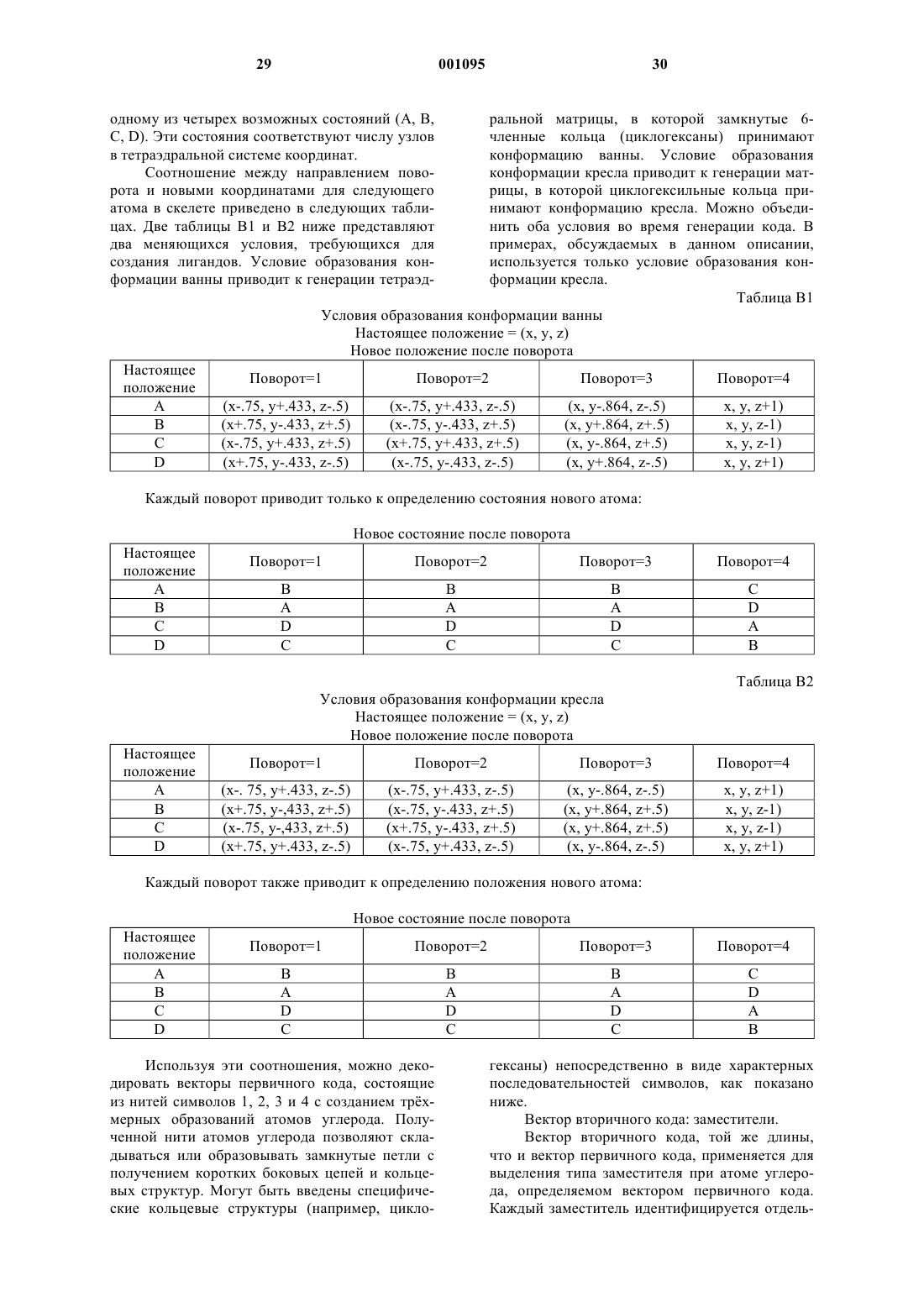
Компьютерный способ создания химических структур, имеющих общие функциональные характеристики
























Формула / Реферат
1. Способ компьютерного конструирования химических структур, обладающих предварительно выбранной функциональной характеристикой, включающий следующие стадии:
(а) создание физической модели фенотипа моделированного рецептора, кодируемого в виде линейной последовательности символов, и создание набора молекул мишеней, имеющих, по меньшей мере, одну общую поддающуюся количественному измерению функциональную характеристику;
(б) для каждой молекулы мишени
(i) расчет сродства между рецептором и молекулой мишени в каждой из множества ориентаций с применением расчета эффективного сродства;
(ii) расчет суммарного сродства суммированием вычисленных значений сродства;
(iii) определение максимального сродства;
(в) применение вычисленных величин суммарного и максимального сродства для
(i) расчета коэффициента корреляции максимального сродства между максимальным сродством и поддающейся количественному определению функциональной характеристикой;
(ii) расчета коэффициента корреляции суммарного сродства между суммарным сродством и определяемой количественно функциональной характеристикой;
(г) применение максимального коэффициента корреляции и суммарного коэффициента корреляции для расчета коэффициента соответствия;
(д) изменение структуры рецептора и повторение стадий от (б) до (г) до получения популяции рецепторов, обладающих заранее выбранным коэффициентом соответствия;
(е) создания физической модели химической структуры, кодируемой в виде молекулярной линейной последовательности символов; расчет сродства между химической структурой и каждым рецептором из множества ориентаций с применением указанного метода вычисления эффективного сродства, применение расчетных величин сродства для расчета степени соответствия сродства;
(ж) изменение химической структуры для получения варианта химической структуры и повторение стадии (е); и
(з) сохранение и дальнейшее изменение тех вариантов химической структуры, степень сродства которых приближается к заранее заданной (выбранной) степени сродства.
2. Способ по п.1, отличающийся тем, что линейная последовательность символов, кодирующих указанный фенотип рецептора, получается генерацией линейной последовательности символов рецептора, которая кодирует пространственное распределение и заряд, и также отличающийся тем, что стадия создания физической модели химической структуры включает генерацию указанной молекулярной линейной последовательности символов, которая кодирует пространственное распределение и заряд.
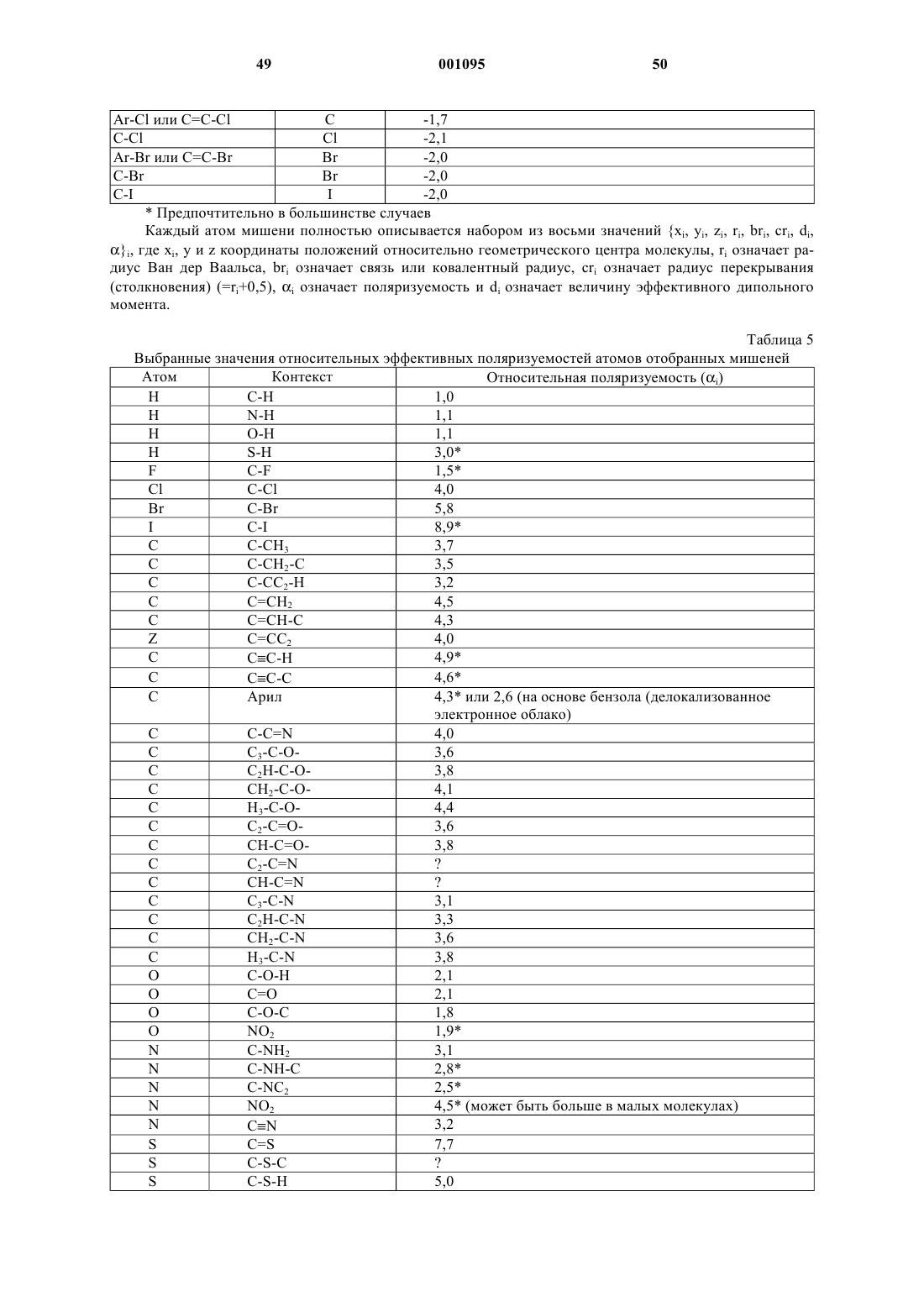
3. Способ по п.2, отличающийся тем, что указанный расчет эффективного сродства включает два критерия, причем первый является критерием проксимальности, отличающийся тем, что незаряженные участки указанного моделированного рецептора достаточно близки к неполярным участкам указанной молекулярной структуры, чтобы интенсивность эффективной Лондоновской дисперсии стало возможным определить, а второй является суммарной интенсивностью электростатического взаимодействия заряд-диполь, возникающего между заряженными участками указанного моделированного рецептора и диполями, присутствующими в указанной молекулярной структуре.
