутую первоначальную гипотезу формируют с помощью классификатора, который является общим по отношению к каждому из упомянутых нескольких языков. 7. Способ автоматической сегментации документа на однородные по языку подзоны,включающий в себя этапы задания в документе, по крайней мере, одной зоны, которая содержит совокупность слов,задания словаря каждого из нескольких языков,определения для каждого слова данной зоны показателя доверительности по каждому из упомянутых нескольких языков, причем показатель определяют, исходя из того, содержится ли данное слово в соответствующих словарях, 17 идентификации зонального языка для данной зоны, исходя из показателей доверительности, сопоставляемых со словами данной зоны,выбора в данной зоне локальной области,которая содержит, по крайней мере, одно слово,идентификации областного языка для данной локальной области, исходя из показателя доверительности, сопоставляемого со словами данной области; определения, совпадает ли областной язык с зональным языком, и сегрегации данной локальной области от других областей данной зоны, если ее областной язык не совпадает с зональным языком. 8. Способ автоматического определения одного или нескольких языков, сопоставляемых с текстом документа, включающий в себя этапы сегментации документа на совокупность зон, содержащих области, состоящие из словоформ,формирования, по крайней мере, одной гипотезы относительно символов в упомянутых словоформах,задания словаря каждого из нескольких языков,для каждого слова, относительно которого сформирована гипотеза, определения, какие из упомянутых словарей содержат гипотезу слова,и определения значения доверительности каждому языку,идентификации зонального языка для каждой зоны, исходя из значений доверительности,сопоставляемых со словами данной зоны,идентификации областного языка для каждой области, исходя из значений доверительности, сопоставляемых словами данной области,указания зонального языка в качестве областного языка, если значения доверительности,сопоставляемые со словами данной области,недостаточно высоки, и кластеризации областей зоны, которые имеют один и тот же областной язык, с целью формирования подзоны, которая идентифицируется тем или иным языком. 9. Способ по п.8, согласно которому гипотезу формируют только относительно слов, для которых заранее определено минимальное количество символов, превышающее единицу. 10. Способ по п.8, дополнительно включающий в себя этап взвешивания упомянутых значений доверительности в соответствии с длинами слов, относительно которых сформированы гипотезы. 11. Способ по п.8, дополнительно включающий в себя этапы определения вероятности 18 распознавания для каждой гипотезы и взвешивания упомянутых значений доверительности в соответствии с вероятностями распознавания. 12. Способ по п.8, согласно которому упомянутую первоначальную гипотезу формируют с помощью классификатора, который является общим по отношению к каждому из упомянутых нескольких языков. 13. Способ автоматического определения одного или нескольких языков, сопоставляемых с текстом документа, включающий в себя этапы сегментации документа на совокупность словоформ,формирования, по крайней мере, одной гипотезы относительно символов в упомянутых словоформах,определения для каждой гипотезы слова показателя доверительности, который указывает, содержится ли данное слово в каждом из упомянутых нескольких языков,задания в документе совокупности областей, каждая из которых содержит, по крайней мере, одно слово,определения показателя доверительности по языку для каждой области, исходя из показателей доверительности, сопоставляемых со словами данной области, и кластеризации областей, имеющих относительно высокие показатели доверительности по данному языку, с целю формирования подзоны,которую идентифицируют данным языком. 14. Способ автоматической сегментации документа на однородные по языку подзоны,включающий в себя этапы задания в документе, по крайней мере, одной зоны, которая содержит совокупность слов,определения для каждого слова данной зоны показателя доверительности, который указывает, содержится ли данное слово в каждом из упомянутых нескольких языков,идентификации зонального языка для данной зоны, исходя из показателей доверительности, сопоставляемых со словами данной зоны,выбора в данной зоне локальной области,которая содержит, по крайней мере, одно слово,идентификации областного языка для данной локальной области, исходя из показателя доверительности, сопоставляемого со словами данной области,определения, совпадает ли областной язык с зональным языком, и сегрегации данной локальной области от других областей данной зоны, если ее областной язык не совпадает с зональным языком.
МПК / Метки
МПК: G06F 17/28, G06K 9/72
Метки: оптического, символов, языка, система, автоматической, многоязычного, идентификации, распознавания
Код ссылки
<a href="https://eas.patents.su/13-1689-sistema-avtomaticheskojj-identifikacii-yazyka-dlya-mnogoyazychnogo-opticheskogo-raspoznavaniya-simvolov.html" rel="bookmark" title="База патентов Евразийского Союза">Система автоматической идентификации языка для многоязычного оптического распознавания символов</a>
Устройство для создания интерактивного оптического поля и способ формирования интерактивного оптического поля

