Способ и аппаратура для перевода с одного языка на другой







Формула / Реферат
1. Способ создания тематического двуязычного словаря для использования в системе тематического двуязычного перевода, включающий этапы
ввода первого множества документов на первом языке в систему перевода,
выполнения разбора первого множества документов на первое множество отдельных слов,
соотнесения с классами первого множества разобранных слов из первого множества документов,
приложения первого множества разобранных слов к тематическому двуязычному словарю для выполнения перевода, по меньшей мере, некоторых слов из первого множества разобранных слов,
приложения непереведенных разобранных слов из первого множества разобранных слов к обычному двуязычному словарю для выполнения перевода непереведенного первого множества разобранных слов,
ввода второго множества документов на втором языке в систему перевода,
выполнения разбора второго множества документов на второе множество отдельных слов,
соотнесения с классами второго множества разобранных слов из второго множества документов,
приложения второго множества разобранных слов к тематическому двуязычному словарю для выполнения перевода, по меньшей мере, некоторых слов из второго множества разобранных слов,
приложения непереведенных разобранных слов из второго множества разобранных слов к обычному двуязычному словарю для выполнения перевода непереведенного второго множества разобранных слов,
обработки связей слов между первым и вторым множествами переведенных слов для создания прямой и обратной частоты связи и
обновления тематического словаря на основе частоты связи.
2. Способ по п.1, при котором этап ввода первого множества документов содержит этапы приема словесных голосовых сигналов по телефону и обработки голосовых сигналов с использованием схемы распознавания голоса для создания электронных сигналов, представляющих голосовые сигналы.
3. Способ по п.1, при котором этап ввода множества документов содержит этапы приема сигналов от сканера и обработки сигналов сканера с использованием схемы распознавания оптических символов для преобразования сигналов сканера в текстовую информацию.
4. Способ по п.1, при котором этап ввода первого множества документов содержит этап приема текстовой информации посредством клавиатуры компьютера.
5. Способ по п.1, при котором этап соотнесения с классами первого множества разобранных слов содержит этап определения грамматической функции, по меньшей мере, большинства отдельных слов.
6. Способ по п.1, при котором этап соотнесения с классами первого множества разобранных слов содержит этап определения грамматической формы, по меньшей мере, большинства отдельных слов.
7. Способ по п.1, при котором этап соотнесения с классами первого множества разобранных слов содержит этап определения значения, по меньшей мере, большинства отдельных слов.
8. Способ по п.1, при котором этап соотнесения с классами первого множества разобранных слов содержит этапы определения грамматической функции, по меньшей мере, большинства отдельных слов, определения грамматической формы, по меньшей мере, большинства отдельных слов и определения значения, по меньшей мере, большинства отдельных слов.
9. Способ по п.1, дополнительно содержащий этап приложения отдельных слов к модели Маркова, которая связывает каждое отдельное слово с отдельными словами, окружающими каждое отдельное слово, по меньшей мере, для снижения частотности синонимов.
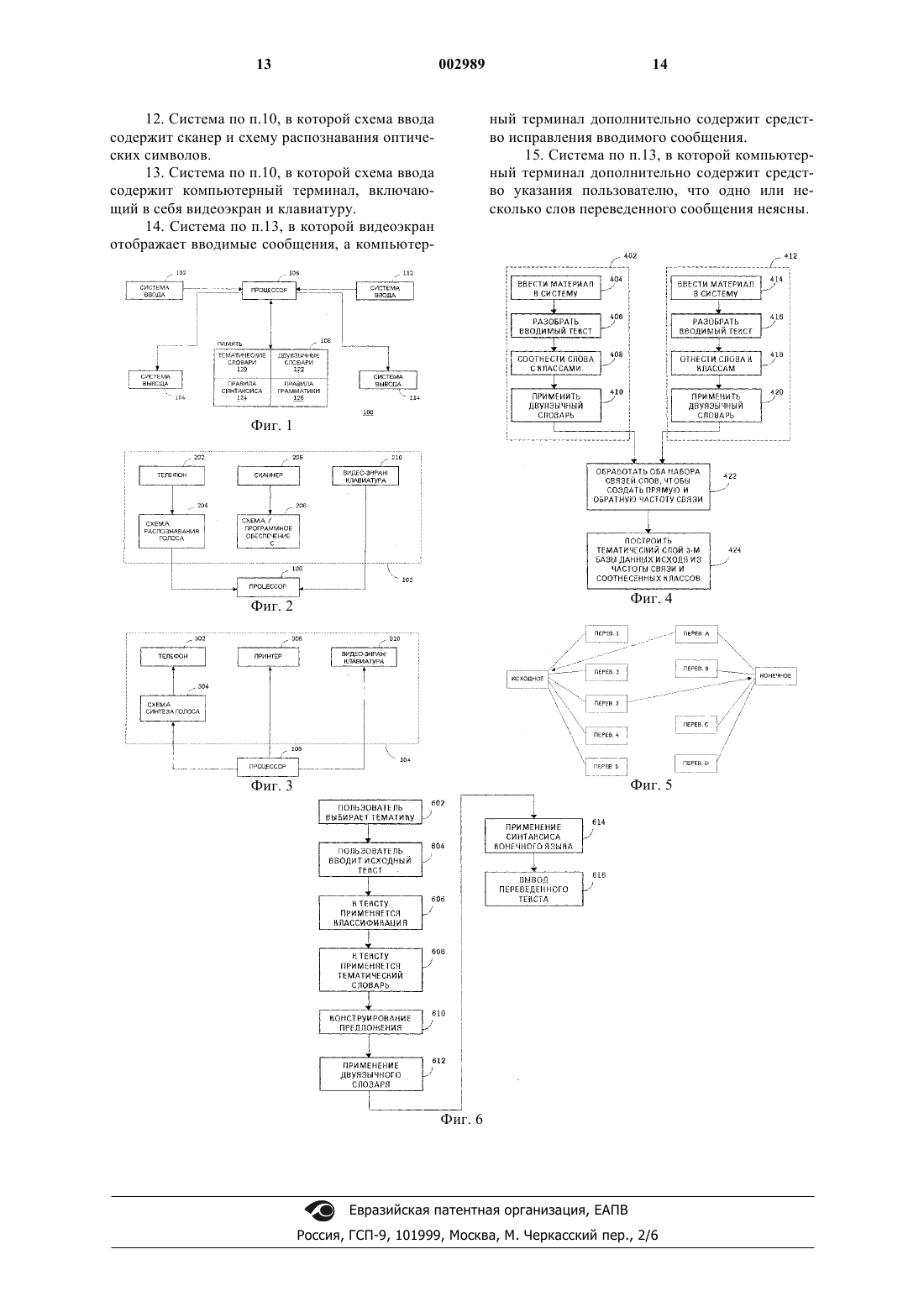
10. Система для создания тематического двуязычного словаря для использования в системе тематического двуязычного перевода, содержащая
схему ввода, принимающую вводимые документы, схему обработки, выполненную с возможностью
осуществления разбора первого множества документов на первое множество отдельных слов и соотнесения с классами первого множества разобранных слов,
осуществления приложения первого множества разобранных слов к тематическому двуязычному словарю для выполнения перевода, по меньшей мере, некоторых слов из первого множества разобранных слов и приложения непереведенных разобранных слов из первого множества разобранных слов к обычному двуязычному словарю для выполнения перевода непереведенных слов первого множества разобранных слов,
выполнения грамматического разбора второго множества документов на второе множество отдельных слов и соотнесения с классами второго множества разобранных слов,
осуществления приложения второго множества разобранных слов к тематическому двуязычному словарю для выполнения перевода, по меньшей мере, некоторых слов второго множества разобранных слов и приложения непереведенных разобранных слов из второго множества разобранных слов к обычному двуязычному словарю для выполнения перевода непереведенного второго множества разобранных слов и
обработки связи слов между первым и вторым множеством переведенных слов для создания прямой и обратной частоты связи, причем тематический словарь на основе частоты связи обновляется.
11. Система по п.10, в которой схема ввода содержит телефон и схему распознавания голоса.
12. Система по п.10, в которой схема ввода содержит сканер и схему распознавания оптических символов.