4. Способ по п.2, отличающийся тем, что указанная стадия расчета степени соответствия сродства включает расчет суммарного и максимального сродства между молекулярной структурой и каждым рецептором, причем степень соответствия рассчитывают следующим образом:
S {_ вычисленное максимальное сродство - максимальное сродство мишени_ /максимальное сродство мишени}, и отличающийся также тем, что указанная предварительно выбранная степень соответствия практически равна нулю.
5. Способ по п.2, отличающийся тем, что указанная стадия расчета степени соответствия сродства включает расчет суммарного и максимального сродства между молекулярной структурой и каждым рецептором, причем степень соответствия рассчитывают следующим образом:
S {(_расчетное максимальное сродство - максимальное сродство мишени_/2 _ максимальное сродство мишени) + (_расчетное суммарное сродство - суммарное сродство мишени_)}, и отличающийся также тем, что указанная предварительно выбранная степень соответствия практически равна нулю.
6. Способ по п.2, отличающийся тем, что указанный коэффициент корреляции суммарного сродства представляет собой rSA2, указанный коэффициент корреляции максимального сродства представляет собой rMA2, и также тем, что указанный коэффициент соответствия означает F = (rMA2 _ rSA2)0,5, а также тем, что предварительно выбранный коэффициент соответствия практически равен единице.
7. Способ по п.2, отличающийся тем, что указанный коэффициент корреляции суммарного сродства представляет собой rSA-MA2, указанный коэффициент корреляции максимального сродства представляет собой rMA2, также отличающийся тем, что указанный коэффициент соответствия представляет собой F = (rMA2 _ (1- rSA-MA2))0,5, и также тем, что указанный предварительно выбранный коэффициент практически равен единице.
8. Способ по п.2, отличающийся тем, что указанные молекулярные линейные последовательности символов включают множество последовательностей триплетов символов, причем первый символ указанного триплета произвольно выбран из набора первых символов, определяющих положение и идентичность "заселяющего" атома в молекулярном скелете указанной молекулярной структуры, второй символ указанного триплета произвольно выбран из набора вторых символов, определяющих идентичность заместителя, связанного с указанным "заселяющим" атомом, а третий символ указанного триплета произвольно выбирается из набора третьих символов, определяющих местоположение указанного заместителя при атоме, точно определяемом первым символом триплета.
9. Способ по п.8, отличающийся тем, что молекулярную линейную последовательность символов декодируют, применяя алгоритм компоновки эффективной молекулы, который последовательно перемещает каждый триплет указанной молекулярной линейной последовательности, а затем насыщает незаполненные позиции при указанном молекулярном скелете атомами водорода.
10. Способ по п.9, отличающийся тем, что стадия изменения молекулярной структуры включает, по меньшей мере, одну из следующих операций: i) мутацию указанного генотипа молекулы путем произвольного взаимного обмена, по меньшей мере, одним из указанных первым, вторым или третьим символом с, по меньшей мере, одним триплетом из наборов соответствующих символов, ii) делецию, при которой триплет из генотипа молекулы удаляют, iii) дупликацию, при которой триплет в генотипе молекулы дублируется, iv) инверсию, при которой последовательный порядок одного или более триплетов в генотипе молекулы меняется на обратный, и v) инсерцию, при которой триплет из генотипа молекулы вводят в другое положение в генотипе молекулы.
11. Способ по п.10, отличающийся тем, что стадия мутации указанных молекулярных генотипов включает рекомбинацию произвольно выбранных пар указанных сохранённых мутантных молекулярных генотипов, в то время как соответствующие символы в указанных молекулярных линейных последовательностях взаимно обмениваются.
12. Способ по п.2, отличающийся тем, что каждый символ в линейной последовательности символов рецептора определяет либо команду пространственного поворота, либо заряженного сайта без поворота.
13. Способ по п.12, отличающийся тем, что указанный фенотип рецептора содержит, по меньшей мере, один линейный полимер с множеством субъединиц, причем одна из указанных субъединиц является первой субъединицей в указанном, по меньшей мере, одном линейном полимере.
14. Способ по п.13, отличающийся тем, что указанную линейную последовательность символов рецептора декодируют, применяя алгоритм сборки эффективного рецептора, в котором команды поворота, применяемые к каждой субъединице, следующей за указанной первой субъединицей, задаются относительно позиции указанной первой субъединицы.
15. Способ по п.14, отличающийся тем, что указанные символы определяют программу команд пространственного поворота для нет поворота, поворот направо, поворот налево, поворот вверх, поворот вниз, и тем, что символы определяют код сайтов зарядов для положительно заряженного сайта без поворота и отрицательно заряженного сайта без поворота.
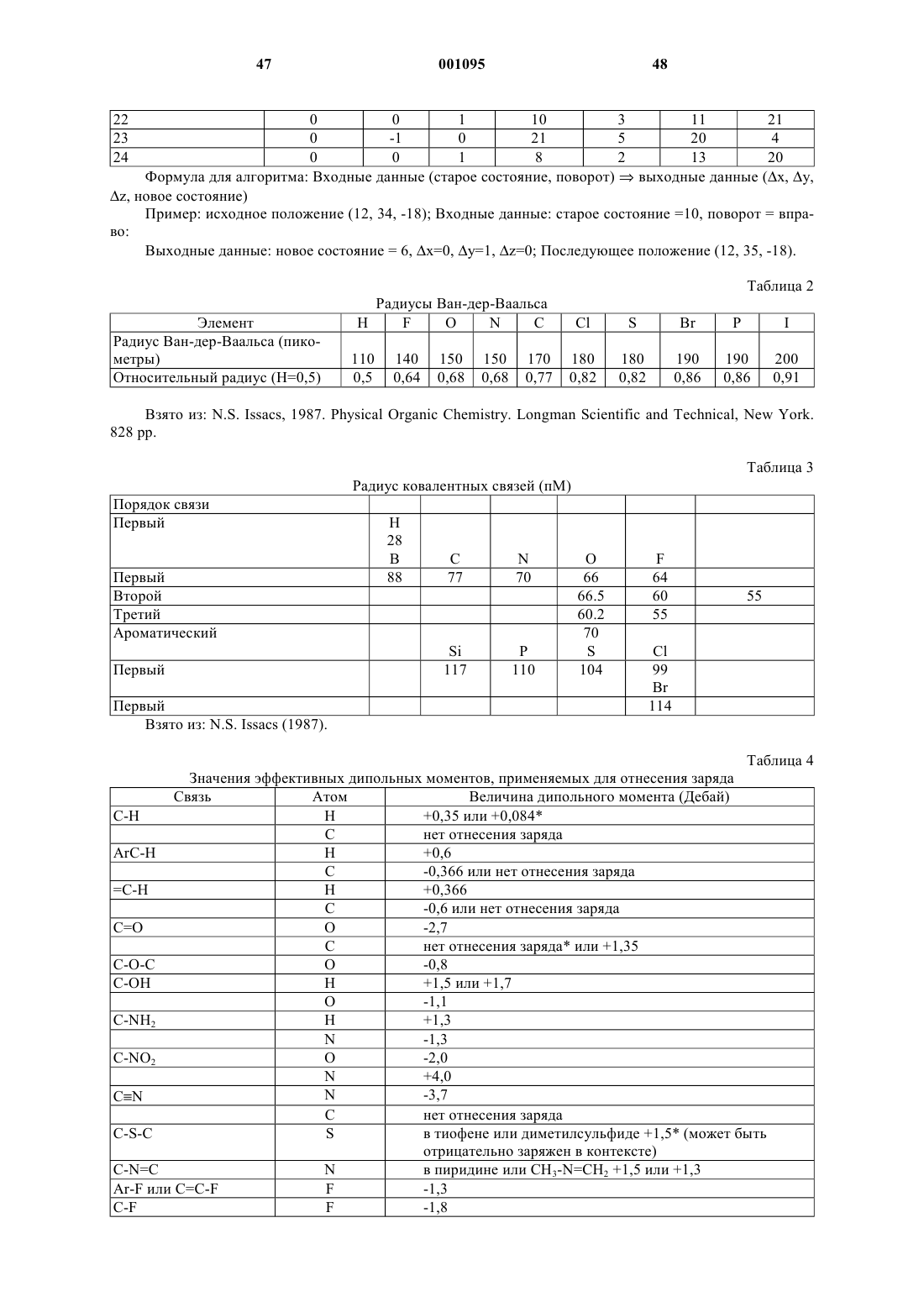
16. Способ по п.14, отличающийся тем, что указанные субъединицы являются практически сферическими с радиусами Ван дер Ваальса, практически равными радиусу Ван дер Ваальса водорода.
17. Способ по п.15, отличающийся тем, что стадия изменения указанного генотипа рецептора включает, по меньшей мере, одну из следующих операций: i) делецию, при которой удаляется символ из генотипа рецептора, ii) дупликацию, при которой дублируется символ в генотипе рецептора, iii) инверсию, при которой последовательный порядок одного или более символов в генотипе рецептора меняется на обратный, и iv) инсерцию, при которой символ из генотипа рецептора вводят в другое положение в генотипе.
18. Способ по п.17, отличающийся тем, что стадия мутации указанных генотипов рецепторов включает рекомбинацию произвольно выбранных пар указанных сохранённых генотипов мутантных рецепторов, при этом соответствующие символы в указанных линейных последовательностях рецепторов взаимно обмениваются.
