Улучшенный способ и система для выявления и/или прогнозирования биологических аномалий, например, церебральных нарушений






Формула / Реферат
1. Способ обнаружения или прогнозирования биологических отклонений, содержащий этапы, на которых:
анализируют входные биологические или физические данные, используя процедуру обработки данных с использованием алгоритма PD2i, причем упомянутые данные включают в себя набор прикладных параметров, связанных с биологическими данными, коррелирующими с биологическими отклонениями для генерации серий данных;
определяют, является ли угловой коэффициент серий данных меньше заданного значения;
если угловой коэффициент меньше заданного значения, устанавливают заданную величину углового коэффициента и
используют серии данных для обнаружения или прогнозирования появления биологических отклонений.
2. Способ обнаружения или прогнозирования церебральных нарушений, содержащий этапы, на которых:
анализируют входные биологические или физические данные, используя процедуру обработки данных с использованием алгоритма PD2i, причем упомянутые данные включают в себя набор прикладных параметров, связанных с биологическими данными, коррелирующими с биологическими отклонениями для генерации серий данных;
определяют, является ли угловой коэффициент серий данных меньше заданного значения;
если угловой коэффициент меньше заданного значения, устанавливают заданную величину углового коэффициента и
используют серии данных для обнаружения или прогнозирования возникновения церебральных нарушений.
3. Способ по п.1 или 2, в котором заданное значение представляет собой приблизительно 0,5.
4. Способ по п.1 или 2, в котором заданная величина представляет собой 0.
5. Способ по п.1 или 2, дополнительно включающий этапы, на которых
определяют шумовой интервал внутри серий данных; и
если этот шумовой интервал находится внутри заданной области, делят серии данных на другую заданную величину и повторяют этап анализа для генерации новых значений серий данных.
6. Способ по п.5, в котором другая заданная величина представляет собой 2.
7. Способ по п.5, в котором заданная область составляет от -х до +х, где х представляет собой любую величину.
8. Способ по п.7, в котором заданная область составляет от -5 до +5.
9. Способ для обнаружения или прогнозирования биологических отклонений, содержащий этапы, на которых: анализируют входные биологические или физические данные, используя процедуру обработки данных с использованием алгоритма PD2i, причем упомянутые данные включают в себя набор прикладных параметров, связанных с биологическими данными, коррелирующими с биологическими отклонениями для генерации серий данных;
определяют шумовой интервал внутри серий данных; и
если шумовой интервал находится внутри заданной области, делят серии данных на заданную величину и повторяют этап анализа для генерации новых значений для серий данных; или
если шумовой интервал находится вне заданной области, используют серии данных для обнаружения или прогнозирования исхода биологических отклонений.
10. Способ для обнаружения или прогнозирования церебральных нарушений, содержащий этапы, на которых
анализируют входные биологические или физические данные, используя процедуру обработки данных с использованием алгоритма PD2i, причем упомянутые данные включают в себя набор прикладных параметров, связанных с биологическими данными, коррелирующими с биологическими отклонениями для генерации серий данных;
определяют шумовой интервал внутри серий данных; и
если шумовой интервал находится внутри заданной области, делят серии данных на заданную величину и повторяют этап анализа для генерации новых значений для серий данных; или
если шумовой интервал находится вне заданной области, используют серии данных для обнаружения или прогнозирования исхода церебральных нарушений.
11. Способ по п.9 или 10, в котором заданная величина представляет собой 2.
12. Способ по п.9 или 10, в котором заданная область составляет от -х до +х, где х представляет собой любую величину.
13. Способ по п.12, в котором заданная область составляет от -5 до +5.
14. Способ по п.9 или 10, дополнительно включающий в себя этапы, на которых
определяют, является ли угловой коэффициент серий данных меньше заданного значения; и
если угловой коэффициент меньше заданного значения, устанавливают угловой коэффициент в другую заданную величину.
15. Способ по п.14, в котором заданное значение представляет собой приблизительно 0,5.
16. Способ по п.14, в котором другая заданная величина представляет собой 0.
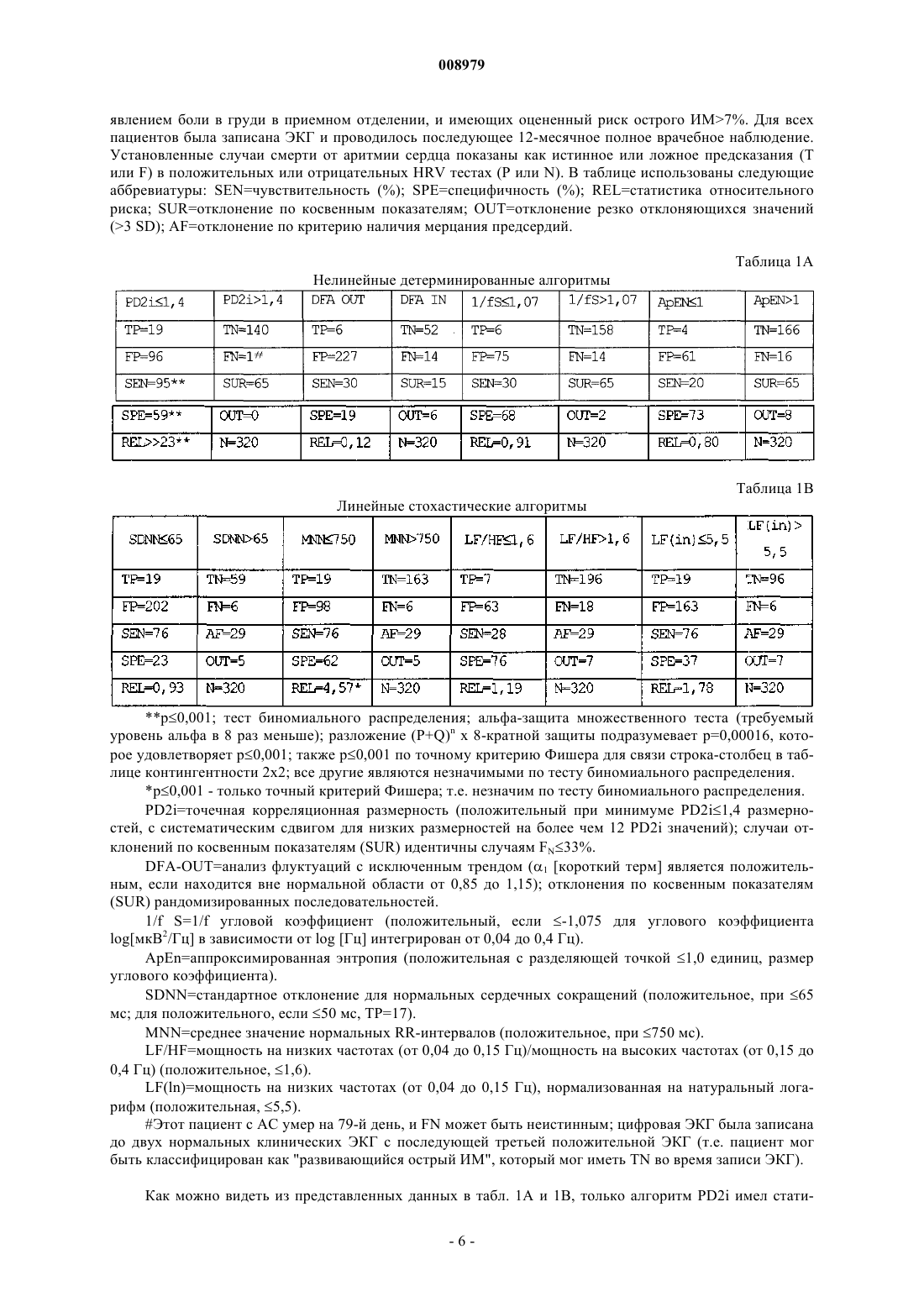
17. Способ по любому из пп.1, 2, 9, 10, в котором процедура обработки данных использует нижеследующий алгоритм для генерации PD2i серий данных:
PD2iНlog C(n, r, nref*)/log r
где Н означает "масштабирование в виде", С представляет собой корреляционный интеграл для PD2i, в котором n равно длине данных, r равно длине области масштабирования и nref* равно местоположению референсного вектора для оценки области масштабирования углового коэффициента log C/log r в ограниченной области малых log r, в которой отсутствуют эффекты нестационарности данных.
18. Способ по п.1 или 9, в котором входные биологические или физические данные включают в себя электрофизиологические данные.
19. Способ по п.18, в котором электрофизиологические данные представляют собой данные ЭКГ, которые анализируют для обнаружения или прогнозирования появления, по меньшей мере, либо аритмии сердца, либо церебрального эпилептического припадка, и/или для измерения тяжести ишемии миокарда.
20. Способ по п.2 или 10, в котором входные биологические или физические данные включают в себя электрофизиологические данные.
21. Способ по п.2 или 10, в котором церебральное нарушение представляет собой губкообразную энцефалопатию крупного рогатого скота.
22. Способ по п.2 или 10, в котором церебральное нарушение представляет собой болезнь Альцгеймера.
23. Устройство для обнаружения или прогнозирования биологических отклонений, причем устройство содержит
средство для анализа входных биологических или физических данных с использованием процедуры обработки данных с использованием алгоритма PD2i, причем упомянутые данные включают в себя набор прикладных параметров, связанных с биологическими данными, коррелирующими с биологическими отклонениями для генерации серий данных;
средство для определения, является ли угловой коэффициент серий данных меньше заданного значения;
средство для установки заданной величины углового коэффициента, если угловой коэффициент меньше заданного значения; и
средство для использования серий данных для обнаружения или прогнозирования появления биологических отклонений.
24. Устройство по п.23, в котором заданное значение представляет собой приблизительно 0,5.
25. Устройство по п.23, в котором заданная величина представляет собой 0.
26. Устройство по п.23, дополнительно включающее
средство для определения шумового интервала внутри серий данных и
средство для деления серий данных на другую заданную величину, если указанный шумовой интервал находится внутри заданной области, и предоставления результата деления серий данных в средство для анализа для генерации новых значений серий данных.
27. Устройство по п.26, в котором другая заданная величина представляет собой 2.
28. Устройство по п.26, в котором заданная область составляет от -х до +х, где х представляет собой любую величину.
29. Устройство по п.28, в котором заданная область составляет от -5 до +5.