13. Система по п.10, в которой схема ввода содержит компьютерный терминал, включающий в себя видеоэкран и клавиатуру.
14. Система по п.13, в которой видеоэкран отображает вводимые сообщения, а компьютерный терминал дополнительно содержит средство исправления вводимого сообщения.
15. Система по п.13, в которой компьютерный терминал дополнительно содержит средство указания пользователю, что одно или несколько слов переведенного сообщения неясны.

Текст
1 Предпосылки изобретения Настоящее изобретение относится к переводу с одного языка на другой. Конкретно, настоящее изобретение относится к обеспечению перевода с одного языка на другой, базирующегося, по крайней мере частично, на пользовательском выборе конкретной тематики, на которой концентрируется перевод. Перевод с одного языка на другой широко известен. В основном, перевод осуществляется вручную людьми, которые хорошо владеют как исходным, так и конечным языками. Людипереводчики способны почти мгновенно с очень высокой степенью точности переводить написанный или произносимый текст. Кроме того,перевод, выполненный человеком, зачастую более точен из-за того, что переводчик обладает знаниями, касающимися тематики или предмета, на котором базируется общение. Хотя переводы, выполненные человеком,зачастую весьма точны, они в то же время очень дорого стоят, поскольку для их выполнения требуются люди со специальным образованием. Помимо основных расходов, которые могут быть непомерно высокими, во многих случаях требуется перевод, для которого нужны люди,имеющие дополнительные знания, что еще больше увеличивает стоимость работы. Например, если двое ученых-биотехнолога, говорящих на разных языках, нуждаются в общении, переводчик, помимо хорошего владения обоими языками, должен обладать знаниями по биотехнологии, дабы правильно передавать значение многочисленных технических терминов. Дополнительная проблема перевода, выполняемого человеком, состоит в недостатке квалифицированных специалистов, способных выполнять подобные задания. Было предпринято немало попыток решения проблемы интенсификации труда переводчика. Многие из этих попыток сводились к привлечению электронных устройств для перевода написанного текста с одного языка на другой. Например, в патенте США 4,393,460 Масузавы (Masuzawa) и др. рассматривается электронный переводчик, в котором используется схема, реагирующая на голос, чтобы вводить слова на одном языке, обрабатывающая схема, которая переводит слова на второй язык,и схема синтеза голоса, чтобы произносить переведенные слова на втором языке. Перевод базируется на работе трех анализаторов, которые анализируют символы слова, синтаксис и частоту слов. Один недостаток системы, описанной Масузавой, состоит в том, что она опирается на единственный набор правил и трудных для понимания фраз для каждого языка. Это неизменно влечет за собой ошибки перевода, особенно когда предметом перевода является специализированная тематика. Другая система перевода описана в патенте США 4,805,732, Окамото (Okamoto) и др. В па 002989 2 тенте Окамото рассматривается машина, имеющая участок ввода, участок словаря, где хранится лингвистическая информация, участок обработки и участок вывода. Участок вывода включает в себя дисплей и оборудование, позволяющее пользователю редактировать как вводимый текст, так и переведенный текст. Однако, изобретение Окамото страдает, по крайней мере, тем же недостатком, что и изобретение Масузавы, а именно тем, что перевод базируется на единственном наборе правил для данного языка. В патенте США 5,299,124 Фукумочи(Fukumochi) и др. описана машина для перевода,особым предназначением которой является синтаксический анализ предложения. Вводимое предложение разделяется на слова словарноморфемным анализатором. Переведенное слово приводится в соответствие с грамматической информацией для каждого слова, чтобы получить информацию о времени, лице и числе (т.е. единственное или множественное). Синтаксический анализатор формирует структурноанализирующее дерево на основании словарного перевода и грамматических правил для предложения. Если дерево не удается, предложение разбивается на более мелкие куски и подвергается повторной обработке до тех пор, пока не произойдет успешный перевод. Однако Фукумочи также применяет единственный набор правил для каждого языка. В патенте США 5,437,319 Чонга(Chong) и др. (и публикации WO 92/12494 эквивалента РСТ) описана другая система, которая автоматически переводит вводимый текст на исходном языке в выводимый текст на конечном языке. Чонг применяет словарную базу данных, которая содержит словари основного языка для обычных слов, диалектические словари для специализированных слов и пользовательские словари. Чонг, как и во многих других системах перевода, осуществляет переводы,сначала пытаясь согласовать исходный язык с конечным языком, используя нормальный двуязычный словарь. Если согласование не найдено, применяется специализированный словарь, после чего пользователю предлагается дополнить перевод. В патенте США 4,507,750 Франц(Frantz) и др. пытаются разрешить некоторые из описанных выше трудностей. Отмечая, что для точного перевода пословного перевода недостаточно, Франц описывает систему, которая анализирует контекст