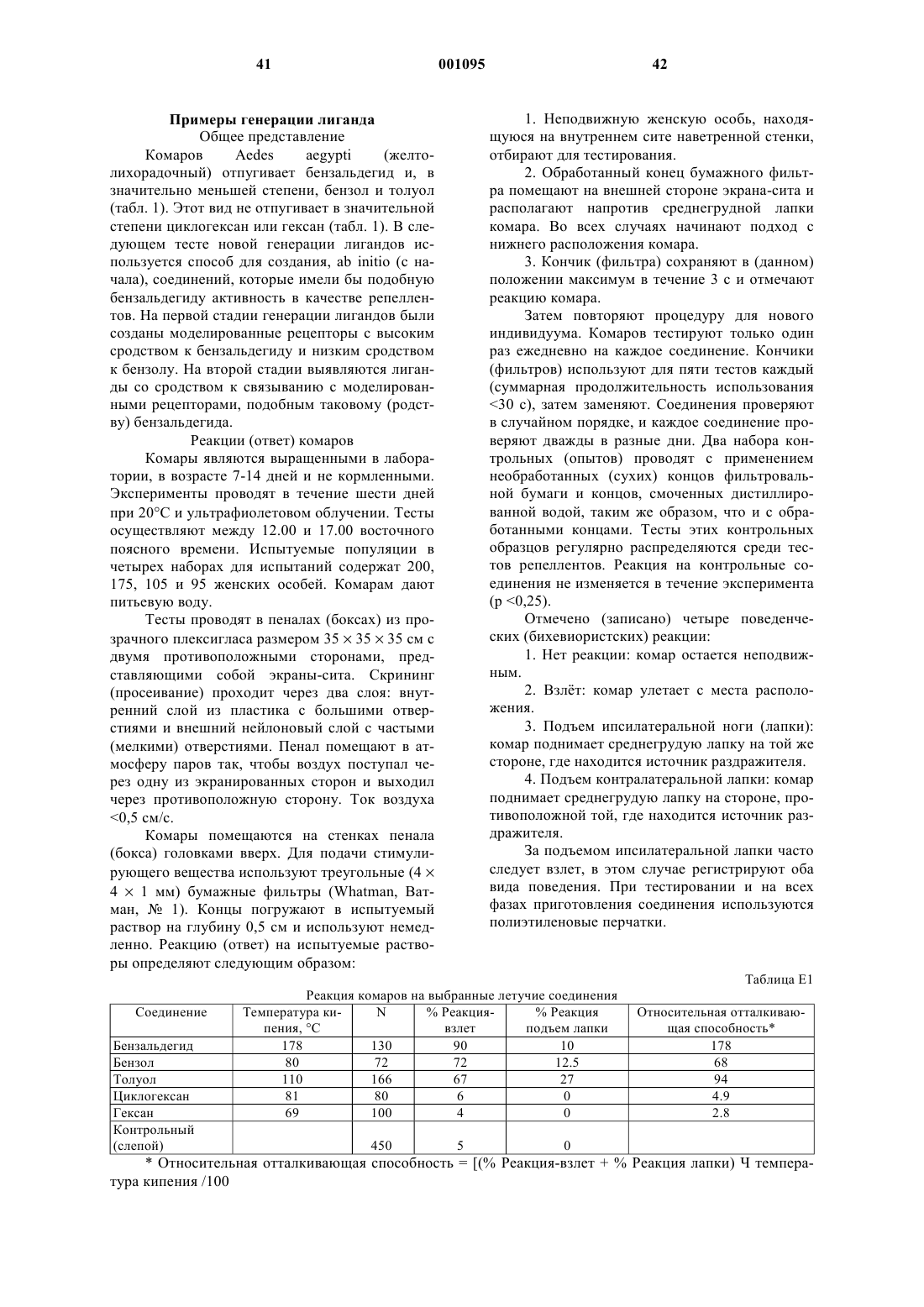
19. Способ компьютерного скрининга химических структур с предварительно выбранными функциональными характеристиками, заключающийся в
(а) создании генотипа моделированного рецептора генерацией рецепторной линейной последовательности символов, которая кодирует пространственное распределение и заряд;
(б) декодировании генотипа с целью создания фенотипа рецептора, предусматривающего, по меньшей мере, одну молекулу мишени, проявляющую выбранную функциональную характеристику, расчете сродства между рецептором и каждой молекулой мишени во множестве ориентаций с применением расчета эффективного сродства, расчете суммарного и максимального сродства между каждой молекулой мишени и рецептором, расчете коэффициента корреляции суммарного сродства для суммарного сродства относительно указанной функциональной характеристики молекулы мишени и коэффициента корреляции максимального сродства для максимального сродства относительно указанной функциональной характеристики (мишени), и расчете коэффициента соответствия, зависящего от указанных коэффициентов корреляции суммарного и максимального сродства;
(в) мутации генотипа рецептора и повторении стадии (б) и сохранении и мутации рецепторов с повышенными коэффициентами соответствия до тех пор, пока не будет получены популяции рецепторов с предварительно выбранными коэффициентами соответствия; далее
(г) расчете сродства между подвергаемой скринингу химической структурой и каждым рецептором во множестве ориентаций, используя указанный расчет эффективного сродства, расчете степени соответствия сродства, который включает расчет суммарного и максимального сродства между соединением и каждым рецептором и сравнение, по меньшей мере, одной из величин указанного суммарного и максимального сродства с величинами суммарного и максимального сродства между указанной, по меньшей мере, одной мишенью и указанной популяцией рецепторов, при этом указанное сравнение является показателем степени функциональной активности указанной химической структуры относительно указанной, по меньшей мере, одной молекулы мишени.
20. Способ по п.19, отличающийся тем, что указанный расчет эффективного сродства содержит два критерия, причем первый является критерием проксимальности, при которой незаряженные участки указанных моделированных рецепторов достаточно близки к неполярным участкам указанной молекулярной структуры, чтобы сделать возможным определение (интенсивности) эффективной Лондоновской дисперсии, а второй является суммарной силой электростатического взаимодействия заряд-диполь, возникающей между заряженными участками указанного моделированного рецептора и диполями, имеющимися в указанной молекулярной структуре.
21. Способ по п.20, отличающийся тем, что степень соответствия вычисляют как S {_расчётное максимальное сродство - максимальное сродство мишени_/максимальное сродство мишени}.
22. Способ по п.20, отличающийся тем, что степень соответствия вычисляют как S {(_расчетное максимальное сродство - максимальное сродство мишени_/2_максимальное сродство мишени) + (_расчетное суммарное сродство - суммарное сродство мишени_/2_суммарное сродство мишени)}.
23. Способ по п.20, отличающийся тем, что указанный коэффициент корреляции суммарного сродства представляет собой rSA2, указанный коэффициент корреляции максимального сродства представляет собой rMA2, и тем, что указанный коэффициент соответствия представляет собой F = (rMA2 _ rSA2)0,5, а также тем, что предварительно выбранный коэффициент соответствия практически равен единице.
24. Способ по п.20, отличающийся тем, что указанный коэффициент корреляции суммарного сродства представляет собой rSA-MA2, указанный коэффициент корреляции максимального сродства представляет собой rMA2, и тем, что указанный коэффициент соответствия представляет собой F = (rMA2 _ (1- rSA-MA2))0.5, a также тем, что указанный заранее выбранный коэффициент соответствия практически равен единице.
25. Способ по п.20, отличающийся тем, что каждый символ в рецепторной линейной последовательности символов определяет либо команду поворота в пространстве, либо заряженный сайт без поворота.
26. Способ по п.25, отличающийся тем, что указанный фенотип рецептора содержит, по меньшей мере, один линейный полимер с множеством субъединиц, причем одна из этих субъединиц является первой субъединицей в указанном, по меньшей мере, одном линейном полимере.
27. Способ по п.26, отличающийся тем, что указанную рецепторную линейную последовательность символов декодируют, применяя алгоритм сборки эффективного рецептора, в котором (алгоритме) команды поворота, применяемые к каждой субъединице, следующей за указанной первой субъединицей, задаются относительно начальной позиции указанной первой субъединицы.
28. Способ по п.27, отличающийся тем, что указанные символы определяют программу команд поворота в пространстве для нет поворота, правый поворот, левый поворот, поворот вверх, поворот вниз, и также тем, что символы определяют код сайтов зарядов для положительно заряженного сайта без поворота и отрицательно заряженного сайта без поворота.
29. Способ по п.28, отличающийся тем, что указанные субъединицы являются практически сферическими с радиусами Ван дер Ваальса, практически равными радиусу Ван дер Ваальса водорода.
30. Способ по п.27, отличающийся тем, что стадия мутации указанного генотипа рецептора включает, по меньшей мере, одну из следующих операций: i) делецию, при которой удаляется символ из генотипа рецептора, ii) дупликацию, при которой дублируется символ в генотипе рецептора, iii) инверсию, при которой последовательный порядок одного или более символов в генотипе рецептора меняется на обратный, и iv) инсерцию, при которой символ из генотипа рецептора вводят в другое положение в генотипе.
31. Способ по п.30, отличающийся тем, что стадия мутации указанных генотипов рецепторов включает рекомбинацию произвольно выбранных пар указанэых сохранённых генотипов мутантных рецепторов, при этом соответствующие символы в указанных линейных последовательностях рецепторов взаимно обмениваются.