30. Устройство для обнаружения или прогнозирования биологических отклонений, причем устройство содержит
средство для анализа входных биологических или физических данных с использованием процедуры обработки данных с использованием алгоритма PD2i, причем упомянутые данные включают в себя набор прикладных параметров, связанных с биологическими данными, коррелирующими с биологическими отклонениями для генерации серий данных;
средство для определения шумового интервала внутри серий данных; и
средство для деления серии данных на заданную величину, если шумовой интервал находится внутри заданной области, и предоставления поделенных в средство для анализа для генерации новых значений для серий данных; и
средство для использования серий данных для обнаружения или прогнозирования появления биологических отклонений, если шумовой интервал находится вне заданной области.
31. Устройство по п.30, в котором заданная величина представляет собой 2.
32. Устройство по п.30, в котором заданная область составляет от -х до +х, где х представляет собой любую величину.
33. Устройство по п.32, в котором заданная область составляет от -5 до +5.
34. Устройство по п.30, дополнительно включающее
средство для определения, является ли угловой коэффициент серий данных меньше заданного значения; и
средство для установки углового коэффициента в другую заданную величину, если угловой коэффициент меньше заданного значения.
35. Устройство по п.34, в котором заданное значение представляет собой приблизительно 0,5.
36. Устройство по п.34, в котором другаязаданная величина представляет собой 0.
37. Устройство по п.23 или 30, в котором процедура обработки данных использует нижеследующий алгоритм для генерации PD2i серий данных:
PD2iНlog C(n, r, nref*)/log r
где Н означает "масштабирование в виде", С представляет собой корреляционный интеграл для PD2i, в котором n равно длине данных, r равно области масштабирования и nref* равно местоположению референсного вектора для оценки области масштабирования угла наклона log C/log r в ограниченной области малых log r, в которой отсутствуют эффекты нестационарности данных.
38. Устройство по п.23 или 30, в котором входные биологические или физические данные включают в себя электрофизиологические данные.
39. Устройство по п.38, в котором электрофизиологические данные представляют собой данные ЭКГ, которые анализируют для обнаружения или прогнозирования появления, по меньшей мере, либо аритмии сердца, либо церебрального эпилептического припадка, и/или для измерения тяжести ишемии миокарда.

Текст
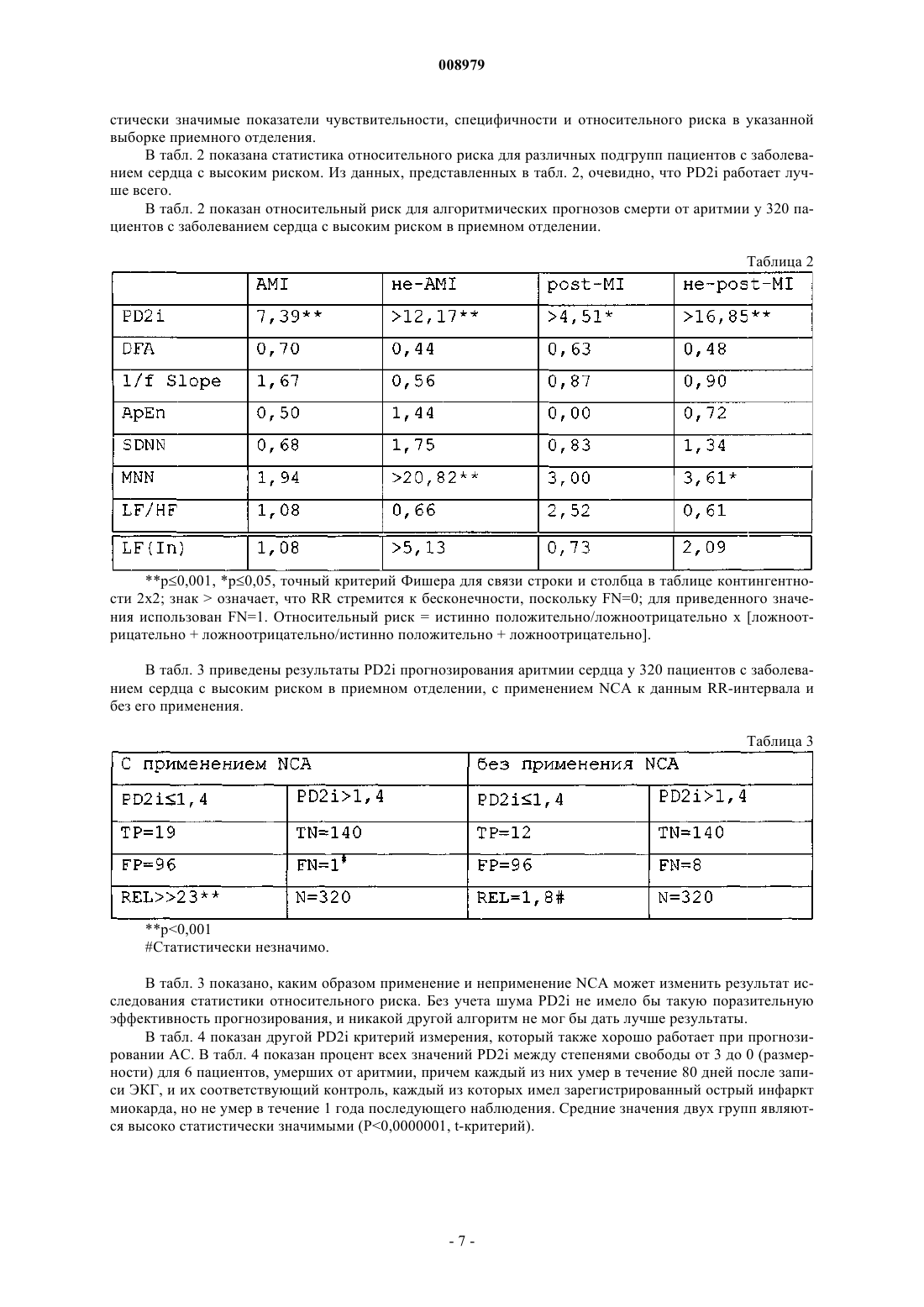
008979 Перекрестная ссылка на родственные заявки на патент Настоящая заявка на патент притязает на приоритет заявки на патент США 10/353849, поданной 29 января 2003 г., и предварительной заявки на патент США 60/445495, поданной 6 февраля 2003 г. Эти заявки включены в настоящее описание во всей своей полноте в качестве ссылки. Область техники, к которой относится изобретение Настоящее изобретение относится к способу и системе для оценки биологических и физических данных. Более конкретно, настоящее изобретение относится к способу и системе для оценки биологических и физических данных для выявления и/или прогнозирования биологических отклонений. Запись электрофизиологических потенциалов стала доступной в области медицины с момента изобретения гальванометра. С 1930-х годов электрофизиология стала применяться при диагностике сердечных нарушений и церебральной эпилепсии. Опыт современной медицины показывает, что при помощи анализа интервалов R-R, наблюдаемых в электрокардиограммах, или пиковых потенциалов, видимых на электроэнцефалограмме, можно прогнозировать будущий клинический исход, например внезапную сердечную смерть или эпилептические припадки. Такой анализ и прогнозы являются статистически значимыми в случаях применения для обнаружения различий результатов между большими группами пациентов, которые либо обнаруживают, либо не обнаруживают прогнозируемый исход, но известные аналитические способы не очень точны в случае применения к отдельным пациентам. Такой общий недостаток известных аналитических показателей приводит в результате к большому количеству неверных прогнозов; т.е. показатели имеют низкую статистическую чувствительность и специфичность при прогнозе. Как правило, известно, что в исследуемой биологической системе происходит что-то "патологическое", но доступные в настоящее время аналитические способы не являются достаточно чувствительными и специфичными для того, чтобы быть полезными для отдельного пациента. Проблемы, связанные с неточностью, превалирующие в данной области техники, являются следствием того, что современные аналитические меры (1) являются стохастическими (т.е. основанными на случайном изменении данных), (2) требуют стационарности (т.е. система, генерирующая данные, не может изменяться во время записи) и (3) являются линейными (т.е. не чувствительными к нелинейностям в данных, которые рассматриваются в данной области техники как "хаос"). Известны многие способы теоретического описания размерности, такие как "D0" (хаусдорфова размерность), "D1" (информационная размерность), "D2" (корреляционная размерность).D2 позволяет оценить размерность системы или количество ее степеней свободы из оценки образца сгенерированных данных. В некоторых исследованиях D2 была применена к биологическим данным. Однако было показано, что предположение о стационарности данных не может быть удовлетворено. Разработано другое теоретическое описание - поточечная масштабная размерность "D2i", которое является менее чувствительным к нестационарностям, присущим данным мозга, сердца или скелетной мускулатуры. Возможно, это более применимо для оценки размерности биологических данных, чем D2. Однако D2i все еще имеет значительные ошибки оценки, что может быть связано с нестационарностями данных. Разработан алгоритм точечной корреляционной размерности (PD2), который превосходит как D2,так и D2i при обнаружении изменений в размерности для нестационарных данных (т.е. данных, созданных стыковкой подпериодов от различных хаотичных генераторов). Разработан улучшенный PD2 алгоритм, обозначенный "PD2i", чтобы подчеркнуть его временную зависимость. Он использует аналитическую меру, которая является детерминированной и основана на обусловленных вариациях данных. Алгоритм не требует стационарности данных и действительно отслеживает нестационарные изменения данных. PD2i также является чувствительным к хаотичным, а также нехаотичным линейным данным. PD2i основан на предыдущих аналитических мерах, которые совместно представляют собой алгоритмы для оценки корреляционной размерности, но они не чувствительны к нестационарностям данных. Из-за такой особенности PD2i может прогнозировать клинические результаты с высокой чувствительностью и специфичностью, с которыми не могут прогнозировать другие критерии. Алгоритм PD2i более подробно описан в патентах США 5709214 и 5720294, включенных в настоящее описание во всей своей полноте в качестве ссылки. Для облегчения понимания ниже представлены краткое описание PD2i и сравнение этой меры с другими. Модель для PD2i представляет собой С(r, n, ref)r expD2, где ref представляет собой подходящую референсную точку, из которой строят различные m-мерные референсные вектора, поскольку они должны иметь область масштабирования максимальной длины PL, которая удовлетворяет критериям линейности (LC) и сходимости (СС). Поскольку каждый ref начинается с новой координаты в каждом из mмерных референсных векторов и поскольку эта новая координата может принимать любое значение,PD2i могут быть независимыми друг от друга с точки зрения задач статистики. Алгоритм PD2i ограничивает область небольших значений log-r, по которой рассчитываются линейное масштабирование и сходимость с использованием параметра, названного длиной графика. Значение этого элемента определяют для каждого log-log графика, начиная с малого log-r конца, процента точек, по которому осуществляют поиск области линейного масштабирования.-1 008979 В нестационарных данных небольшие log-r значения между фиксированным референсным вектором (i-вектором) в подпериоде, который представляет собой, например, синусоидальное колебание при вычитании из множества j-векторов, например в подпериоде Лоренца, нельзя построить множество небольших длин разностей векторов, особенно при более высоких вложенных размерностях. То есть не могут быть многочисленными небольшие разности векторов log-r относительно длин, которые могут быть построены, если j-вектор для подпериода Лоренца находится вместо этого в подпериоде синусоидального колебания. Если все разности векторов из нестационарных данных смешать вместе и упорядочить, только такие небольшие log-r значения между подпериодами, которые являются стационарными относительно содержащего референсный вектор, можно внести в область масштабирования, т.е. в область, для которой может быть выполнена оценка на линейность и сходимость. Если существует значимое искажение такой небольшой log-r области другими нестационарными подпериодами, то критерий линейности или сходимости не удовлетворяется, и такая оценка может быть устранена из PD2i значения. Алгоритм PD2i ввел в данную область техники идею того, что следует рассматривать наименьшую начальную часть области линейного масштабирования в случае, если существуют нестационарности (а они всегда имеются в биологических данных). Это происходит из-за того, что если j-вектора лежат в подпериоде данных, который представляет собой тот же вид, как и тот, в котором находится i-вектор (референсный вектор), то тогда, и только тогда, могут быть построены в большом количестве наименьшие logr вектора, т.е. в пределе или по мере того, как длина данных становится больше. Таким образом, для предотвращения загрязнения в корреляционном интеграле видами данных, которые не являются стационарными относительно видов, в которых находится референсный вектор, специалисты в данной области техники должны рассматривать только угловые коэффициенты корреляционного интеграла, которые лежат только на небольшом расстоянии за "гибким хвостом"."