внутри данного предложения, чтобы преодолеть различные проблемы,например касающиеся омонимов, которые испытывают другие устройства перевода. Несмотря на то, что Францу удается решить простые проблемы, например различения слов to, too иtwo, Франц, тем не менее, опирается на единственный набор правил для языка. По меньшей мере, по вышеперечисленным причинам задача настоящего изобретения со 3 стоит в том, чтобы предоставить систему перевода, которая переводила бы с одного языка на другой в зависимости от тематики переводимой информации. Задача настоящего изобретения состоит также в том, чтобы предоставить систему перевода, которая опиралась бы на множественные базы правил для данного языка с целью повышения точности перевода. Еще одна задача настоящего изобретения состоит в том, чтобы предоставить систему перевода, которая применяла бы множественные словари для перевода с первого языка на второй. Краткое содержание изобретения Вышеприведенные и иные задачи настоящего изобретения решаются посредством описанных здесь систем и способов, в которых перевод с одного языка на другой базируется, по крайней мере частично, на выборе тематики, на которой базируется общение. Система перевода и способ, отвечающие настоящему изобретению, включают в себя то, что можно назвать трехмерной базой данных, которая строится для каждой пары языков. Три измерения включают в себя исходный язык,конечный язык и тематику (или предмет, на котором базируется общение). Каждая ячейка базы данных включает в себя информацию по каждой тематике, касающейся, например, частоты связи, синонимов и словарного определения, относящегося к тематике. Принципы настоящего изобретения могут применяться к разнообразным системам и способам, чтобы автоматически осуществлять высокоточные переводы. Согласно одному варианту реализации тематические словари конструируются путем сканирования (или другими общепринятыми средствами) различных документов материала. Например, чтобы установить уровень базы данных (т.е. один уровень трехмерной базы данных), относящийся к микробиологии, следует сканировать различные статьи из профессиональных публикаций по микробиологии. Сканированный материал можно пропустить через синтаксический анализатор,который присваивает слова классам слов. Затем к вводимому материалу применяется общепринятый двуязычный словарь, который создает переводы на конечном языке. Наряду со сканированием материала исходного языка аналогичный процесс выполняется над конечным языком с использованием различных документов на конечном языке (относящихся к той же тематике). Конечный результат представляет собой два файла слов на одном языке со связанными с ними переводами. Затем эти два файла обрабатываются посредством нескольких программ распознавания образов с целью вычисления прямой и обратной частоты связи между двумя файлами. Этот процесс создает один уровень трехмерной тематической базы данных (т.е. для выбранной тематики). 4 Как только трехмерная тематическая база данных для данной темы установлена, система может использоваться многими способами. Один вариант реализации представляет собой систему, в которой два человека, которые говорят на разных языках, могут разговаривать друг с другом по телефону при помощи системы, обеспечивающей почти синхронный перевод (каждый абонент, закончив говорить, должен сделать небольшую паузу.) Схема распознавания голоса преобразует аналоговые сигналы, принимаемые от микрофона (или оцифрованный вариант этих сигналов), в сигналы для обработки. Схема обработки преобразует сигналы в слова, к которым затем применяется тематическая база данных и общепринятая двуязычная база данных, чтобы переводить текст. Переведенный текст синтезируется и передается другому абоненту. Краткое описание чертежей Вышеозначенные и иные задачи и преимущества настоящего изобретения будут очевидны при рассмотрении нижеследующего подробного описания, приведенного в сочетании с прилагаемыми чертежами, снабженными сквозными обозначениями одинаковых деталей, где: фиг. 1 является блок-схемой, изображающей один вариант реализации системы перевода, сконструированной в соответствии с принципами настоящего изобретения; фиг. 2 является блок-схемой, иллюстрирующей различные возможные системы ввода для системы перевода, изображенной на фиг .1; фиг. 3 является блок-схемой, иллюстрирующей различные возможные системы вывода для системы перевода, изображенной на фиг. 1; фиг. 4 является блок-схемой процесса построения трехмерной тематической базы данных с использованием той системы перевода,что изображена на фиг. 1, в соответствии с принципами настоящего изобретения; фиг. 5 является схематической диаграммой, демонстрирующей иллюстративный пример части процедуры, изображенной на фиг. 4,используемой при построении трехмерной базы данных; и фиг. 6 является блок-схемой, которая иллюстрирует работу системы перевода, изображенной на фиг. 1, в соответствии с принципами настоящего изобретения. Подробное описание чертежей Отвечающие настоящему изобретению системы и способы перевода с одного языка на другой включают в себя систему обработки, в которой применяется трехмерная база данных (для множественных тематик), с целью обеспечения высокоточного перевода. Каждый уровень базы данных обеспечивает перевод с одного языка на другой для данной тематики (например, биотехнологии, высокочастотных электронных схем, медицинской технологии и т.