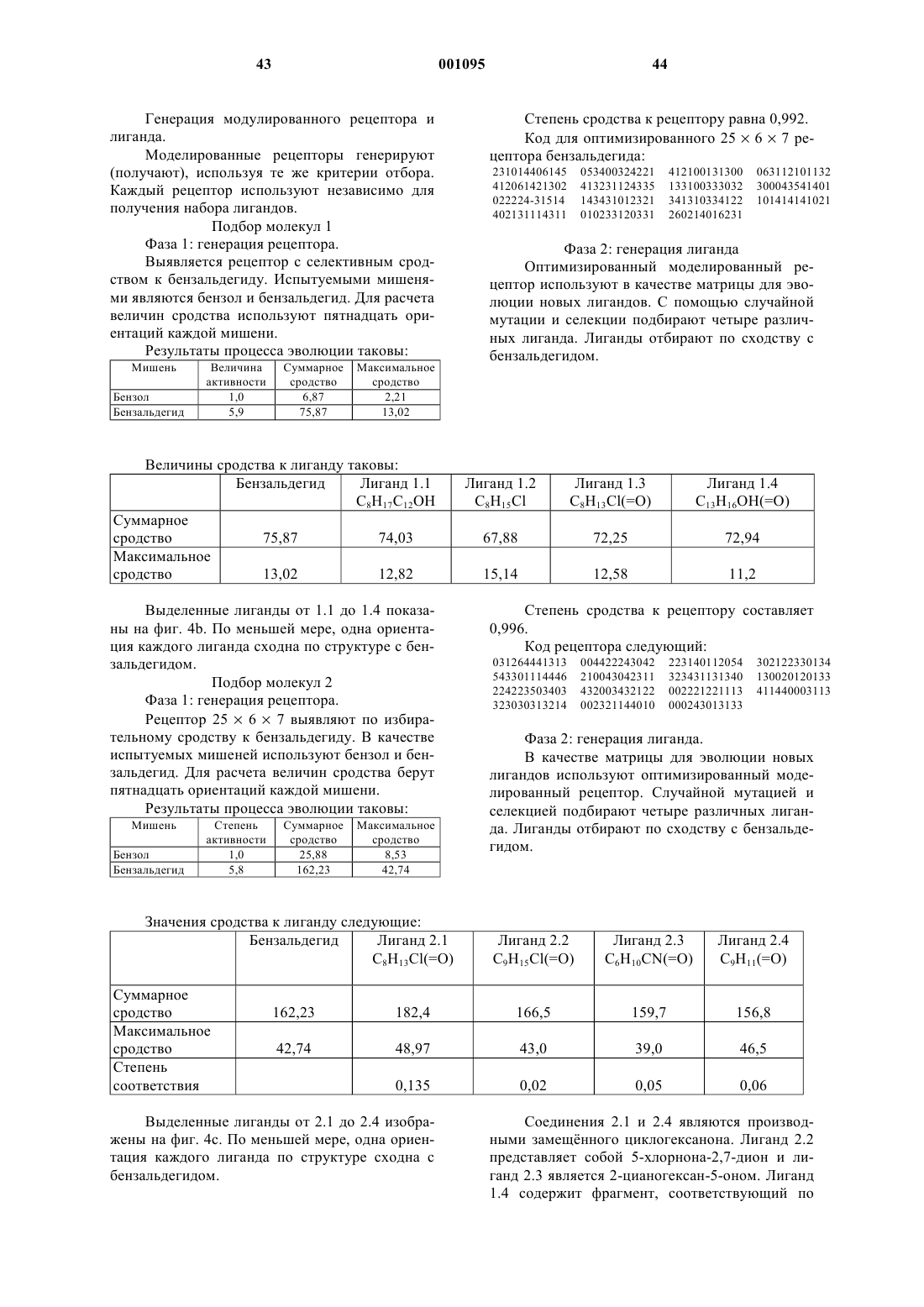
32. Способ компьютерного построения моделированных рецепторов, имитирующих биологические рецепторы, проявляющие селективное сродство к соединениям со сходными функциональными характеристиками, содержащий стадии
(а) создания генотипа моделированного рецептора генерацией рецепторной линейной последовательности символов, которая кодирует пространственное распределение и заряд;
(б) декодирования генотипа с целью создания фенотипа рецептора, создания набора молекул мишеней, имеющих общие сходные функциональные характеристики, расчет сродства между рецептором и каждой молекулой мишени во множестве ориентаций с применением расчета эффективного сродства, расчет суммарного и максимального сродства между каждой молекулой мишени и рецептором, расчет коэффициента корреляции суммарного сродства относительно функциональной характеристики каждой молекулы мишени и коэффициента корреляции максимального сродства относительно указанной функциональной характеристики для каждой молекулы мишени, и расчет коэффициента соответствия, зависящего от указанных коэффициентов корреляции суммарного и максимального сродства для каждой молекулы мишени; и
(в) мутации генотипа и повторение стадии (б) и сохранения и мутации рецепторов с повышенными коэффициентами соответствия до тех пор, пока не будет создана популяция рецепторов с заранее выбранными коэффициентами соответствия.
33. Способ по п.32, отличающийся тем, что каждый символ в рецепторной линейной последовательности символов определяет либо команду поворота в пространстве, либо заряженный сайт без поворота.
34. Способ по п.33, отличающийся тем, что указанный фенотип рецептора содержит множество линейных полимеров с множеством субъединиц, причем каждый линейный полимер кодируется соответствующей линейной последовательностью символов и одна из указанных субъединиц является первой субъединицей в указанном, по меньшей мере, одном линейном полимере.
35. Способ по п.34, отличающийся тем, что указанную рецепторную линейную последовательность символов декодируют, применяя алгоритм сборки эффективного рецептора, в котором (алгоритме) команды поворота, применяемые к каждой субъединице, следующей за указанной первой субъединицей, задаются относительно исходной позиции указанной первой субъединицы.
36. Способ по п.35, отличающийся тем, что указанные символы задают программу команд поворота в пространстве для нет поворота, поворот направо, поворот налево, поворот вверх, поворот вниз, и тем, что символы определяют код сайтов заряда для положительно заряженного сайта без поворота и отрицательно заряженного сайта без поворота.
37. Способ по п.36, отличающийся тем, что указанные субъединицы являются практически сферическими с радиусами Ван дер Ваальса, практически равными радиусу Ван дер Ваальса водорода.
38. Способ по п.35, отличающийся тем, что стадия мутации указанного генотипа рецептора включает, по меньшей мере, одну из следующих операций: i) делецию, при которой из генотипа рецептора удаляется символ, ii) дупликацию, при которой в генотипе рецептора дублируется символ, iii) инверсию, при которой последовательный порядок одного или более символов в генотипе рецептора меняется на обратный, и iv) инсерцию, при которой символ из генотипа рецептора вводят в другое положение в генотипе.
39. Способ по п.38, отличающийся тем, что стадия мутации генотипов указанного рецептора включает рекомбинацию произвольно выбранных пар указанных сохранённых генотипов мутантных рецепторов, при этом соответствующие символы в указанных рецепторных линейных последовательностях взаимно обмениваются.
40. Способ по п.33, отличающийся тем, что указанный расчет эффективного сродства содержит два критерия, причем первый является критерием проксимальности, при которой незаряженные участки указанных моделированных рецепторов достаточно близки к неполярным участкам указанной молекулярной структуры, чтобы интенсивность эффективной Лондоновской дисперсии стало возможным определить, а второй является суммарной интенсивностью электростатического взаимодействия заряд-диполь, возникающего между заряженными участками указанного моделированного рецептора и диполями, присутствующими в указанной молекулярной структуре.
41. Способ по п.40, отличающийся тем, что указанный коэффициент корреляции суммарного сродства представляет собой rSA2, указанный коэффициент корреляции максимального сродства представляет собой rMA2, и также отличающийся тем, что указанный коэффициент соответствия означает F = (rMA2 _ rSA2)0,5, а также тем, что предварительно выбранный коэффициент соответствия практически равен единице.
42. Способ по п.40, отличающийся тем, что указанный коэффициент корреляции суммарного сродства представляет собой rSA-MA2, указанный коэффициент корреляции максимального сродства представляет собой rMA2, также отличающийся тем, что указанный коэффициент соответствия представляет собой F = (rMA2 _ (1- rSA2))0,5, и также тем, что указанный предварительно выбранный коэффициент практически равен единице.
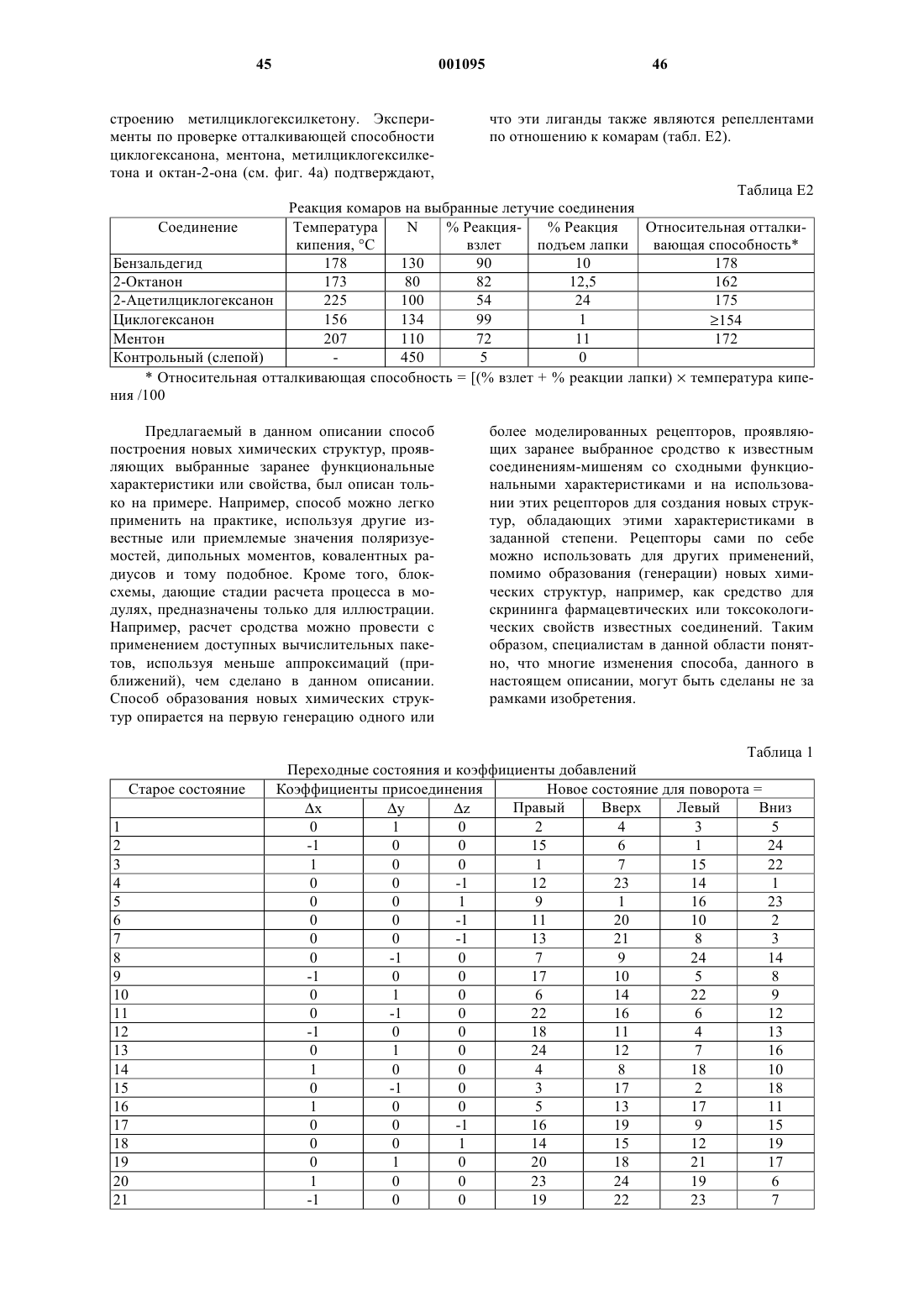
43. Способ компьютерного создания химических структур с заранее выбранными функциональными особенностями, включающий следующие стадии:
(а) создание физической модели рецептора и набора молекул мишеней, при этом молекулы мишени обладают, по меньшей мере, одной общей поддающейся количественному определению функциональной характеристикой;
(б) для каждой молекулы мишени
(i) расчет сродства между рецептором и молекулой мишени в каждой из множества ориентаций с применением расчета эффективного сродства;
(ii) расчет суммарного сродства суммированием вычисленных значений сродства;
(iii) определение максимального сродства;
(в) применение вычисленных значений суммарного и максимального сродства для
(i) расчета коэффициента корреляции максимального сродства между значениями максимального сродства и количественно определяемой функциональной характеристикой;
(ii) расчета коэффициента корреляции суммарного сродства между значениями суммарного сродства и количественно определяемой функциональной характеристикой;
(г) применение максимального коэффициента корреляции и суммарного коэффициента корреляции к расчету коэффициента соответствия;
(д) изменение структуры рецептора и повторение стадий от (б) до (г) до получения популяции рецепторов с заранее выбранным коэффициентом соответствия;
(е) создания физической модели химической структуры, расчет сродства между химической структурой и каждым рецептором во множестве ориентаций с применением указанного расчета эффективного сродства, использование расчетных величин сродства для расчета степени соответствия сродства;
(ж) изменение химической структуры с целью получения варианта химической структуры и повторение стадии (е); и
(з) сохранение и дальнейшее изменение тех вариантов химической структуры, степень сродства которых приближается к заранее заданной степени сродства.