Гибкий хвост" представляет собой наименьшую область log-r, в которой отсутствует линейное масштабирование (изменение) вследствие недостатка точек в этой части корреляционного интеграла,вследствие конечной длины данных. Таким образом, путем запрета масштабирования PD2i для наименьшей части области log-r, упомянутой выше как "гибкий хвост", алгоритм PD2i становится не чувствительным к нестационарностям данных. Необходимо отметить, что D2i всегда использует всю область линейного масштабирования, которая всегда может быть загрязнена, если в данных присутствуют нестационарности. На фиг. 1 показан график log C(r, n, nref) как функции log-r. Это демонстрирует ключевую идею,лежащую в основе алгоритма PD2i. Она заключается в том, что, если присутствуют нестационарности данных, следует рассматривать только наименьшую начальную часть области линейного масштабирования. В данном случае данные были получены последовательным объединением 1200 точек подпериодов данных синусоидальной волны, данных Лоренца, синусоидальной волны, данных Эно, синусоидальной волны и случайного шума. Референсный вектор находился в подпериоде Лоренца. Для корреляционного интеграла, в котором вложенная размерность m=1, сегмент гибкого хвоста ("FT") устраняется критерием линейности LC=0,30; область линейного масштабирования для всего интервала (D2i) определяется длиной графика PL=1,00, критерий сходимости СС=0,40 и минимальное масштабирование MS=10 точкам. Область масштабирования, специфическая для вида, когда как I, так и j-вектора находятся в данных Лоренца (PD2i), устанавливается путем установки длины графика в PL=0,15 или меньше. Необходимо отметить, что при более высоких вложенных размерностях (например, m=12) после достижения сходимости углового коэффициента в зависимости от вложенной размерности угловой коэффициент сегментаPD2i отличается от углового коэффициента D2i. Это происходит, поскольку верхняя часть сегмента D2i(D2i-PD2i) загрязнена нестационарностью разности i-j векторов, где j-вектор находится в нестационарных видах данных относительно видов, в которых находится i-вектор. Такая оценка углового коэффициента для коротких расстояний для PD2i является вполне допустимой для любого log-log графика линейной области; причем не имеет значения, используются или нет для определения углового коэффициента все точки данных или используется только начальный сегмент. Таким образом, путем установки длины графика опытным путем в небольшом интервале выше "гибкого хвоста" (причем последний отсекается установкой критерия линейности LC) в данных могут быть отслежены с небольшими ошибками нестационарности, причем ошибки полностью являются следствием ограниченной длины данных, а не загрязнения нестационарностями. Таким образом, посредством подходящих корректировок в алгоритме для оценки только части области масштабирования, расположенной непосредственно выше "гибкого хвоста", которую определяют при помощи (1) критерия линейности, LC, (2) критерия минимального масштабирования, MS, и (3) критерия длины графика, PL, специалисты в данной области техники могут оценить чувствительность меры к нестационарностям данных."Прием" заключается в том, чтобы сделать j-вектора выходящими из тех же видов данных, в которых находится и i-вектор, и это может быть подтверждено эмпирически путем размещения графического маркера на i- и j-векторах и наблюдая маркеры в корреляционном интеграле. Такая начальная часть области масштабирования, с математической точки зрения, рассматривается как незагрязненная только в пределе, но, с точки зрения практики, это работает очень хорошо и для конечных данных. Это может-2 008979 быть подтверждено с помощью вычислений с последовательно стыкованными данными. Если PD2i применяется на последовательно стыкованных подпериодах данных, полученных при помощи Лоренц-, Энои других типов известных линейных и нелинейных генераторов данных, короткий сегмент масштабирования может содержать длины разностей векторов, полученных только посредством вычитания i- и jвекторов, которые являются стационарными относительно друг друга; т.е. обнаружено, что ошибки для подпериодов из 1200 точек меньше чем 5,0% от их значений в пределе и такие ошибки являются следствием конечной длины данных, а не загрязнения области масштабирования. На фиг. 1 В показано сравнение вычисления степеней свободы серий данных при помощи двух нелинейных алгоритмов, точечной корреляционной размерности (PD2i) и поточечной масштабной размерности (D2i). Оба этих алгоритма являются зависимыми от времени и являются более точными, чем классический D2 алгоритм, если используются для нестационарных данных. Большинство физиологических данных являются нелинейными из-за способа организации системы (механизм является нелинейным). Физиологические системы являются нестационарными по своей природе из-за неконтролируемой нервной регуляции (например, неожиданная мысль о чем-нибудь "ужасном" во время спокойного сеанса генерации данных сердечных сокращений). Нестационарные данные могут быть получены без шума путем стыковки отдельных серий данных,сгенерированных математическими генераторами, имеющими разные статистические свойства. Физические генераторы всегда имеют некоторый уровень шума. Данные, показанные на фиг. 1 В (Данные), получены из подпериодов синусоидального (S), Лоренца (L), Эно (Н) и случайного (R) математических генераторов. Серии данных являются нестационарными по определению, поскольку каждый подпериод(S, L, H, R) имеет разные стохастические свойства, т.е. разные стандартные отклонения, но одинаковые средние значения. Результаты PD2i и D2i, вычисленные для данных, показаны в двух записях ниже и сильно различаются. Алгоритм D2i является наиболее близким с PD2i алгоритмом сравнения, но он не устраняет небольшую область масштабирования log-r в корреляционном интеграле, как это происходит в случае PD2i. Именно такое ограничение масштабирования позволяет PD2i хорошо работать на нестационарных данных. Результаты PD2i, показанные на фиг. 1 В, с использованием параметров по умолчанию (LC=0,3,CC=0,4, Tau=1, PL=0,15) представлены для подпериодов даннымх с 1200 точками. Каждое среднее значение PD2i подпериода находится в пределах 4% известного среднего значения D2, вычисленного отдельно для каждого типа данных (используя более длинные последовательности данных). Известные значения D2 для данных S, L, Н и R составляют, соответственно, 1,00, 2,06, 1,26 и бесконечность. При взгляде на значения D2 заметны совершенно различные результаты (т.е. случайные результаты). Необходимо отметить, что D2i является наиболее близким к алгоритму PD2i, поскольку он также является зависимым от времени. Однако для D2i, так же, как и для D2, требуется стационарность данных. Для стационарных данных D2=D2i=PD2i. Только PD2i корректно отслеживает количество степеней свободы для нестационарных данных. Единственное значение D2, вычисленное для таких же нестационарных данных, аппроксимируется средними значениями приведенных значений D2i. Для анализа при помощи PD2i электрофизиологический сигнал усиливают (коэффициент усиления 1000) и оцифровывают (1000 Гц). Оцифрованный сигнал в дальнейшем может быть сжат (например, преобразованием данных ECG в данные интервала RR) до обработки. Было неоднократно показано, что анализ данных интервала RR позволяет предсказать риск в больших группах субъектов с различным патологическим исходом (например, фибрилляция желудочков "VF" или желудочковая тахиаритмия "VT"). Показано, что при использовании оцифрованных данных RR пациентов с высоким риском PD2i может отличить тех, которые позже будут подвержены VF, от тех, которые не будут подвержены VF. Для данных интервала RR, полученных из оцифрованной ECG, которая была получена с наилучшими предусилителями с низкими шумами и быстрыми 1000 Гц устройствами оцифровки, все еще присутствует низкий уровень шума, что может создать проблемы для нелинейных алгоритмов. Алгоритм,используемый для получения интервалов RR, также может привести к увеличенному шуму. Наиболее точные из детекторов RR интервалов используют 3-точечный скользящий "оператор выпуклости". Например, 3 точки в скользящем окне, которое проходит через все данные, могут быть подобраны таким образом, чтобы максимизировать его выходное значение, если оно точно охватывает с двух сторон пикаR-волны; точка 1 находится на базовой линии перед R-волной, точка 2 находится на вершине R-волны,точка 3 снова находится на базовой линии. Положение точки 2 в потоке данных корректно идентифицирует каждый пик R-волны при прохождении окна по данным. Такой алгоритм может генерировать значительно более свободные от шума данные RR, чем алгоритм, который определяет момент времени, когда R-волна пересекает определенный уровень или определяет момент достижения максимума dV/dt каждой R-волны. В наилучшим образом вычисленных при помощи алгоритмов RR-интервалов все еще присутствует низкий уровень шума, размах которого по наблюдениям составляет приблизительно +/-5 отсчетов. Такая область, составляющая 10 отсчетов, относится к 1000 отсчетам для усредненного пика R-волны (т.е. 1% шума). При некачественной подготовке электрода, сильных внешних электромагнитных полях, использовании предусилителей со скромными шумовыми характеристиками либо при использовании более-3 008979 низких скоростей оцифровки низкоуровневый шум может быть легко увеличен. Например, при коэффициенте усиления, при котором 1 отсчет=1 мс (т.