д.). Также включаются общепринятые двуязычные словари (т.е. не тематические), которые используются для дополнения перевода, осуществляемого процессором, использующим тематический словарь. 5 Фиг. 1 в общих чертах представляет систему для осуществления перевода с одного языка на другой в соответствии с принципами настоящего изобретения. Система перевода 100 включает в себя системы ввода 102 и 112, системы вывода 104 и 114, процессор 106 и память 108. Память 108 может включать в себя возможности постоянного хранения (например,жесткие диски или магнитооптические диски), а также временного хранения, например, ДОЗУ(динамическое оперативное запоминающее устройство). По меньшей мере, часть памяти 108 является устройством временного хранения,которое включает в себя разделы для тематических словарей 120, двуязычных словарей 122,правил синтаксиса 124 и правил грамматики 126. Каждая из частей 120-126 может храниться в устройстве постоянного хранения, пока система 100 не действует, и загружаться в устройство временного хранения в виде части процедуры запуска системы 100. Система перевода 100 может использоваться для создания или модификации тематических словарей 120 или двуязычных словарей 122 при предоставлении системе 100 дополнительной информации через системы ввода 102 и 112. На фиг. 2 показаны некоторые из разнообразных способов ввода информации в систему 100 через систему ввода 102. Специалистам легко понять, что, хотя на фиг. 2 изображены три конкретных варианта реализации схемы устройств ввода, принципы настоящего изобретения могут осуществляться системой,которая включает в себя любое(ую) из устройств/схем ввода, любую комбинацию этих устройств, а также другие известные устройства, которые могут принимать языковую информацию, и схему, которая преобразует эту информацию в сигналы для компьютерной обработки (например, простой микрофон и схема распознавания голоса). Система ввода 102 может, например,включать в себя телефон 202 для приема входных голосовых сигналов и схему распознавания голоса 204 для преобразования этих входных голосовых сигналов в сигналы, которые процессор 106 может обрабатывать как текст. Система ввода 102 может также включать в себя сканнер 206 (или система ввода 102 может включать в себя сканнер 206 вместо телефона 202) для ввода в систему 100 напечатанного текста. В сочетании со сканнером 206 предусматривается программное обеспечение 208 схемы распознавания оптических символов(РОС) для преобразования сигналов сканнера в текст. РОС 208 может располагаться внутри сканнера 206, может являться независимым аппаратным обеспечением или может находиться внутри процессора 106 (несколько менее желательно по причине дополнительной нагрузки,оказываемой на процессор 106). Другой вариант системы ввода 102 представляет собой видеоэкран/клавиатуру 210, которые могут представлять собой специализиро 002989 6 ванный персональный компьютер, автономный сенсорный видеоэкран, позволяющий выбирать варианты ввода путем прикосновения к экрану,или терминал, подключенный к серверу или главному компьютеру. Видео/клавиатура 210 позволяет пользователю непосредственно вводить информацию в систему 100 и при использовании в качестве части систем вывода 104 и 114 может позволять пользователю редактировать введенный текст,переведенный текст или оба, что более подробно описано ниже. Кроме того, хотя фиг. 2 описана применительно к системе ввода 102, специалистам очевидно, что те же самые принципы можно применить к системе ввода 112, не выходя за рамки объема настоящего изобретения. Система вывода 104, с другой стороны,может также включать в себя телефон 302, присоединенный к схеме синтеза голоса 304, которая преобразует переведенный текст в голосовые сигналы на языке перевода. Конечно, в зависимости от конфигурации телефоны 202 и 302 могут быть единственным телефоном, в зависимости от того, используется ли телефон в качестве устройства ввода или устройства вывода. Когда телефоны 202 и 302 являются единственным телефоном, схема распознавания голоса 204 и схема синтеза голоса 304 также предпочтительно являются единым электронным устройством, которое осуществляет обе функции. Система вывода 104 может также включать в себя принтер 206 (или система вывода 104 может включать в себя принтер 306 вместо телефона 302), чтобы распечатывать текст, переведенный системой 100. Система вывода 104 можете взамен включать в себя видеоэкран/клавиатуру 310, которые могут представлять собой специализированный персональный компьютер, автономный сенсорный видеоэкран, позволяющий пользователю выбирать варианты ввода путем прикосновения к экрану, или терминал, подключенный к серверу или главному компьютеру. Видео/клавиатура 310 позволяет пользователю принимать информацию перевода от системы 100, что при использовании в сочетании с системами ввода 102 и 112 может позволить пользователю редактировать вводимый текст,переведенный текст или оба, что подробно описано ниже. Кроме того, хотя фиг. 3 была описана применительно к системе вывода 104, специалистам очевидно, что те же самые принципы можно применить к системе вывода 114, не выходя за рамки объема настоящего изобретения. Фиг. 4 является блок-схемой, которая иллюстрирует, как может строиться трехмерный тематический словарь 120 в соответствии с принципами настоящего изобретения. Процедура, показанная на фиг. 4, включает в себя две главные ветви 402 и 412, которые могут исполняться параллельно, последовательно или в любой их комбинации, в зависимости от конкрет 7 ной конфигурации системы перевода 100. Каждая из ветвей 402 и 412 включает в себя четыре этапа (т.