44. Способ по п.43, отличающийся тем, что стадия создания физической модели рецептора включает генерацию рецепторной линейной последовательности символов, которая кодирует пространственное распределение и заряд, и тем, что стадия создания физической модели химической структуры включает генерацию линейной последовательности символов, которая кодирует пространственное распределение и заряд.
45. Способ по п.44, отличающийся тем, что указанные линейные последовательности символов для указанной химической структуры содержат множество последовательных триплетов символов, причем первый символ указанного триплета произвольно выбирается из набора первых символов, определяющих позицию и тождественность "заселяющего" атомр т скелете молекулы указанной химической структуры, второй символ указанного триплета произвольно выбирается из набора вторых символов, определяющих тождественность заместителя, связанного с указанным "заселяющим" атомом, а третий символ указанного триплета произвольно выбирают из набора третьих символов, определяющих местоположение заместителя при атоме, точно определяемом первым символом триплета.
46. Способ по п.45, отличающийся тем, что линейную последовательность символов химической структуры декодируют, применяя алгоритм сборки эффективной молекулы, который последовательно перемещает каждый триплет из указанной молекулярной линейной последовательности, а затем насыщает незаполненные позиции при указанном молекулярном скелете атомами водорода.
47. Способ кодирования химической структуры, содержащей атомные элементы, при этом способ заключается в создании линейной последовательности символов, которая кодирует пространственное распределение, относительную позицию атома, тип связи и заряд для каждого атома с целью определить единственную трёхмерную конформацию указанной химической структуры.
48. Способ по п.47, отличающийся тем, что указанная линейная последовательность символов для указанной химической структуры содержит множество последовательных триплетов символов, причем первый символ указанного триплета произвольно выбирается из набора первых символов, определяющих позицию и тождественность "заселяющего" атома в скелете молекулы указанной химической структуры, второй символ указанного триплета произвольно выбирается из набора вторых символов, определяющих тождественность заместителя, связанного с указанным "заселяющим" атомом, а третий символ указанного триплета произвольно выбирают из набора третьих символов, определяющих местоположение заместителя при атоме, точно определяемом первым символом триплета.
49. Способ по п.45, отличающийся тем, что линейную последовательность символов декодируют, применяя алгоритм сборки эффективной молекулы, который последовательно перемещает каждый триплет из указанной линейной последовательности символов и затем насыщает незаполненные позиции у этого молекулярного скелета заранее выбранными атомами.
50. Способ по п.49, включающий операцию хранения указанной линейной последовательности символов в запоминающем устройстве компьютера.
51. Способ по п.19, отличающийся тем, что указанной функциональной характеристикой является биологическая токсичность.
52. Способ по п.19, отличающийся тем, что указанной функциональной характеристикой является каталитическая активность.
Текст
1 Область, к которой относится изобретение Данное изобретение относится к способам,предусматривающим создание химических структур, обладающих общими полезными функциональными свойствами, с использованием компьютера и основанным на специфических комбинациях пространственной конфигурации и сродства к связыванию. Более конкретно, данное изобретение предусматривает способ получения моделированных при помощи компьютера рецепторов, которые функционально имитируют биологические рецепторы. Моделированные рецепторы создаются для того, чтобы обеспечить оптимальное селективное сродство к известным молекулам мишеней. Затем генерируются и химические структуры, которые проявляют селективное сродство к моделированным рецепторам. Предпосылки создания изобретения Биологические рецепторы представляют собой линейные полимеры либо аминокислот,либо нуклеотидов, цепи которых укладываются с созданием трхмерных оболочек для связывания субстрата. Расположение этих специфических трхмерных линейных структур и размещение заряженных сайтов на поверхности оболочек является результатом эволюционного выбора на основе функциональной эффективности. Селективность биологических рецепторов зависит от величины сил притяжения и отталкивания, возникших между рецептором и субстратом. Величина этих сил изменяется с изменением величины и близости заряженных сайтов на поверхностях рецептора и субстрата. Поскольку субстраты различаются по числу и величине заряженных сайтов, имеющихся или наведенных на этих поверхностях, а также пространственному расположению этих сайтов,сродство к связыванию может изменяться в зависимости от структуры субстрата. Субстраты со сходным сродством к связыванию с одним и тем же рецептором очень похожи друг на друга по пространственному расположению, по меньшей мере, некоторых наведенных и фиксированных заряженных сайтов. Если функция рецептора коррелируется со сродством к связыванию, тогда субстраты со сходным сродством к связыванию должны быть функционально подобны по своему действию. В этом смысле можно сказать, что рецептор распознает или определяет количественно сходство субстратов. Традиционные методы, используемые для молекулярного распознавания идентичности или определения новых химических соединений или субстратов, имеющих селективное сродство к связыванию рецепторов, основаны на нахождении молекулярных общих подграфов активных субстратов и их использовании для предсказания новых похожих соединений. Недостаток такой методики заключается в том, что она основана на предположении, что субстраты,проявляющие сходную эффективность связыва 001095 2 ния, структурно подобны. Однако во многих случаях субстраты, отличающиеся по структуре,могут проявлять сходное сродство к связыванию с одним и тем же рецептором. Более поздние методики, основанные на определении количественных соотношений структураактивность (QSAR), пригодны только для создания новых соединений одного класса структур и почти не годятся при создании новых молекулярных структур, проявляющих желательное селективное сродство, см., например, Dean,Philip M., "Molecular Recognition: The Measurement and Search For Molecular Similarity in Ligand-Reseptor Intreaction", in Concepts and Applications of Molecular Similarity, Ed. Mark A. Johnson and Gerald M. Maggiora, pp. 211-238 (1990). Недавние попытки были направлены на создание атомных моделей или псевдорецепторов, в которых атомы и функциональные группы связаны, или мини-рецепторов, представляющих собой несвязанные наборы атомов или функциональных групп (Snyder, J.P. (1993) In 3D QSAR in Drug Design: Theory, Methods andApplications; Kubini, H. Ed.; Escom, Leiden. P. 336). Другие методы включают создание вокруг лигандов известной мишени оболочки из ряда атомов модели и расчет межмолекулярных сил,возникших между лигандом и моделью рецептора. Такие модели характеризуются высокой степенью корреляции между рассчитанной энергией связывания и биологической активностью (Walters, D.E. and Hinds, R.M. (1994) J.Medic. Chem. 37: 2527), но они не были разработаны до такой степени, когда можно получить новые химические структуры, обладающие селективным сродством к моделям рецепторов. Следовательно, было бы очень желательно создать способ определения нетривиального сходства между различными химическими структурами, которое достаточно и необходимо для объяснения их общих свойств, которые могут быть затем использованы в качестве основы для создания новых химических структур с полезными функциональными свойствами, основанный на специфических комбинациях пространственной конфигурации и сродства к связыванию. Сущность изобретения Данное изобретение предусматривает способ определения нетривиального сходства различных химических структур, которое необходимо и достаточно для объяснения их одинаковых функциональных свойств. Способ также предусматривает создание новых химических структур, которые проявляют сходные функциональные свойства. Принцип, лежащий в основе данного изобретения, заключается в использовании двухстадийного компьютерного способа для создания или открытия химических структур с полезными функциональными свойствами на основе специфических комбинаций стерической кон 3 фигурации и сродства к связыванию. На первой стадии этого процесса используют алгоритмическую эмуляцию образования антитела для создания популяции моделированных при помощи компьютера рецепторов, которые имитируют биологические рецепторы с оптимизированным сродством к связыванию с выбранными субстратами-мишенями. На второй стадии процесса используют моделированные или виртуальные рецепторы для того, чтобы оценить сродство к связыванию существующих соединений или создать новые субстраты с оптимальным связыванием. Способ, описанный в данной заявке, предусматривает создание моделированных рецепторов, которые имитируют выбранные признаки биологических рецепторов, включая эволюционные процессы, которые оптимизируют их селективность к связыванию. Миметики или моделированные рецепторы, созданные этим способом, можно использовать для распознавания специфического сходства между молекулами. Подобно антителам и другим биологическим рецепторам моделированные рецепторы по изобретению представляют собой механизмы извлечения признаков: они могут быть использованы для идентификации или распознавания общих или подобных структурных признаков субстратов-мишеней. Связывание между рецепторами и субстратами-мишенями используется для распознавания признаков. Субстратымишени могут быть количественно классифицированы на основе величины связывания со специфическим моделированным рецептором. Соединения, имеющие общие особые структурные признаки, будут также обладать сходным связыванием с одним и тем же виртуальным рецептором. Сродство между биологическими рецепторами и субстратами определяется стерическим соответствием между смежными поверхностями рецептора и субстрата, отсутствием воды между неполярными сайтами двух поверхностей и величиной электростатических сил, возникших между соседними заряженными сайтами. В некоторых случаях образование ковалентных связей между субстратом и рецептором также вносит свой вклад в величину связывания. Моделированные рецепторы, полученные этим способом, имитируют механизмы связывания их биологических двойников. Средняя величина близости поверхностей рецептора и мишени и величина силы электростатического притяжения,возникшего между заряженными центрами на обеих поверхностях, используются для определения величины сродства к связыванию. Полученные величины используют для оценки молекулярного