е. при коэффициенте усиления, составляющем 25% всей шкалы 12-битового устройства оцифровки), этот наилучший уровень шума в 1% можно легко удвоить или утроить, если пользователь не относится к сбору данных с должным вниманием. Такое увеличение шума часто имеет место в условиях повышенной загрузки клиники, и, таким образом, после сбора данных должна быть проведена оценка уровня шума. Таким образом, существует необходимость в улучшенной аналитической мере, которая учитывает шум. Также существует необходимость в такой мере и в области медицины, например, для обнаружения биологических отклонений, например церебральных расстройств. Раскрытие изобретения Задачи, преимущества и отличительные особенности настоящего изобретения станут более понятными из нижеследующего описания, рассматриваемого совместно с прилагаемыми чертежами. Согласно иллюстративным вариантам осуществления производят обнаружение и/или прогнозируют биологические отклонения путем анализа входных биологических или физических данных, используя процедуру обработки данных. Процедура обработки данных включает в себя набор параметров приложения, связанных с биологическими данными и коррелирующих с биологическими отклонениями. Процедура обработки использует алгоритм для генерации серий данных, например серий данных PD2i, которые используются для обнаружения или предсказания появления биологических отклонений. Согласно одному из аспектов настоящего изобретения для уменьшения шума в сериях данных устанавливают заданную величину углового коэффициента, например ноль, если он меньше, чем заданное значение, например 0,5. Согласно другому аспекту настоящего изобретения определяют шумовой интервал внутри серий данных и если шумовой интервал лежит в заданной области, то серии данных делят на другое заданное число, например 2, и для серий данных генерируют новые значения. Согласно иллюстративным вариантам осуществления уменьшение шума в сериях данных улучшает обнаружение/прогнозирование биологических отклонений, таких как аритмия сердца, церебральный эпилептический припадок и ишемия миокарда. Способ и устройства настоящего изобретения также могут быть использованы для обнаружения и прогнозирования появления нарушений мозга, таких как прионовые заболевания человека (болезнь Якоба-Крейтсфельда) и различные деменции (сердечно-сосудистые, травматические, генетические), включая болезнь Альцгеймера. Способы настоящего изобретения также могут быть использованы для обнаружения и прогнозирования появления губкообразной энцефалопатии крупного рогатого скота, почесухи овец и акобальтоза оленей. Краткое описание чертежей На фиг. 1 А показан график log С(r, n, nref) в зависимости от log-r для известного алгоритма PD2i. На фиг. 1 В показан график, иллюстрирующий вычисление степени свободы (размерностей) при помощи двух алгоритмов, зависящих от времени, при их использовании для нестационарных данных без шума. На фиг. 2 А и 2 В показано выполнение PD2i, если к нестационарным данным добавляют низкоуровневый шум. На фиг. 3 показана оценка низкоуровневого шума в двух наборах RR-интервалов, полученных из двух цифровых ЭКГ. На фиг. 4 А-F показан низкоуровневый шум (вставки) в RR-интервалах пациентов контроля с острым инфарктом миокарда. На фиг. 4G-L показан низкоуровневый шум в RR-интервалах пациентов, умерших от аритмии. На фиг. 5 А показана иллюстративная блок-схема последовательности операций, иллюстрирующая логику NCA, примененной к данным ЭКГ в кардиологии. На фиг. 5 В показана иллюстративная блок-схема последовательности операций, иллюстрирующая логику NCA, при применении к данным ЭЭГ и связанным концепциям в нейрофизиологии. На фиг. 6 показана иллюстративная блок-схема последовательности операций для NCA, реализованная в программном обеспечении согласно иллюстративному варианту осуществления. На фиг. 7 показано PD2i сердечных сокращений (RR) пациента с ранней деменцией, которая была подтверждена только 10 годами позже, в сравнении с PD2i сердечных сокращений пациента такого же возраста. На фиг. 8 показана связь PD2i сердечных сокращений у коровы на ранней и поздней стадии губкообразной энцефалопатии крупного рогатого скота (BSE). Осуществление изобретения Согласно иллюстративному варианту осуществления был разработан способ для исключения вклада низкоуровневого шума в нелинейные аналитические меры, такие как PD2i. Для лучшего понимания важности шума обратимся к фиг. 2 А и 2 В. На фиг. 2 А и 2 В данные представляют собой такие же S, L, Н и R данные, как и описанные со ссылкой на фиг. 1 В. По определению,эти данные не имеют никакого шума, поскольку их генерация выполнена при помощи математических-4 008979 генераторов. На фиг. 2 А в серии нестационарных данных добавили 5 отсчетов низкоуровневого шума. Средние значения PD2i для каждого подпериода существенно не изменились, хотя из 1200 точек данных в каждом подпериоде имеется несколько больших значений. Однако, как показано на фиг. 2 В, добавление 14 отсчетов шума приводит к случайным PD2i значениям, средние значения которых являются приблизительно такими же. Согласно иллюстративным вариантам осуществления NCA (алгоритм принятия в расчет шума) оценивает шум низкого уровня при сильном увеличении (например, ось у составляет полную шкалу из 40 отсчетов, ось х составляет полную шкалу из 20 сердечных сокращений) и определяет, присутствует или нет шум за пределами заданной области, например превышает ли динамический диапазон шума 5 отсчетов. Если это верно, то серии данных делят на целую величину, посредством чего возвращают шум в область 5 отсчетов. В этом примере серии данных могут быть разделены на 2, поскольку только младший бит 12 битных данных содержит шум. Поскольку область линейного масштабирования корреляционного интеграла, вычисленную при вложенных размерностях, меньших чем m=12, может иметь угловые коэффициенты меньше 0,5, если он получен из низкоуровневого шума (например, с динамическим диапазоном 5 отсчетов), не существует способа различить низкоуровневый шум и реальные данные с малым угловым коэффициентом. Поскольку угловые коэффициенты меньше 0,5 редко встречаются в биологических данных, то алгоритмическая установка любых угловых коэффициентов от 0,5 и меньше (наблюдаемых в корреляционном интеграле) в ноль позволяют устранять обнаружение этих небольших естественных угловых коэффициентов, и это также устраняет вклад низкоуровневого шума в значения PD21. Это именно тот "алгоритмический феномен", который объясняет опытные данные и отвечает за отсутствие влияния шума в интервале между -5 и 5 при добавлении к данным без шума (фиг. 2 А). Шум с немного большей амплитудой, однако, показывает ожидаемые шумовые эффекты, которые ожидаются для нелинейных алгоритмов (например, фиг. 2 В). Исходя из применения в физиологических данных, теперь понятно, что низкоуровневый шум должен всегда учитываться и таким-то образом удерживаться в заданной области, например в пределах 5 отсчетов или в любой другой области, которая, основываясь на опытных данных, определена как подходящая для этого. Такой способ рассмотрения может предотвратить случайное увеличение PD2i для данных с низкой размерностью (т.е. данных с немногими степенями свободы), как показано на фиг. 2 В. Доказательство данной концепции лежит в ее простом объяснении ("алгоритмический феномен"), но, возможно, даже более убедительным являются опытные данные, которые поддерживают использованиеNCA. Такие данные будут представлены ниже. Верхняя часть фиг. 3 показывает клинические данные RR-интервалов пациента, который умер от аритмии (АС). Небольшой сегмент из 20 сердечных сокращений данных RR-интервалов увеличен и показан в нижней части фиг. 3. Линейная регрессия показывает медленное изменение сигнала в сегменте данных, тогда как пилообразные изменения вверх и вниз представляют шум. И ЭКГ, и RR аналогичны, но результаты более подробного рассмотрения данных (20 сердечных сокращений, ось у составляет 40 отсчетов) показывают, что одни данные имели изменения, находящиеся в пределах 5 отсчетов (ОK), а другие - в пределах 10 отсчетов (слишком большой). Если сегмент с большей амплитудой ("слишком большой") не будет идентифицирован и откорректирован, то PD2i значения могут иметь больший случайный разброс, как на фиг. 2 В. Следствием такого увеличенного случайного разброса PD2i значений является то, что тест, основанный на PD2i, может выдать ошибочный клинический прогноз о подверженности сердца пациента летальной аритмогенности. Согласно иллюстративным вариантам осуществления сегмент с большей амплитудой, подобный показанному на фиг. 3 (слишком большой), может быть идентифицирован и откорректирован с использованием алгоритма, учитывающего шум (NCA). В табл. 1-4 приведены клинические данные, полученные в качестве части исследований в поддержку концепции NCA. Целью исследований, представленных в табл. 1-4, было прогнозирование случая аритмии сердца (АС) из двух тестов PD2i, выполненных на цифровой ЭКГ каждого пациента. При исследовании в приемном отделении 320 пациентов с проявлением боли в груди, которые были определены как имеющие высокий кардиологический риск по протоколу Гарвардской Медицинской Школы, приблизительно 1 из 3 пациентов нуждался в применении NCA для предоставления осмысленных данных. Если бы не было разработано и применено NCA, то данные, полученные от пациентов, могли бы быть бессмысленными в тех случаях, где низкоуровневый шум был достаточно большим. Табл. 1 А представляет собой таблицу контингентности предсказанных АС результатов (т.е. истинно положительный, истинно отрицательный, ложноположительный и ложноотрицательный) и статистику относительного риска (Rel) для набора данных, проанализированного с помощью нескольких нелинейных детерминированных алгоритмов (Pd2i, DFA, 1/f-Slope, ApEn). Табл. 1B представляет собой таблицу контингентности предсказанных AD результатов и Rel для набора данных, проанализированных более привычными линейными стохастическими алгоритмами (SDNN, meanNN, LF/HF, LF(ln. В табл. 1 А и 1 В показано сравнение алгоритмов HRV у 320 пациентов (N) с высоким риском, с про-5 008979 явлением боли в груди в приемном отделении, и имеющих оцененный риск острого ИМ 7%. Для всех пациентов была записана ЭКГ и проводилось последующее 12-месячное полное врачебное наблюдение. Установленные случаи смерти от аритмии сердца показаны как истинное или ложное предсказания (Т или F) в положительных или отрицательных HRV тестах (Р или N). В таблице использованы следующие аббревиатуры: SEN=чувствительность (%); SPE=специфичность (%); REL=статистика относительного риска; SUR=отклонение по косвенным показателям; OUT=отклонение резко отклоняющихся значений(3 SD); АF=отклонение по критерию наличия мерцания предсердий. Таблица 1 А Нелинейные детерминированные алгоритмы р 0,001; тест биномиального распределения; альфа-защита множественного теста (требуемый уровень альфа в 8 раз меньше); разложение (P+Q)n x 8-кратной защиты подразумевает р=0,00016, которое удовлетворяет р 0,001; также р 0,001 по точному критерию Фишера для связи строка-столбец в таблице контингентности 2x2; все другие являются незначимыми по тесту биномиального распределения. р 0,001 - только точный критерий Фишера; т.е. незначим по тесту биномиального распределения. РD2i=точечная корреляционная размерность (положительный при минимуме PD2i1,4 размерностей, с систематическим сдвигом для низких размерностей на более чем 12 PD2i значений); случаи отклонений по косвенным показателям (SUR) идентичны случаям FN33%.DFA-OUT=анализ флуктуаций с исключенным трендом (1 [короткий терм] является положительным, если находится вне нормальной области от 0,85 до 1,15); отклонения по косвенным показателямSDNN=стандартное отклонение для нормальных сердечных сокращений (положительное, при 65 мс; для положительного, если 50 мс, ТР=17). МNN=среднее значение нормальных RR-интервалов (положительное, при 750 мс).LF/HF=мощность на низких частотах (от 0,04 до 0,15 Гц)/мощность на высоких частотах (от 0,15 до 0,4 Гц) (положительное, 1,6).LF(ln)=мощность на низких частотах (от 0,04 до 0,15 Гц), нормализованная на натуральный логарифм (положительная, 5,5). Этот пациент с АС умер на 79-й день, и FN может быть неистинным; цифровая ЭКГ была записана до двух нормальных клинических ЭКГ с последующей третьей положительной ЭКГ (т.