е. ветвь 402 включает в себя этапы 404410, а ветвь 412 включает в себя этапы 414-420,которые в сущности идентичны этапам 404-410 и по этой причине отдельно не рассматриваются ниже), результатом чего является база данных,имеющая один или несколько переводов на конечный язык, связанных с каждым вводимым словом на исходном языке. Процедура, показанная на фиг. 4, подлежит исполнению для каждой тематики, в которой может нуждаться перевод. Таким образом, когда пользователь использует эту систему, что полнее описывается ниже, пользователь выбирает отдельную тематику, которую система перевода 100 использует, чтобы концентрироваться на ней при переводе, дабы перевод создавался более точным образом. Первый этап создания одного тематического уровня тематического словаря 120 состоит в том, чтобы ввести материал в систему (т.е. этап 404). Как описано выше, этап 404 может исполняться несколькими способами. Например, материал можно вводить в систему 100 через телефон 202, позволяющий устно зачитывать документы или использовать сканнер 206 и схему/программное обеспечение РОС 208 для быстрого ввода многочисленных документов. Альтернативно, материал можно набирать при помощи видеоэкрана/клавиатуры 210. После ввода материала в систему 100, процессор 106 на этапе 406 обрабатывает вводимую информацию с целью разбора вводимого материала на отдельные слова. Разбор является широко известной процедурой для преобразования отдельных вводимых символов в слова (т.е. построения слова путем включения всех символов между двумя пробелами). За разбором следует соотнесение слов с классами слов (т.е. этап 408). Эти классы базируются, по меньшей мере частично, на такой информации, как грамматическая функция (например, играет ли слово роль подлежащего, определения или дополнения), грамматическая форма (например, падеж существительного или глагол в каком-то времени) и значение. После того, как классы слов присвоены, процессор 106 на этапе 410 обрабатывает вводимые слова с помощью двуязычного словаря 122, чтобы создать один или несколько переводов на конечный язык для каждого вводимого слова. После выполнения ветвей 402 и 412 для всех имеющихся материалов (или, по меньшей мере, для количества материалов, достаточного для устойчивого поведения системы), процессор 106 на этапе 422 обрабатывает связи слова. Например, процессор 106 может применять связи слова из каждой ветви для формирования нейронной сети, которая определяет двустороннюю частоту связи для каждого слова. Это показано на фиг. 5, где предполагается, что слово исходного языка (например, английского) имеет пять переводов (ПЕРЕВ.1 - ПЕРЕВ.5) на конечный 8 язык (например, японский), а японское слово имеет четыре английских перевода (ПЕРЕВ.А ПEPEB.D). В этом примере ПЕРЕВ.3 является в точности тем же словом, что и КОНЕЧНОЕ, а ПЕРЕВ.А является в точности тем же словом,что и ИСХОДНОЕ. Однако, если нейронная сеть находит, что для выбранной тематики ИСХОДНОЕ имеет значительно более высокую частотность, будучи переведенным как ПЕРЕВ.4, то тематический словарь 120 включит перевод ИСХОДНОГО как ПЕРЕВ.4, вместо того, чтобы использовать ПЕРЕВОД. 3, как могли бы делать общепринятые переводчики. Двусторонние частоты связи используются процессором 106 в ходе применения способа Маркова во время обработки перевода. Способ Маркова может использоваться, например, для определения переходной вероятности появления одного слова после того, как было определено первое слово. Кроме того, в соответствии с принципами настоящего изобретения результаты способа Маркова могут варьироваться в зависимости от выбранной пользователем тематики. Один вариант этого способа показан ниже в таблице, в которой группа английских слов (показанных просто в виде комбинаций букв) коррелируется группой японских слов (изображенных в виде группы чисел). Для каждого слова на английском матрица Маркова, приведенная в таблице, задает вероятность перехода для каждого японского слова,которое может служить переводом этого английского слова. Например, ABD можно перевести четырьмя различными японскими словами(т.е. 126, 254, 367 и 597), однако для выбранной тематики наиболее высока вероятность того, чтоABD следует переводить как 254 (вероятность 50%). Каждое слово в каждой строке и каждом столбце имеет полную вероятность 100% (например, слово 367 имеет четыре вероятности,которые в сумме дают 1- .1 + .1 + .6 + .2 = 1),что отражает тот факт, что каждое слово можно переводить в каждом направлении (т.