сходства субстратов. Величина связывания может в общем зависеть от взаимодействия между всей поверхностью субстрата и закрытым рецептором или оболочкой рецептора, полностью окружающей 4 субстрат. В этом случае анализ общего сходства между субстратами является основой для установления полезных количественных отношений структура-активность. Однако в большинстве,если не во всех биологических системах, сродство определяется скорее локально, а не глобально. В общем, взаимодействие между молекулами субстрата и биологическими рецепторами ограничивается контактами между изолированными фрагментами поверхностей рецептора и субстрата. В этой ситуации исследование общего (глобального) сходства между субстратами не подходит как метод исследования взаимосвязи структура-активность, так как в образовании связывания участвуют только фрагменты субстрата. Структуры, имеющие локальное сходство,обладают одинаковыми структурными фрагментами в одинаковых положениях и ориентациях. Структуры, имеющие локальное сходство, необязательно имеют глобальное сходство. Выборка молекулярных свойств может быть достигнута методом полного отбора проб, включающим оценку глобального сходства; методом фрагментарного отбора проб, включающим оценку локального сходства, и методом фрагментарного множественного отбора проб,включающим оценку и локального, и глобального сходства. Анализ локального сходства основан на отборе проб дискретных участков субстратов для сходных структур и определении распределения зарядов. В биологических рецепторах локальный отбор проб возможен вследствие нерегулярности или неровностей прилегающих поверхностей субстрата и рецептора. Взаимодействие между близко расположенными противоположными поверхностями будут преобладать над взаимодействиями между более удаленными участками при определении сродства к связыванию. Близость прилегающих поверхностей будет также определять силу гидрофобного связывания. Эффективные моделированные рецепторы, полученные по данному способу,должны использовать локальный дискретный отбор проб субстратов-мишеней (молекул) для оценки функционально релевантного сходства соединений. Определение локального сходства осложняется двумя факторами: 1) число, расположение и идентичность релевантных фрагментов,необходимых и достаточных для специфического связывания, обычно не могут быть установлены простой дедукцией на основе химической структуры субстрата; и 2) положения и ориентация фрагментов, отобранных в ходе анализа,зависят от структуры всей молекулы. Часть данного метода, направленного на получение моделированных рецепторов, способных классифицировать сходство между химическими субстратами, в основном представляет собой поиск рецепторов, которые являются 5 образцами релевантных фрагментов субстратов в релевантном положении в пространстве. Процесс оптимизации основывается на четырех признаках моделированных рецепторов: 1) универсальности: способности рецепторов связывать более одного субстрата; 2) специфичности: связывание рецепторов зависит от структуры субстрата; 3) экономичности: рецепторы различают субстраты по минимальному набору локальных структурных признаков; и 4) мутабильности: изменение структуры рецептора может изменить его сродство к связыванию специфического субстрата. Кодирование фенотипа рецептора в виде линейного генотипа, представленного характерной нитью, облегчает процессы мутации, рекомбинации и наследования структурных характеристик моделированных рецепторов. Моделированные рецепторы, которые удовлетворяют этим основным критериям, могут быть оптимизированы для достижения специфического связывания с локально подобными субстратами с использованием методов эволюционного селективного воспроизводства. Это осуществляется путем кодирования пространственной конфигурации и распределения заряженных сайтов рецептора в наследуемом формате, который может подвергаться изменениям или мутациям. Подобно биологическим рецепторам моделированные рецепторы, полученные этим методом, определяют трехмерное пространство отчуждения. Такое трехмерное пространство может быть очерчено в произвольной степени разрешения одномерной линией достаточной длины и извитости. Белки, образованные линейными полимерами аминокислот, являются примерами таких структур. Подобным образом трехмерная структура моделированных рецепторов может быть кодирована как линейное образование изменяющихся команд. Эта одномерная кодированная форма рецептора представляет собой его генотип. Декодированная форма,используемая для достижения связывания,представляет собой его фенотип. В процессе оптимизации осуществляются изменения (мутации) генотипа рецептора. Затем оценивается влияние этих изменений на сродство фенотипа к связыванию. Генотипы, генерирующие фенотипы с заданным сродством к связыванию, сохраняются для дальнейшего изменения, пока не достигается за счет итерации мутации и процесса селекции желаемая степень оптимизации фенотипа. Для создания популяций моделированных рецепторов с оптимальными величинами связывания могут быть использованы разнообразные эволюционные методы, включая классические генетические алгоритмы-рецепторы, полученные этим методом, используют затем для генерирования или идентификации новых химических структур (соединений), которые обладают специфическими полезными свойствами молекулярных мишеней, используемыми как 6 критерий выбора при получении моделированных рецепторов. При использовании взаимодействия с рецепторами в качестве критерия выбора создаются новые химические структуры, оптимально соответствующие рецепторам. Поскольку эти структуры должны удовлетворять требованиям, необходимым и достаточным для обеспечения селективности рецепторов, они должны также обладать биологической активностью, подобной активности исходных молекулярных мишеней. Популяция моделированных рецепторов с улучшенной селективностью может также быть использована для скрининга существующих химических структур для соединений с высоким сродством, которые могут обладать этими полезными свойствами. Тот же самый способ может быть использован для скрининга соединений с выбранными токсикологическими или иммунологическими свойствами. Согласно одному аспекту данного изобретения предусматривается компьютерный метод создания химических структур, имеющих заданные функциональные характеристики, включающий операции:(а) создания физической модели фенотипа моделированного рецептора, кодированного в линейной характерной последовательности и создания набора молекул мишеней, обладающих, по меньшей мере, одной общей количественной функциональной характеристикой;(б) для каждой молекулы мишени:(i) определения величины сродства между рецептором и молекулой мишени в каждой из множества ориентаций с использованием расчета эффективного сродства;(ii) определения суммарного сродства путем суммирования рассчитанных величин сродства;(iii) идентификации максимальной величины сродства;(в) использования рассчитанной суммарной и максимальной величин сродства для:(i) определения максимального коэффициента корреляции сродства между максимальными величинами сродства и количественной функциональной характеристикой;(ii) определения суммарного коэффициента корреляции сродства между суммарным сродством и количественной функциональной характеристикой;(г) использования максимального коэффициента корреляции и суммарного коэффициента корреляции для определения коэффициента соответствия;(д) изменения структуры рецептора и повторение операций (б) - (г) до тех пор, пока не будет получена популяция рецепторов, обладающих заданным коэффициентом соответствия;(е) создания физической модели химической структуры, кодированной в молекулярной 7 линейной характерной последовательности, определения сродства между химической структурой и каждым рецептором во множестве ориентаций с использованием указанного определения эффективного сродства, использования определенных величин сродства для определения степени соответствия сродства;(ж) изменения химической структуры для получения варианта химической структуры и повторения операции (е); и(з) сохранения и дальнейшего изменения тех вариантов химической структуры, степень сродства которых приближается к заданной величине. Согласно другому аспекту изобретения предусматривается метод скрининга химических структур для получения заданных функциональных свойств, включающий:(а) получение генотипа моделированного рецептора генерированием линейной последовательности признаков рецептора, которая кодирует пространственное расположение и заряд;(б) декодирование генотипа для получения фенотипа рецептора, создание, по меньшей мере, одной молекулы мишени, проявляющей заданную функциональную характеристику, расчет сродства между рецептором и каждой молекулой мишени во множестве ориентаций с использованием расчета эффективного сродства,нахождение суммарного и максимального сродства между каждой молекулой мишени и рецептором, определение суммарного коэффициента корреляции сродства для зависимости суммарного сродства от указанной функциональной характеристики молекулы мишени и максимального коэффициента корреляции сродства для зависимости максимального сродства от указанной функциональной характеристики и расчета коэффициента соответствия в зависимости от указанных суммарного и максимального коэффициентов корреляции сродства;(в) мутацию генотипа и повторение операции (б) и сохранение и мутацию тех рецепторов,которые обладают повышенными коэффициентами соответствия до тех пор, пока не образуется популяция рецепторов с заданными коэффициентами соответствия;(г) расчета сродства между химической структурой, скрининг которой проводится, и каждым рецептором во множестве ориентаций с использованием указанного эффективного расчета сродства, расчета степени соответствия сродства, который включает вычисление суммарного и максимального сродства между соединением и каждым рецептором и сравнения,по меньшей мере, одного из указанных суммарного и максимального сродства с суммарным и максимальным сродством, по меньшей мере,одной мишени и указанной популяции рецепторов, причем указанное сравнение является показателем уровня функциональной активности указанной химической структуры по отноше 001095 8 нию к, по меньшей мере, одной молекуле мишени. Согласно еще одному аспекту изобретения предусмотрен метод создания моделированных рецепторов, имитирующих биологические рецепторы, обладающие селективным сродством к соединениям со сходными функциональными характеристиками, включающий операции:(а) получения генотипа моделированного рецептора путем генерации линейной последовательности рецептора, которая кодирует пространственное расположение и заряд;(б) декодирования генотипа для получения фенотипа рецептора, создания набора молекул мишеней, обладающих сходными функциональными характеристиками, расчета сродства между рецептором и каждой молекулой