е. пациент мог быть классифицирован как "развивающийся острый ИМ", который мог иметь TN во время записи ЭКГ). Как можно видеть из представленных данных в табл. 1 А и 1 В, только алгоритм PD2i имел стати-6 008979 стически значимые показатели чувствительности, специфичности и относительного риска в указанной выборке приемного отделения. В табл. 2 показана статистика относительного риска для различных подгрупп пациентов с заболеванием сердца с высоким риском. Из данных, представленных в табл. 2, очевидно, что PD2i работает лучше всего. В табл. 2 показан относительный риск для алгоритмических прогнозов смерти от аритмии у 320 пациентов с заболеванием сердца с высоким риском в приемном отделении. Таблица 2 р 0,001, р 0,05, точный критерий Фишера для связи строки и столбца в таблице контингентности 2x2; знакозначает, что RR стремится к бесконечности, поскольку FN=0; для приведенного значения использован FN=1. Относительный риск = истинно положительно/ложноотрицательно х [ложноотрицательно + ложноотрицательно/истинно положительно + ложноотрицательно]. В табл. 3 приведены результаты PD2i прогнозирования аритмии сердца у 320 пациентов с заболеванием сердца с высоким риском в приемном отделении, с применением NCA к данным RR-интервала и без его применения. Таблица 3 р 0,001 Статистически незначимо. В табл. 3 показано, каким образом применение и неприменение NCA может изменить результат исследования статистики относительного риска. Без учета шума PD2i не имело бы такую поразительную эффективность прогнозирования, и никакой другой алгоритм не мог бы дать лучше результаты. В табл. 4 показан другой PD2i критерий измерения, который также хорошо работает при прогнозировании АС. В табл. 4 показан процент всех значений PD2i между степенями свободы от 3 до 0 (размерности) для 6 пациентов, умерших от аритмии, причем каждый из них умер в течение 80 дней после записи ЭКГ, и их соответствующий контроль, каждый из которых имел зарегистрированный острый инфаркт миокарда, но не умер в течение 1 года последующего наблюдения. Средние значения двух групп являются высоко статистически значимыми (P0,0000001, t-критерий). Табличные значения обусловлены чрезмерными эктопическими систолами, которые привели к образованию некоего масштабирования в области от 3 до 0. Р 0,000001, t-критерий; все субъекты с АС соответствовали PD2i1,4 LDE и 0PD2i3 критерию; чувствительность=100%, специфичность=100%. Как можно видеть из табл. 4, у пациентов с заболеванием сердца с высоким риском, которые не умерли (отрицательный тест), большинство их PD2i был выше 3 размерностей (степеней свободы). У тех пациентов, которые умерли (положительный тест), большинство их PD2i находилось ниже 3 размерностей. Такой критерий %PD2i3 полностью отделяет пациентов с АС от их соответствующих контролей с острым инфарктом миокарда, не умерших от АС (чувствительность=100%; специфичность=00%). Эти результаты также полностью зависят от применения NCA для недопущения перекрытия распределений и обеспечения чувствительности и специфичности на уровне 100%. Те субъекты, у которых был удален бит, содержащий шум, т.е., поскольку низкоуровневый шум в их RR-интервалах был слишком высоким,обозначены -n в конце названия файла. Критерий PD2i для прогнозирования смерти от аритмии Каждая из вышеуказанных табл. 1-4 основана на наблюдении отклонений с низкой размерностью(LDE) при PD2i, составляющем 1,4 или ниже. То есть PD2i1,4 являлся критерием прогнозирования АС. При применении этого критерия отсутствовали ложноотрицательные прогнозы (FN). Случай FN является проклятием медицины, поскольку пациенту говорят: "Все в порядке", но затем, придя домой, он умирает от АС через несколько дней или месяцев. Ложноположительные случаи являются ожидаемыми в боль-8 008979 шом количестве, поскольку выборка представляет собой группу с большим риском, имеющую пациентов с острым инфарктом миокарда, мономорфными эктопическими очагами и другими диагнозами с высоким риском. Такие пациенты с положительным тестом, безусловно, находятся в группе риска и должны быть госпитализированы, но они не умрут, возможно, вследствие применения лекарств или хирургического вмешательства, которое будет выполнено в больнице. Другими словами, классификация FP не является "анафемой" для медицины. Действительно значимым для применения PD2i к таким ER пациентам является то, что 1) все АС происходили у пациентов с положительным тестом и 2) 51% пациентов с отрицательным тестом могли быть безопасно выписаны из больницы, поскольку никто из них не умер в период последующего наблюдения в течение года. Все эти клинические результаты являются значимыми, но они полностью зависят от применения NCA для сохранения чувствительности и специфичности на уровне 100% и хорошего показателя относительного риска. На фиг. 4 А-4L приведены критерии PD2i1,4 для случаев LED и %PD2i33, которые бы существенно изменились в случае неприменения NCA в некоторых случаях (NCA). Хотя они являются соотнесенными друг с другом, применение обоих критериев для данных, проанализированных с применениемNCA, возможно, является наилучшим и самым универсальным способом прогнозирования АС среди пациентов с высоким риском. Такая комбинация сохраняет статистическкую чувствительность и специфичность на уровне 100%, как это видно для пациентов с АС и их контроля с острым ИМ (табл. 4; фиг. 4 А-4L). На фиг. 4A-4F показан низкоуровневый шум в RR-интервалах у 6 пациентов контроля с острым инфарктом миокарда (острый ИМ), а на фиг. 4G-L показан низкоуровневый шум в RR-интервалах 6 пациентов с аритмией сердца (АС). Длинный сегмент на каждой диаграмме представляет все RR-интервалы за 15 мин ЭКГ. Короткий сегмент показывает записи низкоуровневого шума из небольшого сегмента из 20 сердечных сокращений с большим усилением. Таким образом, на каждой диаграмме шум наложен на более высокую динамическую активность. Все усиления одинаковы для всех субъектов (длинная RR запись=500-1000 отсчетов; короткая RR запись=0-40 отсчетов). Для тех субъектов, у которых область шума оценивалась как превышающая 5 отсчетов (1 мс=1 отсчету), был применен алгоритм учета шума (NCA) до вычисления PD2i. Таким образом, например, NCA был применен для субъектов контроля, представленных на фиг. 4 В, 4 С и 4F, и для субъектов с АС, представленных на фиг. 4K и 4L. Значения PD2i, соответствующие каждому RRi, отображены на шкале от 0 до 3 размерностей (степеней свободы). Для субъектов с АС, как показано на фиг. 4G-4L, многие значения PD2i находятся ниже 3,0. В табл. 4 показано, что для всех субъектов среднее количество PD2i ниже 3,0 составляет 83%. Результаты прогнозируемости для клинических данных не были бы статистически значимыми без учета содержания шума в данных. NCA, использованный во всех указанных выше приложениях, включал в себя 1) исследование, находится или нет динамический диапазон шума вне интервала 10 отсчетов,и затем, если это имеет место 2) достаточное уменьшение амплитуды RR для устранения избыточного шума. NCA потребовался приблизительно для 1/3 всех субъектов. Вместо умножения каждой точки данных на значение, для уменьшения динамического диапазона шума, ниже 10 отсчетов, умножение производилось на коэффициент 0,5 (т.е. удалялся 1 бит из 12-битных данных). Все применения NCA были выполнены слепым способом в отношении данных результата (смерть от аритмии была определена только после завершения анализа PD2i с NCA). Эта процедура исключает вероятность систематической ошибки оценки исследователя и является необходимой при статистическом анализе. Согласно иллюстративному варианту осуществления алгоритм учета шума, описанный выше, может быть реализован в виде программного обеспечения. Определение интервала шума может быть сделано визуально на основании данных, отображенных, например, на мониторе компьютера. Данные могут быть отображены с фиксированным увеличением, например 40 отсчетов для полной шкалы, центрированной относительно среднего значения отображенного сегмента. Если значения находятся внутри области 5 отсчетов, пользователь может принять решение разделить серии данных на заданное значение,либо деление может выполняться автоматически. На фиг. 5 показана иллюстративная блок-схема последовательности операций для NCA, примененного к данным ЭКГ. Согласно иллюстративному варианту осуществления ЭКГ субъекта была принята при помощи обычного усилителя, оцифрована и затем загружена в качестве входных данных в компьютер для анализа. Сначала из данных ЭКГ получили RR и QT интервалы; затем их проанализировали с помощью программного обеспечения PD2i (PD2-02.exe) и программного обеспечения QTvsRR-QT(QT.exe). Согласно иллюстративным вариантам осуществления NCA применялся к двум точкам, например, в качестве элемента выполнения программного обеспечения PD2i и QTvsRR-QT и после выполнения программного обеспечения PD2i и QTvsRR-QT. Например, NCA может быть применен во время выполнения программного обеспечения PD2i и QTvsRR-QT таким образом, что угловой коэффициент графика logc(n, r, nref) в зависимости от log r устанавливается в 0, если угловой коэффициент меньше чем 0,5 и-9 008979 больше чем ноль. Также NCA может быть применен после выполнения программного обеспечения PD2i и QTvsRR-QT для деления серий данных PD2i на заданное целое число, если низкоуровневый шум находится вне заданного интервала, например вне интервала от -5 до 5. При выполнении такого деления вычисление PD2i снова повторяется для поделенных данных при помощи выполнения программного обеспечения PD2i и QTvsRR-QT. После завершения выполнения программного обеспечения PD2i и QTvsRR-QT вычисляется и отображается точечная корреляционная размерность как функция времени. Также строят и отображают график QT в зависимости от RR-QT. Затем готовят графические отчеты для оценки риска. Оцифрованная ЭКГ может быть загружена для хранения. Вышеприведенное описание в большей степени имеет отношение к улучшению