е. с английского на японский или с японского на английский). Как только все слова обработаны с использованием нейронной сети, процессор 106 на этапе 424 обновляет тематический словарь 120,чтобы включить тематический уровень для вы 9 бранной тематики. Процесс, представленный на фиг. 4, может также использоваться для обновления любого слоя тематического словаря. В таком случае этапы 410 и 420 выполнялись бы путем применения к словам существующего уровня тематического словаря 120 до применения должного двуязычного словаря 122. Таким образом, можно было бы дополнительно повысить точность тематического словаря для выбранной тематики. На фиг. 6 изображена блок-схема, которая иллюстрирует работу системы перевода 100 в соответствии с принципами настоящего изобретения. Способ, представленный на фиг. 6, можно использовать в разнообразных целях, хотя в целях иллюстрации предмет обсуждения сводится к телефонному разговору между двумя людьми, говорящими на разных языках. Кроме того, в порядке обсуждения, предполагается,что система перевода 100, используемая при выполнении этапов, показанных на фиг. 6,включает в себя комбинированные системы ввода/вывода 102/104 и 112/114, которые включают в себя телефон 202/302 (включающий в себя схему 204/304, необходимую для обработки голосовых данных) и видеоэкран/клавиатуру 210/310 для каждой стороны. Первый этап происходит, когда человек, инициирующий вызов, на этапе 602 выбирает тематику разговора (например, если двое ученых намереваются обсудить химический состав нового лекарства против СПИДа, вызывающий абонент может выбрать химию, фармацевтические препараты или СПИД, в зависимости от тематической широты используемой системы). Вызов проходит общепринятым способом, и оба пользователя вступают в диалог (этап не показан). Каждый абонент говорит на этапе 604 в телефонную трубку, и голосовые сигналы обрабатываются, пока процессор 106 принимает сигналы, представляющие подвергнутые разбору вводимые слова на исходном языке. На этапе 606 процессор 106 присваивает классы словам наподобие того, что было описано выше в отношении этапов 408 и 418. Кроме того, вводимые слова можно обрабатывать с использованием, например, модели Маркова, чтобы выявить связь между каждым вводимым словом и окружающими словами. Модель Маркова позволяет системе 100 различать синонимы (например, "to, too и two"), а также вставлять пропущенные слова в тех случаях,когда произносятся словосочетания и незаконченные или неполные предложения. На этапе 608 процессор 106 применяет к вводимым словам тематический словарь 120,чтобы выработать первоначальный перевод на конечный язык. На этапе 610 процессор 106 конструирует предложения путем применения к вводимым словам правил синтаксиса 124 исходного языка. Любой дополнительный перевод(например, любых других пропущенных слов) выполняется на этапе 612 путем обработки информации с применением двуязычного словаря 10 122, а также путем применения к вводимым словам правил грамматики 126. На этапе 614 процессор 106 обрабатывает вводимые слова и связанные с ними переводы по правилам синтаксиса 124 для конечного языка, в результате чего, получается переведенное сообщение, которое сохраняется в памяти 108. На этапе 616 информация выводится получателю в виде текста, произносимого на конечном языке посредством телефона 202/302. Кроме того, по мере того, как человек на протяжении этапа 604 говорит по телефону 202/302, вводимые слова отображаются на видеоэкране/клавиатуре 210/310 (как только процессор 106 принимает их в проанализированном состоянии). Тем самым, человек получает возможность прерывать процессор 106 с целью проверки, по мере необходимости, вводимого сообщения (например, если в процессе распознавания голоса обнаруживаются ошибки). В то время, как слова синтезируются на конечном языке, получатель может также просматривать переведенное сообщение на видеоэкране/клавиатуре 210/310 и обеспечивать мгновенную обратную связь, если перевод непонятен. Например, если предложение, по большей части, понятно, за исключением одного-двух слов,человек может выбрать неясные слова на видеоэкране/клавиатуре 210/310, например, используя мышь или систему ввода сенсорного экрана (не показана). Вводимое слово предоставляется обратно инициатору, который может предоставить измененный текст на исходном языке, который затем переводится по-другому. Таким образом, специалистам будет ясно, что настоящее изобретение может осуществляться на практике в вариантах реализации, отличных от описанных, которые представлены в целях иллюстрации, но не ограничения, и что настоящее изобретение ограничивается только нижеследующей формулой изобретения. Например, два человека,говорящие на разных языках, могли бы иметь полный разговор в режиме диалога, используя только пару видеоэкран/клавиатура 210/310 вместо телефонов 202/302, или система перевода настоящего изобретения может использоваться для перевода технической или иной специализированной документации на основе использования тематического словаря. ФОРМУЛА ИЗОБРЕТЕНИЯ 1. Способ создания тематического двуязычного словаря для использования в системе тематического двуязычного перевода, включающий этапы ввода первого множества документов на первом языке в систему перевода,выполнения разбора первого множества документов на первое множество отдельных слов, 11 соотнесения