мишени во множестве ориентаций с использованием эффективного расчета сродства, расчета суммарного и максимального сродства между каждой молекулой мишени и рецептором, расчета суммарного коэффициента корреляции сродства для зависимости суммарного сродства от функциональной характеристики для каждой молекулы мишени и максимального коэффициента корреляции сродства для зависимости максимального сродства от указанной функциональной характеристики для каждой молекулы мишени и расчета коэффициента соответствия в зависимости от указанных суммарного и максимального коэффициентов корреляции сродства для каждой молекулы мишени; и(б) и сохранение и мутация тех рецепторов, которые обладают повышенными коэффициентами соответствия до получения популяции рецепторов с заданными коэффициентами соответствия. Согласно дальнейшему аспекту данного изобретения предусматривается компьютерный метод создания химических структур с заданной функциональной характеристикой, включающий операции:(а) создания физической модели рецептора и набора молекул мишеней, причем последние обладают, по меньшей мере, одной поддающейся количественному определению функциональной характеристикой;(б) для каждой молекулы мишени:(i) определения сродства между рецептором и молекулой мишени в каждой из множества ориентаций с использованием расчета эффективного сродства;(ii) расчета суммарного сродства путем суммирования найденных величин сродства;(в) использования рассчитанных величин суммарного и максимального сродства для того,чтобы:(i) рассчитать максимальный коэффициент корреляции сродства между максимальным сродством и поддающейся количественному(ii) рассчитать суммарный коэффициент корреляции сродства между суммарным сродством и поддающейся количественному определению функциональной характеристикой;(г) использования максимального коэффициента корреляции и суммарного коэффициента корреляции для расчета коэффициента соответствия;(д) изменения структуры рецептора и повторения операций (б) - (г) до тех пор, пока не образуется популяция рецепторов с заданным коэффициентом соответствия;(е) создания физической модели химической структуры, определения сродства между химической структурой и каждым рецептором во множестве ориентаций с использованием указанного расчета эффективного сродства, использования рассчитанных величин сродства для нахождения степени соответствия сродства;(ж) изменения химической структуры для создания варианта химической структуры и повторения стадии (е); и(з) сохранения и дальнейшего изменения тех вариантов химической структуры, чья степень соответствия сродства приближается к заданной величине. Согласно еще одному аспекту изобретения предусматривается метод кодирования химических структур, включающих атомные элементы,причем метод включает создание линейной характерной последовательности, которая кодирует пространственное расположение и заряд для каждого атома указанной химической структуры. Краткое описание фигур Ниже данное изобретение будет проиллюстрировано на примере со ссылкой на прилагаемые фигуры. На фиг. 1 представлена схема, показывающая соотношение между созданием кода генотипа и трансляцией с получением соответствующего фенотипа, отражающая часть данного изобретения; на фиг. 2 показана общая схема, отражающая операции оптимизации рецептора для селективного связывания с рядом субстратов с использованием точечных мутаций, отражающая часть данного изобретения; на фиг. 3 показана общая схема операций способа получения популяции рецепторов с оптимальным сродством к селективному связыванию с рядом химических субстратов и использования этих оптимизированных рецепторов для получения ряда новых химических субстратов с общими одинаковыми функциональными характеристиками; на фиг. 4 а представлены несколько химических соединений, использованных в примере,относящемся к генерации лигандов; 10 на фиг. 4b показаны лиганды 1.1-1.4, полученные методом по данному изобретению в примере, иллюстрирующем генерацию лигандов, где каждый лиганд имеет, по меньшей мере, одну ориентацию, при которой он структурно подобен бензальдегиду; на фиг. 4 с представлены лиганды 2.1-2.4,полученные методом по данному изобретению в примере, иллюстрирующем генерацию лигандов, относящейся к созданию химических структур, проявляющих эффективность при отпугивании комаров. Описание предпочтительных вариантов Данный способ можно разбить на две части: (А) эволюция популяции моделированных рецепторов с селективным сродством к соединениям с общими функциональными свойствами и (Б) образование новых химических структур, имеющих общие функциональные свойства. Часть (А) состоит из нескольких операций,включая 1) генерацию генотипа и фенотипа рецептора; 2) генерацию мишени; 3) презентацию известных химических структур(ы) рецептору; 4) оценку сродства рецептора к химической структуре(ам); 5) оценку селективности рецептора по отношению к химической структуре(ам); 6) эволюцию семейства родственных рецепторов с оптимизированными селективным сродством к химической структуре(ам); скрининг химических субстратов для оценки токсикологии и фармакологической активности и использование оптимизированных рецепторов для создания новой химической структуры(структур) с селективным сродством к рецепторам. Нижеследующее описание лучшего примера осуществления изобретения относится к различным таблицам молекулярных и атомных радиусов, поляризуемостей, величин эффективного диполя и факторов переходных состояний и присоединения, эти величины приведены в табл. 1-5, приведенных в конце описания. Схемы, иллюстрирующие примеры расчетов, не ограничивающие изобретение, представлены в конце описания в виде модулей 1-14. Часть А: Эволюция популяции моделированных рецепторов, обладающих селективным сродством к молекулам мишеней,имеющим общие функциональные свойства(1) Генерация кода генотипа и фенотипа рецептора И генотипы, и фенотип моделированного рецептора представляют собой рассчитанные объекты. Фенотипы моделированных рецепторов состоят из складчатых неразветвленных полимеров сферических субъединиц, диаметр которых равен радиусу Ван дер Ваальса для атомного водорода (110 пм). Субъединицы могут быть связаны друг с другом в любых двух из шести точек, соответствующих отрезкам сфер с каждой из их основных осей. В данном случае связи между субъединицами не могут 11 вытягиваться или вращаться, и центры двух связанных субъединиц всегда отделены расстоянием, равным длине их сторон (т.е. радиусу 1 водорода). Когда две субъединицы не прилегают к противоположным поверхностям их общего соседа, возникают повороты (витки). Возможны четыре вида ортогональных поворотов: левый,правый, верхний и нижний. Повороты должны быть параллельны одной из основных осей. Для упрощения вычислений в том случае, когда повороты пересекаются с другими субъединицами в полимере, принимают, что субъединицы занимают одно и то же пространство с другими субъединицами. Моделированный рецептор состоит из одного или нескольких дискретных полимеров. В случае рецепторов, состоящих из многих полимеров, индивидуальные полимеры могут располагаться в различных точках пространства. Для упрощения в данном случае принимают, что все полимеры, составляющие один рецептор, имеют одну и ту же длину (= числу субъединиц). Это ограничение не является требованием для функциональности, и для моделирования специфических систем могут быть пригодны полимеры с разной длиной. Структура каждого полимера кодируется как последовательный набор изменяющихся команд. Эти команды определяют отдельные изменения по отношению к внутренней рамке обозначения, основанной на первоначальной ориентации первой субъединицы в каждом полимере. Гидраты рецептора и субстрата в данном случае не обрабатываются, вместо этого предполагается, что любые молекулы воды, имеющиеся на участке связывания, постоянно присоединены к поверхности рецептора и входят в его структуру. Это произвольное приближение,и специалистам очевидно, что можно осуществить более точную обработку (см., например,VanOss, 1995, Molecular Immunology 32:199211). Как видно из фиг. 1, модуль создания кода генерирует произвольные нити признаков. Каждый признак представляет изменяющуюся команду или определяет характеристики заряда или реактивность в точке в трхмерной форме,представляющей собой виртуальный рецептор. Для создания нити, описывающей трхмерную форму рецептора в Картезианской (прямоугольной) системе координат, требуется минимум пять различных признаков. Другие системы,например, тетраэдральные структуры, также могут быть созданы с использованием различных наборов изменяющихся команд. Признаки представляют изменяющиеся команды, которые определены в отношении текущего направления в структуре виртуального рецептора в трхмерном пространстве (т.е. команды относятся к рамке обозначения, присущей виртуальному 12 рецептору, а не к произвольной внешней рамке обозначения). Изменяющиеся команды даны по отношению к направлению тока и ориентации полимера. Разрешаются только левые, правые, верхние и нижние повороты. Если поворот не возникает,цепь полимера или заканчивается, или продолжается в том же направлении. Для прямоугольной системы существует следующий минимальный набор признаков: С 1= нет поворота; С 2 = правый поворот; С 3 = левый поворот; С 4 = верхний поворот и С 5 = нижний поворот. Ясно, что команды могут быть объединены для создания поворотов по диагонали,например, А 1,2 = С 1 С 2; А 2,1 = С 2 С 1 и т.д. Число различных признаков, которые определяют различные заряды или реактивные состояния, не ограничено и может быть подобрано в соответствии с эмпирическими данными. Коды могут отличаться друг от друга по длине (числу признаков) и частоте, с которой конкретные признаки появляются в сериях. Пример создания генотипа. Специалистам очевидно, что нижеследующий пример создания кода генотипа и экспрессии фенотипа является только иллюстративным. В этом примере применяются следующие условия.(1) Набор символов, используемых для образования кодов, состоит из пяти символов, относящихся к изменяющимся командам, и двух символов, идентифицирующих заряженный сайт: "0" = нет поворота; "1" = правый поворот;= нижний поворот; "5" = положительно заряженный сайт (нет поворота) и "6" = отрицательно заряженный сайт (нет поворота).(2) Субъединицы делятся на два типа: заряженные и незаряженные. Предполагается, что все заряженные субъединицы несут единичный положительный или отрицательный заряд. Однородная величина заряда является произвольным условием.(3) Рецепторы содержат 15 дискретных полимеров. Длина полного кода всегда кратна пятнадцати. Длина каждого полимера равна длине всего кода, деленной на пятнадцать. Очевидно, что рецепторы могут быть созданы из любого количества дискретных полимеров с изменяющейся или постоянной длиной.