обнаружения/прогноза обнаружения детерминированных отклонений с низкой размерностью в нестабильных интервалах сердцебиений, полученных из данных ЭКГ, в качестве предвестника фатальной аритмии сердца. Вышеприведенное описание также относится к улучшению обнаружения динамик Qt в зависимости от RR-QT для подинтервалов сердечных сокращений, совместно нанесенных на график, в ранее рассмотренной области отклонения в качестве предвестника фатальной динамической аритмии сердца. Однако следует принять во внимание, что настоящее изобретение также применимо для улучшения обнаружения/прогноза других биологических отклонений с использованием, например, данных электроэнцефалограммы(ЭЭГ). Например, NCA может быть применим для улучшения обнаружения устойчивых отклонений при детерминированных размерных реконструкциях, полученных из нестационарных данных ЭЭГ в качестве меры измененного когнитивного состояния. NCA также может быть применим для улучшения обнаружения увеличенной изменчивости детерминированных вариаций размерности в потенциалах ЭЭГ в качестве предвестника ранней пароксизмальной эпилептической активности. На фиг. 5 В показана иллюстративная реализация алгоритма NCA для пациента с эпилепсией или нормального субъекта, для которых проводится анализ мозга. Данные ЭЭГ субъекта получены при помощи обычного усилителя, оцифрованы и затем загружены в качестве входных данных в компьютер для анализа. Затем выполнялось программное обеспечение PD2i.exe (PD2-02.eхе), при необходимости устанавливающее угловой коэффициент, например, в 0. Затем, если низкоуровневый шум находится вне заданного интервала, серии данных PD2i делили на заданное число и повторяли вычисление PD2i для поделенных данных снова, выполняя программное обеспечение PD2i и QTvsRR-QT. Затем строят график точечной корреляционной размерности и готовят графические отчеты для анализа местоположения эпилептического очага и/или изменения когнитивного состояния.NCA может быть реализован, например, на микрокомпьютере. Хотя показаны в виде отдельных элементов, один или все элементы, показанные на фиг. 5 А и 5 В, могут быть реализованы в ЦПУ. Хотя представленное выше описание, в основном, сфокусировано на оценке данных ЭКГ и ЭЭГ,следует принять во внимание, что возможны другие аналогичные варианты применения настоящего изобретения. Источник электрофизиологического сигнала может быть другим, и структура графического отчета (отчетов) может быть специфичной для данных медицинских и/или физиологических объектов. Все виды анализа могут использовать алгоритм PD2i и NCA в форме программного обеспечения и могут сопровождаться другими видами подтверждающего анализа. Настоящее изобретение также предоставляет способ обнаружения или предсказания появления церебрального нарушения, содержащий этапы, на которых анализируют входные биологические или физические данные, используя процедуру обработки данных, включающие в себя набор параметров приложения, связанных с биологическими данными, коррелирующими с церебральным нарушением, для генерации серий данных, определяют, является ли угловой коэффициент для серий данных меньше заданного значения; если угловой коэффициент меньше заданного значения, устанавливают угловой коэффициент в заданное значение; и используют серии данных для обнаружения или прогноза появления церебрального нарушения. На фиг. 6 показана блок-схема последовательности операций, иллюстрирующая процесс, в которомNCA может быть реализован в виде программного обеспечения согласно иллюстративному варианту осуществления. Последовательность операций начинается со сбора данных. Из данных получают вектораi и j и вычитают друг из друга (i-j DIFF). Значения разностей этих векторов вводят, согласно их значению(X, от 1 до 100), в MXARAY для использованной вложенной размерности (m, от 1 до 12). Ввод данных производят в виде увеличения значения счетчика в каждой позиции MXARAY. После завершения получения значений разностей векторов значения счетчика (3, 7, 9, 8, 2, 6, 7, 4) используются для получения корреляционных интегралов для каждой вложенной размерности; это делается путем создания совокупной гистограммы как функции X, для каждого m.sub.1, и затем получают график log-log их совокупных значений (например, график log C(n, r) в зависимости от log r). Из совокупной гистограммы получают данные log-log, нанесенные на график корреляционного интеграла для каждой вложенной размерности (m). Затем корреляционный интеграл анализируют по пяти критериям. Сначала определяют, является ли угловой коэффициент меньшим 0,5. Если угловой коэффициент меньше 0,5, его устанавливают в 0. Затем находят самую длинную область линейного масштабирования, которая удовлетворяет критерию ли- 10008979 нейности (LC). Это выполняют путем оценки каждого корреляционного интеграла при помощи LC для нахождения самого длинного сегмента второй производной, который попадает в пределы установленных параметров (LC=0,30 означает значения в пределах отклонения от +15% до -15% от среднего угла наклона); такой итерационный LC тест обнаруживает область выше "гибкого хвоста" (например, наименьшая область log-r, которая нестабильна из-за конечной длины данных) и выполняет корреляционный интеграл до тех пор, пока не будет превышен LC критерий (выделенная секция сверху корреляционного интеграла). Затем выполняют определение, удовлетворяет ли сегмент критерию длины графика (PL). Если это так, то область масштабирования корреляционного интеграла переопределяют на критерий PL; это значение определяют из наименьшей точки данных в корреляционном интеграле для ее значения критерия(например, 15%, скобка во втором сверху корреляционном интеграле). Исследуют верхние и нижние границы этой области, чтобы определить, имеют ли они наименьшее количество точек данных, требуемых критерием минимального масштабирования (MS), например 10. Выбранные области всех корреляционных интегралов (от m-1 до m=12) наносят на график и анализируют при помощи СС, чтобы увидеть,имеется ли сходимость для больших вложенных размерностей (например, от m=9 до m=12); то есть определяют, имеют ли выбранные области, по существу, такие же угловые коэффициенты, для которых стандартное отклонение от среднего значения находится в пределах, установленных при помощи СС (т.е. средние значения СС=0,40, у которых отклонение от среднего значения находится в пределах от +20% до-20% среднего значения). Если критерий СС проходит, то средний угловой коэффициент и стандартное отклонение сохраняют в файле и, например, отображают. Наконец, пользователем выполняется оценка низкоуровневого шума, чтобы определить, находится ли динамическая область за пределами интервала от -5 до +5. Если это так, то бит шума удаляют из файла данных (например, значение каждой точки данных делят на 2) и модифицированный файл затем вычисляют повторно, отображают и сохраняют. Если происходит ошибка в любом из критериев (LC, PL, MS), то программа выполняет выход и перемещает референсный вектор PD2i к следующей точке данных, и процедура повторяется. Если ошибка происходит в СС, среднее значение и стандартное отклонение сохраняют без выхода, поскольку может оказаться, что позже СС потребуется изменить; т.е. СС является фильтром, который определяет, будет или нет PD2i (т.е. средний угловой коэффициент от m=9 до m=12) изображен позднее графическими подпрограммами. Примеры Автором настоящего изобретения были исследованы степени свободы HRV, и обнаружено, что у людей с сердечными трансплантатами (4) изменения сердцебиения были очень регулярными и чрезвычайно слабыми. Нелинейный анализ HRV у таких носителей трансплантатов показал степень свободы только 1,0. Напротив, у нормальных субъектов изменения степеней свободы составляли от 3 до 5. Эти результаты на денервированном сердце подтверждают, что именно задаваемая мозгом нервная активность в сердце, в первую очередь, генерирует HRV. Нелинейный анализ динамик сердечных сокращений представляет собой чувствительный детектор лежащих в основе динамик. Он может четко обнаруживать восприимчивость к летальному аритмогенезису, в отличие от других мер HRV (5). Он также может обнаруживать изменения в регуляторных нейронах, когда регулировать интервалы сердечных сокращений способна только собственная сердечная нервная система (6, 7), а также если задействованы более высокоуровневые когнитивные системы, задействующие лобные доли (8).HRV и когнитивная функция Связь HRV и когнитивной функции и повседневной жизненной активности у пожилого человека не ясна (9). Было обнаружено, что общая мощность HRV (т.е. LF и отношение LF/HF спектральной плотности мощности) HRV является существенно более низкой в подгруппе пожилых субъектов с деменцией,чем в норме (9). Следовательно, возраст сам по себе не связан с уменьшением в HRV. Скорее, этот результат подтверждает исследование денервации, которое показало, что именно отсутствие проекции на сердце высокоуровневой нервной активности вызывает снижение HRV. Важно знать, в какой момент при прогрессирующей общей нервной симптоматике действительно начнет изменяться HRV. Изменение в амплитуде или осцилляторной мощности вариаций, что включает в себя эквивалент общей нервной вовлеченности рассечения нисходящих нервов, может представлять собой отдаленный результат, причем не очень полезный с точки зрения медицины. Возможно, более тонкие изменения происходят на ранней стадии процесса, что улавливается изменениями в степенях свободы. Очень вероятно, что ранняя общая симптоматика, как при начальной стадии BSE и/или болезни Альцгеймера, влияет на общее количество нейронов, и, таким образом, количество степеней свободыHRV может значительно уменьшаться. Если это имеет место, то такая нелинейная мера HRV может быть предвестником того, что в результате спустя 10 лет приведет к болезни. Был исследован один пожилой субъект, SGW. Указанный субъект обладал хорошим здоровьем (играл в теннис 3 раза в неделю) и не имел когнитивных нарушений. Хотя этот субъект имел некоторые незначительные затруднения в процессе вспоминания не имеющих к нему прямого отношения имен (например, авторов различных опубликованных рукописей), безусловно, отсутствовали другие признаки- 11008979 потери краткосрочной или долговременной памяти или какое-либо указание на деменцию. Однако HRV этого субъекта был в указанное время существенно сниженным в пределах значений размерностей между 2,0 и 1,0. Такое уменьшение в нелинейной размерности (степенях свободы), очевидно, не