с классами первого множества разобранных слов из первого множества документов,приложения первого множества разобранных слов к тематическому двуязычному словарю для выполнения перевода, по меньшей мере,некоторых слов из первого множества разобранных слов,приложения непереведенных разобранных слов из первого множества разобранных слов к обычному двуязычному словарю для выполнения перевода непереведенного первого множества разобранных слов,ввода второго множества документов на втором языке в систему перевода,выполнения разбора второго множества документов на второе множество отдельных слов,соотнесения с классами второго множества разобранных слов из второго множества документов,приложения второго множества разобранных слов к тематическому двуязычному словарю для выполнения перевода, по меньшей мере,некоторых слов из второго множества разобранных слов,приложения непереведенных разобранных слов из второго множества разобранных слов к обычному двуязычному словарю для выполнения перевода непереведенного второго множества разобранных слов,обработки связей слов между первым и вторым множествами переведенных слов для создания прямой и обратной частоты связи и обновления тематического словаря на основе частоты связи. 2. Способ по п.1, при котором этап ввода первого множества документов содержит этапы приема словесных голосовых сигналов по телефону и обработки голосовых сигналов с использованием схемы распознавания голоса для создания электронных сигналов, представляющих голосовые сигналы. 3. Способ по п.1, при котором этап ввода множества документов содержит этапы приема сигналов от сканера и обработки сигналов сканера с использованием схемы распознавания оптических символов для преобразования сигналов сканера в текстовую информацию. 4. Способ по п.1, при котором этап ввода первого множества документов содержит этап приема текстовой информации посредством клавиатуры компьютера. 5. Способ по п.1, при котором этап соотнесения с классами первого множества разобранных слов содержит этап определения грамматической функции, по меньшей мере, большинства отдельных слов. 6. Способ по п.1, при котором этап соотнесения с классами первого множества разобранных слов содержит этап определения граммати 002989 12 ческой формы, по меньшей мере, большинства отдельных слов. 7. Способ по п.1, при котором этап соотнесения с классами первого множества разобранных слов содержит этап определения значения,по меньшей мере, большинства отдельных слов. 8. Способ по п.1, при котором этап соотнесения с классами первого множества разобранных слов содержит этапы определения грамматической функции, по меньшей мере, большинства отдельных слов, определения грамматической формы, по меньшей мере, большинства отдельных слов и определения значения, по меньшей мере, большинства отдельных слов. 9. Способ по п.1, дополнительно содержащий этап приложения отдельных слов к модели Маркова, которая связывает каждое отдельное слово с отдельными словами, окружающими каждое отдельное слово, по меньшей мере, для снижения частотности синонимов. 10. Система для создания тематического двуязычного словаря для использования в системе тематического двуязычного перевода, содержащая схему ввода, принимающую вводимые документы, схему обработки, выполненную с возможностью- осуществления разбора первого множества документов на первое множество отдельных слов и соотнесения с классами первого множества разобранных слов,- осуществления приложения первого множества разобранных слов к тематическому двуязычному словарю для выполнения перевода, по меньшей мере, некоторых слов из первого множества разобранных слов и приложения непереведенных разобранных слов из первого множества разобранных слов к обычному двуязычному словарю для выполнения перевода непереведенных слов первого множества разобранных слов,- выполнения грамматического разбора второго множества документов на второе множество отдельных слов и соотнесения с классами второго множества разобранных слов,- осуществления приложения второго множества разобранных слов к тематическому двуязычному словарю для выполнения перевода, по меньшей мере, некоторых слов второго множества разобранных слов и приложения непереведенных разобранных слов из второго множества разобранных слов к обычному двуязычному словарю для выполнения перевода непереведенного второго множества разобранных слов и- обработки связи слов между первым и вторым множеством переведенных слов для создания прямой и обратной частоты связи,причем тематический словарь на основе частоты связи обновляется. 11. Система по п.10, в которой схема ввода содержит телефон и схему распознавания голоса. 12. Система по п.10, в которой схема ввода содержит сканер и схему распознавания оптических символов. 13. Система по п.10, в которой схема ввода содержит компьютерный терминал, включающий в себя видеоэкран и клавиатуру. 14. Система по п.13, в которой видеоэкран отображает вводимые сообщения, а компьютер 14 ный терминал дополнительно содержит средство исправления вводимого сообщения. 15. Система по п.13, в которой компьютерный терминал дополнительно содержит средство указания пользователю, что одно или несколько слов переведенного сообщения неясны.