Номер патента: 721
Опубликовано: 28.02.2000
Автор: Гольдман Нейл
МПК: G02B 1/00
Метки: создания, интерактивного, способ, формирования, оптического, устройство, поля
Формула / Реферат:
1. Устройство для создания интерактивного оптического поля (ИОП), содержащее прозрачную линзу; матрицу светопроводящих устройств, расположенных на или в прозрачной линзе, причем матрица светопроводящих устройств является, в основном, прозрачной для человеческого глаза; оптический датчик, соединенный с матрицей светопроводящих устройств, для улавливания света, отраженного от человеческого глаза; источник света, излучающий свет, передаваемый...
Замок и выключатель, в которых используются датчики давления для распознавания отпечатка пальца

Номер патента: 1521
Опубликовано: 23.04.2001
Авторы: Саито Есихиро, Тамори Терухико, Фудзимото Есинари
МПК: E05B 49/00, G01L 5/00
Метки: используются, которых, датчики, пальца, распознавания, давления, замок, отпечатка, выключатель
Формула / Реферат:
1. Замок, в котором используется датчик, реагирующий на давление, и который оборудован запорным механизмом, препятствующим перемещению объекта, подлежащего отпиранию управляемым механизмом или электронной схемой, которые препятствуют отпиранию объекта охраны вышеописанным запорным механизмом, датчиком отпечатка пальца, реагирующем на давление, который обнаруживает структуру отпечатка пальца, запоминающими устройствами, которые хранят данные...
Устройство для автоматической транспортировки обрабатываемых заготовок в установке многоэтапной штамповки

Номер патента: 551
Опубликовано: 28.10.1999
Авторы: Штекле Штефан, Штайнхаузер Ульрих, Пергхер Кристоф
МПК: B21K 27/04
Метки: устройство, транспортировки, заготовок, установке, штамповки, многоэтапной, обрабатываемых, автоматической
Формула / Реферат:
1. Устройство для автоматической транспортировки обрабатываемых заготовок в установке многоэтапной штамповки, которая служит для безоблойной штамповки металлических деталей, причем в каждом случае одна обрабатываемая заготовка (W1, W2, W3) на посту (U1, U2, U3) штамповки захватывается захватами с парами взаимодействующих губок (130, 140) для транспортировки на соседний пост (U2, U3, U4) штамповки и размещения там, содержащее трубу (2) для...
Портативная музыкальная система для караоке и картридж для нее

Номер патента: 572
Опубликовано: 29.12.1999
Авторы: Ровнер Яков Шоел-Берович, Агаджанова Марина Алексеевна
МПК: G10H 1/36
Метки: караоке, картридж, портативная, музыкальная, система, нее
Формула / Реферат:
1. Портативная музыкальная система для караоке, содержащая запоминающее устройство с разъемом интерфейса для подключения картриджей с музыкальным сопровождением, средство поиска музыкального сопровождения с декодером, микрофон и устройство для преобразования и обработки входного и воспроизводимого музыкального сопровождения и последующей его передачи на принимающее устройство, отличающаяся тем, что она снабжена дополнительным декодером для...
Система спутникового прямого радиовещания

Номер патента: 1040
Опубликовано: 28.08.2000
Автор: Кампанелла С.Джозеф
МПК: H04J 4/00
Метки: система, прямого, спутникового, радиовещания
Формула / Реферат:
1. Система связи, содержащая: множество восходящих линий связи с частотным уплотнением, причем каждая восходящая линия связи содержит информационный канал; космический сегмент для приема сигналов восходящих линий связи, восстановления данных из информационных каналов в восходящих линиях связи в данные полосы частот модулирующих сигналов и объединения данных из выбранных информационных каналов, по меньшей мере, в один сигнал с временным...
Предыдущий патент: Устройство для очистки и розлива воды
Следующий патент: Гибкая конструкция ударной штанги
Случайный патент: Оппозитный радиальный роторно-поршневой двигатель