является случаем, связанным с возрастом регуляции, значения которой находятся в пределах между 5 и 3 Б в той же самой области, что и у других более молодых нормальных субъектов. Различие в средних значенияхPD2i между SGW и нормой соответствующего возраста имело высокий уровень статистической достоверности (t-критерий, р 0,001). Наиболее важным наблюдением в этом 10-летнем исследовании было то,что по прошествии 10 лет указанный субъект (SGW) обнаружил тяжелую потерю кратковременной памяти и тяжелую деменцию (фиг. 7). Это объясняется тем, что тоническое уменьшение в степенях свободы (размерности) HRV является долговременным показателем возникновения деменции. Такой же механизм может работать при обнаружении губкообразной энцефалопатии крупного рогатого скота на его ранних стадиях и подобных заболеваний человека, вызываемых прионами (болезнь Якоба-Крейтсфельда), которым для развития также требуется 10 лет. Алгоритм спектральной плотности мощности, использованный для оценки HRV в предыдущих исследованиях, исходил из линейной стохастической модели, что, в свою очередь, требует, чтобы вариации в дыхательной регуляции были распределены случайным образом вокруг среднего значения и представляли собой серии стационарных данных. В таких сериях физиологических данных ни одно из этих предположений не является валидным, поскольку любое поведение может интерферировать с дыханием и генерировать нелинейные и нестационарные изменения в данных. Заявителем показано, что нелинейный алгоритм, точечная корреляционная размерность (PD2i), который основан на нелинейной детерминистической модели, решает проблему нестационарных данных. Он способен точно отследить изменения в степенях свободы вариаций в сериях нестационарных данных(10). Спектральная плотность мощности, использованная в вышеупомянутых исследованиях (1), требует стационарности данных, что является маловероятным для животных с осознанным поведением. При применении алгоритма PD2i в клинических исследованиях изменчивости частоты сердечных сокращений у пациентов с высоким риском заболеваний сердца алгоритм PD2i существенно превосходил при прогнозировании смерти от аритмии другие алгоритмы, обычно используемые в данной области (11,12), включая спектральную плотность мощности. Настоящее изобретение показывает, что уменьшение PD2i для изменчивости сердечных сокращений у людей прогнозирует прогрессирующее нарушение мозга в случае церебральной деменции. Такая же нелинейная мера сердечных сокращений может аналогично прогнозировать прогрессирующее заболевание мозга у животных, особенно у крупного рогатого скота, инфицированного губкообразной энцефалопатией крупного рогатого скота. Показано, что регуляция мозгом сердечных сокращений приводит к более высоким размерностям PD2 (4). Помимо этого, раскрыто, что при развитии энцефалопатии она может иметь количественную связь с уменьшением размерности PD2i (фиг. 8). Такая же прогнозируемость может быть использована для обнаружения широко распространенных церебральных нарушений у людей на ранней стадии, включая, без ограничений, прионовые болезни человека (болезнь Крейтцфельда-Якоба) и различные деменции (сердечно-сосудистые, травматические, генетические), включая болезнь Альцгеймера. Технология также может работать для подобных или аналогичных заболеваниях у животных, включая, без ограничений, губкообразную энцефалопатию крупного рогатого скота, почесуху овец, акобальтоз оленей. Причина того, что изменчивость интервала сердечных сокращений кодирует физиологическую патологию на начальной стадии прогрессирующих общих нарушений, заключается в том, что она является мерой "кооперативного эффекта" (10) для различных афферентно-эфферентных петель, конкурирующих при управлении сердечными сокращениями. Такие афферентно-эфферентные петли проходят от внутренней нервной системы, полностью расположенной в сердце (6, 7), до петель, которые проходят через лобные доли (8). Таким образом, данная технология учитывает все уровни центральной нервной системы, а также периферической нервной системы при автономной регуляции сердечных сокращений. Точность, присущая алгоритму PD2i при количественном описании изменений в HRV, является результатом того, что он основан на нелинейной детерминистической модели и учитывает проблему нестационарности данных. Поскольку настоящее изобретение описано со ссылкой на конкретные варианты осуществления,могут быть сделаны модификации и изменения настоящего изобретения без отступления от объема настоящего изобретения. Например, хотя NCA описан в приложении к сериям данных PD2i, очевидно, чтоNCA также может быть полезным в уменьшении шума в алгоритмах другого типа, например D2, D2i,или любом другом алгоритме прогнозирования. Необходимо понять, что вышеприведенное описание и сопровождающие его чертежи представляют собой только иллюстрацию. Возможно множество модификаций, которые не выходят за пределы объема и сущности настоящего изобретения. Вышеприведенное описание следует рассматривать только в качестве примера, и оно не предназначено для ограничения настоящего изобретения каким-либо способом.- 12008979 На всем протяжении данного приложения приводятся ссылки на различные публикации. Раскрытия этих публикаций включены в настоящее описание во всей своей полноте в качестве ссылки для более полного описания уровня техники. Упомянутые публикации также включены в настоящее описание в качестве ссылки в отношении материала, содержащегося в них и обсуждаемого в предложении, к которому относится эта ссылка. Список цитированной литературы 1. Pomfrett, C.J.D., Austin, A.R. Bovine spongiform encephalopathy (BSE) disrupts heart rate variabilityNonlinear Techniques in Physiological Time Series Analysis, Springer, New York, 1-37. ФОРМУЛА ИЗОБРЕТЕНИЯ 1. Способ обнаружения или прогнозирования биологических отклонений, содержащий этапы, на которых: анализируют входные биологические или физические данные, используя процедуру обработки данных с использованием алгоритма PD2i, причем упомянутые данные включают в себя набор прикладных параметров, связанных с биологическими данными, коррелирующими с биологическими отклонениями для генерации серий данных; определяют, является ли угловой коэффициент серий данных меньше заданного значения; если угловой коэффициент меньше заданного значения, устанавливают заданную величину углового коэффициента и используют серии данных для обнаружения или прогнозирования появления биологических отклонений. 2. Способ обнаружения или прогнозирования церебральных нарушений, содержащий этапы, на которых: анализируют входные биологические или физические данные, используя процедуру обработки данных с использованием алгоритма PD2i, причем упомянутые данные включают в себя набор прикладных параметров, связанных с биологическими данными, коррелирующими с биологическими отклонениями для генерации серий данных; определяют, является ли угловой коэффициент серий данных меньше заданного значения; если угловой коэффициент меньше заданного значения, устанавливают заданную величину углового коэффициента и используют серии данных для обнаружения или прогнозирования возникновения церебральных на- 13008979 рушений. 3. Способ по п.1 или 2, в котором заданное значение представляет собой приблизительно 0,5. 4. Способ по п.1 или 2, в котором заданная величина представляет собой 0. 5. Способ по п.1 или 2, дополнительно включающий этапы, на которых определяют шумовой интервал внутри серий данных; и если этот шумовой интервал находится внутри заданной области, делят серии данных на другую заданную величину и повторяют этап анализа для генерации новых значений серий данных. 6. Способ по п.5, в котором другая заданная величина представляет собой 2. 7. Способ по п.5, в котором заданная область составляет от -х до +х, где х представляет собой любую величину. 8. Способ по п.7, в котором заданная область составляет от -5 до +5. 9. Способ для обнаружения или прогнозирования биологических отклонений, содержащий этапы,на которых: анализируют входные биологические или физические данные, используя процедуру обработки данных с использованием алгоритма PD2i, причем упомянутые данные включают в себя набор прикладных параметров, связанных с биологическими данными, коррелирующими с биологическими отклонениями для генерации серий данных; определяют шумовой интервал внутри серий данных; и если шумовой интервал находится внутри заданной области, делят серии данных на заданную величину и повторяют этап анализа для генерации новых значений для серий данных; или если шумовой интервал находится вне заданной области, используют серии данных для обнаружения или прогнозирования исхода биологических отклонений. 10. Способ для обнаружения или прогнозирования церебральных нарушений, содержащий этапы,на которых анализируют входные биологические или физические данные, используя процедуру обработки данных с использованием алгоритма PD2i, причем упомянутые данные включают в себя набор прикладных параметров, связанных с биологическими данными, коррелирующими с биологическими отклонениями для генерации серий данных; определяют шумовой интервал внутри серий данных; и если шумовой интервал находится внутри заданной области, делят серии данных на заданную величину и повторяют этап анализа для генерации новых значений для серий данных; или если шумовой интервал находится вне заданной области, используют серии данных для обнаружения или прогнозирования исхода церебральных нарушений. 11. Способ по п.9 или 10, в котором заданная величина представляет собой 2. 12. Способ по п.9 или 10, в котором заданная область составляет от -х до +х, где х представляет собой любую величину. 13. Способ по п.12, в котором заданная область составляет от -5 до +5. 14. Способ по п.9 или 10, дополнительно включающий в себя этапы, на которых определяют, является ли угловой коэффициент серий данных меньше заданного значения; и если угловой коэффициент меньше заданного значения, устанавливают угловой коэффициент в другую заданную величину. 15. Способ по п.14, в котором заданное значение представляет собой приблизительно 0,5. 16. Способ по п.14, в котором другая заданная величина представляет собой 0. 17. Способ по любому из пп.1, 2, 9, 10, в котором процедура обработки данных использует нижеследующий алгоритм для генерации PD2i серий данных:PD2ilog C(n, r, nref)/log r гдеозначает "масштабирование в виде", С представляет собой корреляционный интеграл для PD2i, в котором n равно длине данных, r равно длине области масштабирования и nref равно местоположению референсного вектора для оценки области масштабирования углового коэффициента log C/log r в ограниченной области малых log r, в которой отсутствуют эффекты нестационарности данных. 