МПК / Метки
МПК: G06F 17/28
Метки: способ, одного, перевода, аппаратура, языка
Код ссылки
<a href="https://eas.patents.su/8-2989-sposob-i-apparatura-dlya-perevoda-s-odnogo-yazyka-na-drugojj.html" rel="bookmark" title="База патентов Евразийского Союза">Способ и аппаратура для перевода с одного языка на другой</a>
Незаметное переключение с одного лепестка на другой

Номер патента: 2245
Опубликовано: 28.02.2002
Авторы: Андермо Пер-Йоран, Андерссон Хенрик
МПК: H04Q 7/38
Метки: одного, лепестка, переключение, незаметное
Формула / Реферат:
1. Способ осуществления связи в системе связи между, по меньшей мере, одним базовым узлом, обслуживающим один или более секторов, каждый из которых разделен на фиксированные лепестки, и подвижной станцией, находящейся в пределах зоны обслуживания базового узла, включающий установление соединения с формированием канала между приемопередающим оборудованием базового узла и подвижной станцией, передачу сигналов между указанным приемопередающим...
Система автоматической идентификации языка для многоязычного оптического распознавания символов

Номер патента: 1689
Опубликовано: 25.06.2001
Авторы: Чой Кеннет Чан, Пон Леонард К., Боксер Минди Р., Канунго Тапас, Янг Дзун
МПК: G06F 17/28, G06K 9/72
Метки: распознавания, языка, символов, многоязычного, система, автоматической, оптического, идентификации
Формула / Реферат:
1. Способ автоматического определения одного или более языков, сопоставляемых с текстом документа, включающий в себя этапы сегментации документа на совокупность словоформ, формирования, по крайней мере, одной гипотезы относительно символов в упомянутых словоформах, задания словаря каждого из нескольких языков, определения для упомянутой гипотезы слова показателей доверительности по упомянутым нескольким языкам, причем показатели определяют...
Способ и аппаратура для осуществления жесткого переключения мобильной станции между системами связи

Номер патента: 1724
Опубликовано: 27.08.2001
Авторы: Чен Тао, Уитли Чарльз Е.III, Тидманн Эдвард Г.
МПК: H04Q 7/38
Метки: переключения, связи, аппаратура, жесткого, станции, способ, системами, между, осуществления, мобильной
Формула / Реферат:
1. Способ избежания потери связи с мобильной станцией в системе радиосвязи, в которой мобильная станция перемещается из области, покрываемой исходной системой, в область, покрываемую первой системой назначения, и в которой со стороны упомянутой мобильной системы была предпринята попытка установить связь с упомянутой системой назначения, и эта попытка окончилась неудачей, содержащий следующие этапы: предпринимают попытку с помощью упомянутой...
Способ и аппаратура для облагораживания углеводородного сырья, содержащего серу, металлы и асфальтены

Номер патента: 1938
Опубликовано: 22.10.2001
Авторы: Реттджер Филип Б., Фрайди Дж.Роберт, Гольдштейн Рэндалл С.
МПК: C10G 69/02
Метки: облагораживания, аппаратура, асфальтены, способ, сырья, углеводородного, содержащего, металлы, серу
Формула / Реферат:
1. Способ облагораживания углеводородного сырья, содержащего серу, металлы и асфальтены, предусматривающий: а) подачу упомянутого сырья в дистилляционную колонну для получения по существу свободной от асфальтенов и от металлов дистиллятной фракции и не поддающейся перегонке фракции, содержащей серу, асфальтены и металлы; b) превращение, по крайней мере, части упомянутой дистиллятной фракции, по существу свободной от асфальтенов и металлов, в...
Способ проведения буровых работ на морском дне с использованием одного трубопровода

Номер патента: 1885
Опубликовано: 22.10.2001
Автор: Тома Пьер-Арман
МПК: E21B 7/132
Метки: трубопровода, использованием, буровых, работ, морском, проведения, одного, дне, способ
Формула / Реферат:
1. Способ проведения буровых работ на морском дне с использованием одного трубопровода, свободный конец которого закреплен на полупогруженной в воду платформе, приспособленной для эксплуатации месторождения на совокупности отдельных точек для бурения, заключающийся в том, что устанавливают на якорь платформу для ее удержания неподвижной над месторождением, монтируют трубопровод, соединяющий плавающую платформу с морским дном для проведения...
Следующий патент: Способ модификации гармонического содержания сигнала сложной формы
Случайный патент: Устройство и способ связи