18. Способ по п.1 или 9, в котором входные биологические или физические данные включают в себя электрофизиологические данные. 19. Способ по п.18, в котором электрофизиологические данные представляют собой данные ЭКГ,которые анализируют для обнаружения или прогнозирования появления, по меньшей мере, либо аритмии сердца, либо церебрального эпилептического припадка, и/или для измерения тяжести ишемии миокарда. 20. Способ по п.2 или 10, в котором входные биологические или физические данные включают в себя электрофизиологические данные. 21. Способ по п.2 или 10, в котором церебральное нарушение представляет собой губкообразную энцефалопатию крупного рогатого скота. 22. Способ по п.2 или 10, в котором церебральное нарушение представляет собой болезнь Альцгеймера.- 14008979 23. Устройство для обнаружения или прогнозирования биологических отклонений, причем устройство содержит средство для анализа входных биологических или физических данных с использованием процедуры обработки данных с использованием алгоритма PD2i, причем упомянутые данные включают в себя набор прикладных параметров, связанных с биологическими данными, коррелирующими с биологическими отклонениями для генерации серий данных; средство для определения, является ли угловой коэффициент серий данных меньше заданного значения; средство для установки заданной величины углового коэффициента, если угловой коэффициент меньше заданного значения; и средство для использования серий данных для обнаружения или прогнозирования появления биологических отклонений. 24. Устройство по п.23, в котором заданное значение представляет собой приблизительно 0,5. 25. Устройство по п.23, в котором заданная величина представляет собой 0. 26. Устройство по п.23, дополнительно включающее средство для определения шумового интервала внутри серий данных и средство для деления серий данных на другую заданную величину, если указанный шумовой интервал находится внутри заданной области, и предоставления результата деления серий данных в средство для анализа для генерации новых значений серий данных. 27. Устройство по п.26, в котором другая заданная величина представляет собой 2. 28. Устройство по п.26, в котором заданная область составляет от -х до +х, где х представляет собой любую величину. 29. Устройство по п.28, в котором заданная область составляет от -5 до +5. 30. Устройство для обнаружения или прогнозирования биологических отклонений, причем устройство содержит средство для анализа входных биологических или физических данных с использованием процедуры обработки данных с использованием алгоритма PD2i, причем упомянутые данные включают в себя набор прикладных параметров, связанных с биологическими данными, коррелирующими с биологическими отклонениями для генерации серий данных; средство для определения шумового интервала внутри серий данных; и средство для деления серии данных на заданную величину, если шумовой интервал находится внутри заданной области, и предоставления поделенных в средство для анализа для генерации новых значений для серий данных; и средство для использования серий данных для обнаружения или прогнозирования появления биологических отклонений, если шумовой интервал находится вне заданной области. 31. Устройство по п.30, в котором заданная величина представляет собой 2. 32. Устройство по п.30, в котором заданная область составляет от -х до +х, где х представляет собой любую величину. 33. Устройство по п.32, в котором заданная область составляет от -5 до +5. 34. Устройство по п.30, дополнительно включающее средство для определения, является ли угловой коэффициент серий данных меньше заданного значения; и средство для установки углового коэффициента в другую заданную величину, если угловой коэффициент меньше заданного значения. 35. Устройство по п.34, в котором заданное значение представляет собой приблизительно 0,5. 36. Устройство по п.34, в котором другая заданная величина представляет собой 0. 37. Устройство по п.23 или 30, в котором процедура обработки данных использует нижеследующий алгоритм для генерации PD2i серий данных:PD2ilog C(n, r, nref)/log r гдеозначает "масштабирование в виде", С представляет собой корреляционный интеграл для PD2i, в котором n равно длине данных, r равно области масштабирования и nref равно местоположению референсного вектора для оценки области масштабирования угла наклона log C/log r в ограниченной области малых log r, в которой отсутствуют эффекты нестационарности данных. 38. Устройство по п.23 или 30, в котором входные биологические или физические данные включают в себя электрофизиологические данные. 39. Устройство по п.38, в котором электрофизиологические данные представляют собой данные ЭКГ, которые анализируют для обнаружения или прогнозирования появления, по меньшей мере, либо аритмии сердца, либо церебрального эпилептического припадка, и/или для измерения тяжести ишемии миокарда.
МПК / Метки
МПК: A61B 5/0456, A61B 5/046, A61B 5/04, A61B 5/048, A61B 5/0452
Метки: улучшенный, нарушений, например, способ, церебральных, выявления, биологических, система, аномалий, прогнозирования
Код ссылки
<a href="https://eas.patents.su/21-8979-uluchshennyjj-sposob-i-sistema-dlya-vyyavleniya-i-ili-prognozirovaniya-biologicheskih-anomalijj-naprimer-cerebralnyh-narushenijj.html" rel="bookmark" title="База патентов Евразийского Союза">Улучшенный способ и система для выявления и/или прогнозирования биологических аномалий, например, церебральных нарушений</a>
Способ и система анализа характеристик жидких сред биологических организмов

Номер патента: 7146
Опубликовано: 25.08.2006
Авторы: Хидашели Давид Георгиевич, Сакварелидзе Георгий Леванович, Вахтангишвили Роберт Шалвович, Шахраманьян Николай Андраникович, Сошенко Марина Николаевна
МПК: G01N 33/48, G01N 21/00
Метки: биологических, анализа, характеристик, способ, организмов, жидких, система, сред
Формула / Реферат:
1. Способ анализа характеристик жидких сред биологических организмов, включающий отбор жидких сред от биологических организмов и анализ форменных элементов этих сред под микроскопом, отличающийся тем, что предварительно создают атласы соответствия состояний биологических организмов геометрическим, структурным и цветовым параметрам изображений как форменных, так и неформенных элементов жидких сред этих организмов, анализ динамических и...
Композиция для лечения и/или предупреждения нарушений, приводящих к аномальному кровотечению, и способ лечения таких нарушений (варианты)

Номер патента: 5236
Опубликовано: 30.12.2004
Авторы: Киан Джиахуа, Грэй Гэри С., Хойэр Леон У., Коллинс Мэри
МПК: A61K 38/37, A61P 7/04, A61K 39/395...
Метки: варианты, аномальному, способ, предупреждения, нарушений, лечения, таких, кровотечению, приводящих, композиция
Формула / Реферат:
1. Композиция для лечения и/или предупреждения нарушений, приводящих к аномальному кровотечению, содержащая по меньшей мере один фактор прокоагуляции и по меньшей мере один агент, ингибирующий взаимодействие костимулирующей молекулы на поверхности антиген-презентирующей клетки и соответствующего ей рецептора на Т-клетке, приводящее к генерации иммунного ответа на указанный фактор. 2. Композиция по п.1, отличающаяся тем, что она дополнительно...
Производные циклической аминокислоты, фармацевтическая композиция на их основе и способ лечения эпилепсии, приступов слабости, гипокинезии, черепных нарушений, нейродегенеративных или невропатологических нарушений,депрессий, состояний тревоги и паники и боли

Номер патента: 2765
Опубликовано: 29.08.2002
Авторы: Хартенштайн Йоганнес, Брайэнс Джастин С., Ретклифф Джильс С., Моррелл Эндру И., Нин Клер О., Орвелл Дейвид Кристофер
МПК: A61P 25/28, A61K 31/164, C07C 229/28...
Метки: основе, тревоги, гипокинезии, приступов, нарушений,депрессий, лечения, нейродегенеративных, боли, невропатологических, фармацевтическая, слабости, композиция, циклической, аминокислоты, паники, нарушений, черепных, производные, эпилепсии, состояний, способ
Формула / Реферат:
1. Производные циклической аминокислоты общей формулы I в которой 1 - 4 из радикалов R1-R10 означают метил, а остальные - водород, или один из указанных радикалов R1-R10 означает изопропил или трет.-бутил, а остальные - водород, и их фармацевтически приемлемые соли. 2. Производные циклической аминокислоты формулы I по п.1, в которой R5 означает изопропил или трет.-бутил. 3. Производные циклической аминокислоты формулы I по п.1, в которой R3...
Улучшенный способ получения меламина высокой чистоты с высоким выходом

Номер патента: 5993
Опубликовано: 25.08.2005
Авторы: Пармеджани Массимо, Сантуччи Роберто, Ноэ' Серджо
МПК: C07D 251/60
Метки: способ, высоким, меламина, чистоты, высокой, выходом, улучшенный, получения
Формула / Реферат:
1. Способ получения меламина с высокой степенью чистоты с высоким выходом посредством пиролиза мочевины при температуре от 360 до 420шC и давлении свыше 7 МПа, в котором продукты реакции, содержащие газообразную фазу и жидкую фазу, подвергают последующей обработке для выделения меламина, отличающийся тем, что a) жидкую фазу из реактора пиролиза, содержащую меламин, непрореагировавшую мочевину, промежуточные окисленные продукты пиролиза (OAT) и...
Способ и устройство для взятия биологических проб

Номер патента: 5100
Опубликовано: 28.10.2004
Авторы: Диттманн Томас Клаус, Хойерманн Арно Свенд, Олек Александр, Гут Иво Глинне
МПК: A61B 10/00
Метки: биологических, взятия, устройство, способ, проб
Формула / Реферат:
1. Способ взятия и регистрации биологических проб, согласно которому предварительно маркируют каждую капсулу для взятия проб и осуществляют их сквозную нумерацию, затем в устройстве для взятия биологических проб размещают составные элементы по меньшей мере одной капсулы, взятие биологической пробы осуществляют с помощью одного из составных элементов капсулы одновременно с взятием пробы, во время взятия пробы или после взятия пробы составные...
Предыдущий патент: Способ и устройство для определения деструктивного крутящего момента на оборудовании низа бурильной колонны
Следующий патент: Автомат для игры в карты
Случайный патент: Применение фитоэстрогенсодержащих экстрактов, селективно модулирующих бета-рецептор эстрогена