(4) Пользователем определены следующие параметры: (а) общая длина кода (и длина полимера); (б) частота, с которой каждый символ появляется в коде; и (в) наличие комбинаций символов. Модуль 1 представляет пример схемы создания кода генотипа. Пример создания фенотипа рецептора. Каждый код генотипа подвергается трансляции для создания трехмерного описания соответствующего фенотипа или виртуального рецептора. Для превращения изменяющихся команд в серию координатных триплетов, которые 13 описывают положение последовательных субъединиц, представляющих собой полимеры рецептора, используется алгоритм трансляции из заданной исходной точки. Исходные координаты для каждого полимера должны быть заданы до трансляции. Трансляция предполагает, что центры последовательных субъединиц отделены друг от друга расстоянием, равным ковалентному диаметру атома водорода. Алгоритм трансляции считывает кодированную нить последовательно с образованием последовательных поворотов и прямых отрезков. Интерпретация последовательных поворотов по отношению к внешней системе координат зависит от предшествующей последовательности поворотов. Предполагается, что для каждого полимера, образующего рецептор, начальная ориентация одинакова. В данном случае алгоритм трансляции описан в табл. 1, показывающей состояния на входе и выходе. Если поворот не образуется, для определения нового координатного триплета используются самые последние величины для х, у, z и новые состояния. Сайты зарядов обрабатываются как прямые (без поворотов) отрезки. Начальная величина старого состояния равна 20. Пользователем могут быть определены следующие параметры: а. Исходные координаты для каждого полимера, образующего рецептор. Выходные данные хранятся в виде: а) трех векторов (один для каждой оси: х 1,х 2, x3, , хn, у 1, , yn, z1, , zn). б) трехмерной бинарной матрицы. в) отдельных векторов для координат сайтов зарядов. Пример трансляции кода приведен в модуле 2.(2) Генерация мишени Мишени представлены в виде молекул, состоящих из сферических атомов. Считается, что атомы являются твердыми сферами с фиксированными радиусами для каждого вида атомов. Радиус твердой сферы, при котором сила отталкивания, действующая между атомами мишени и виртуальным рецептором, считается бесконечно большой величиной, аппроксимируется радиусом Ван дер Ваальса, приведенным в табл. 2. Другие примерные величины радиуса Ван дер Ваальса могут быть использованы вместо величин, приведенных в табл. 2. Расстояние между атомными центрами двух атомов, связанных ковалентной связью,выражено в виде суммы радиусов их ковалентных связей. Радиусы ковалентных связей изменяются с изменением порядка связи в виде атомов. Примеры подходящих величин радиусов приведены в табл. 3. Как первое приближение предполагается, что длина связи фиксирована(т.е. игнорируются вибрации связей). Допускается вращение связей, и для выборки представительных ротационных состояний требуются 14 многочисленные конфигурации одной и той же структуры. Стабильность конфигураций не рассматривается, поскольку связывание с виртуальным рецептором может стабилизировать энергетически нестабильные конфигурации. Для образования лигандов мишеней можно применять различные алгоритмы минимизации энергии. Электрические заряды, обусловленные дипольными моментами связей, считаются локализованными в атомных ядрах. Отрицательный заряд переносится атомом с большей величиной электроотрицательности. Величины диполей,используемые в данном случае, приведены в табл. 4. Вместо величин, указанных в табл. 4,можно использовать другие величины диполей.(3) Презентация мишеней Сродство каждой мишени к моделированному рецептору(ам) испытывается для нескольких ориентаций мишени относительно верхней поверхности рецептора. Верхняя поверхность определяется алгоритмом сдвига. Перед оценкой сродства к связыванию мишень и рецептор должны быть приведены в контакт. Контакт возникает, когда расстояние между центрами,по меньшей мере, одной субъединицы рецептора и, по меньшей мере, одним атомом мишени равно их объединенным радиусам Ван дер Ваальса. Для того чтобы определить относительные положения мишени и рецептора в точке контакта, мишень перемещают с приращением по направлению к поверхности рецептора вдоль траектории, перпендикулярной поверхности и проходящей через геометрические центры и рецептора, и мишени. При возникновении контакта мишень достигает положения коллизии с рецептором. Перемещенные атомы мишени,когда достигается положение коллизии, используются для расчета расстояний между атомами мишени и субъединицами рецептора. Эти расстояния используются для определения силы электростатических взаимодействий и проксимальности. В данном случае предполагается, что мишень перемещается по прямой линии по направлению к рецептору и сохраняет свою начальную ориентацию в момент контакта. Альтернативный подход позволил бы мишени менять свою ориентацию с приращением по мере приближения к рецептору таким образом, чтобы положение максимального сродства достигалось в точке контакта. Хотя этот метод функционально подобен используемому, он гораздо более сложен для вычислений. В данном случае многочисленные ориентации испытывают при использовании более простого вычислительного аппарата. Данный метод предусматривает регулируемое замещение траектории вдоль оси "x" и/или "у" рецептора для размещения более крупных молекул. Это требуется для повышения селективности, когда на одном и том же 15 рецепторе испытывают молекулы, отличающиеся по размеру. Перед определением положения соприкосновения ориентация мишени рандомизируется случайным вращением с приращением в 6 вокруг каждой из x, у и z-осей. Можно использовать большие или меньшие величины приращения. В данной серии испытаний каждая из этих случайных ориентаций мишени является единственной. Надежность процесса оптимизации зависит от числа ориентаций используемой мишени, а также от числа оцениваемых соединений мишеней. Пример осуществления способа презентации мишеней показан в модуле 3.(4) Расчет сродства Стратегия аппроксимации. Данный вариант осуществления способа основан на упрощенной аппроксимации, которая сводится к оценке основных компонентов,участвующих в связывании, с использованием сравнительно простого вычислительного аппарата. Аппроксимация описана в следующих разделах. Однако специалистам очевидно, что можно использовать более точные методы расчета, которые позволяют получить более точное значение сродства. Известные пакеты программ для определения более точных значений сродства могут быть использованы в данном способе. Исследования краун-эфиров показывают,что распределение электронной плотности малых молекул можно использовать для описания электронных плотностей соединений с большими молекулами (Bruning, Н. fnd Feil, D. (1991) J.Comrut. Chem. 12:1). Для определения распределения строго локальных зарядов, характеризующихся зарядом и дипольным моментом,можно использовать метод (Hirshfeld, F.L.(1977) Theor. Chem. Acta 44:129). Результатом является распределение общей электронной плотности молекулы на перекрывающиеся атомные части, размеры которых связаны с радиусами свободных атомов. На примере краун-эфиров можно показать,что основные компоненты электростатического взаимодействия определяются скорее местным,чем глобальным перемещением зарядов между атомами. Распределение зарядов в основном распределяется эффектом небольших интервалов, обусловленным различными химическими связями. В частности, не являющиеся соседними атомы вносят небольшой вклад в дипольные моменты атомов. Кроме того, хотя на передачу зарядов между атомами также влияет электростатическое поле всей молекулы, расчеты для краун-эфиров показывают только очень небольшое влияние на распределение зарядов. Определенные величины атомных зарядов и дипольных моментов могут быть использованы для описания электростатического взаимодействия (Bruning, H. fnd Feil, D. (1991) J. Comrut. Chem. 12:1). Помимо радиуса Ван дер Ваальса, только небольшой вклад вносят атомные 16 квадрупольные моменты. Расчет электростатического потенциала, который учитывает только атомные заряды, дает очень плохие результаты,в то время как использование дипольных моментов позволяет получить более точные величины. На основании этих рассуждений можно сказать, что метод по данному изобретению использует аппроксимацию сродства между лигандом мишени и моделированным рецептором(ами), созданными на основе двух величин. 1. Величина электростатических сил, действующих между заряженными субъединицами моделированного рецептора(ов) и атомными диполями лиганда мишени (химической структуры). Предполагается, что поскольку заряженные субъединицы переносят непередающиеся единичные заряды, величина этих сил прямо пропорциональна величине атомного диполя и обратно пропорциональна расстоянию между моделированным рецептором и атомным диполем лиганда. 2. Отношение неполярных или незаряженных субъединиц моделированного рецептора,достаточно близких к неполярным участкам лиганда для образования значительных дискретных сил Лондона. Предположения, используемые для расчета(определения) сродства согласно данному варианту осуществления способа. 1. Предполагается, что химические субстраты-мишени, исследуемые согласно данному способу, являются нейтральными (т.е. неионизированными) молекулами. Это произвольное ограничение, но одну и ту же методику можно использовать для заряженных и незаряженных мишеней. 2. Предполагается, что дипольные моменты локализованы в атомных ядрах. Аналогичное определение сродства можно провести, предположив, что дипольный момент находится на ковалентной связи. Согласно Allingham et al.(1989), эти предположения функционально эквивалентны. 3. Предполагается, что окружающая виртуальный рецептор среда представляет собой растворитель, в котором растворена мишень. Мишень распределена между растворителем и виртуальным рецептором. 4. Предполагается, что в момент определения сродства мишень и рецептор являются неподвижными по отношению друг к другу и находятся в специфической фиксированной ориентации. 5. Предполагается, что мишени взаимодействуют только с двумя типами сайта на поверхности рецептора: сайтами с фиксированными зарядами (положительно или отрицательно заряженные) и неполярными сайтами. На основе этих предположений необходимо только рассмотреть следующие факторы, 17 которые вносят вклад в величину силы взаимодействия. 1. Заряд-диполь Согласно данному методу при аппроксимации рассматриваются только относительные силы, следовательно, пренебрегают всеми константами. Кроме того, предполагается, что сайт с фиксированным зарядом является унитарным и или положительно, или отрицательно заряженным. Основываясь на этом, можно представить вышеприведенные выражения в следующем упрощенном виде: В общем факторы 2 и 3 вносят только незначительный вклад во взаимодействие. Однако факторы 1 и 4 значительно влияют на величину энергии взаимодействия. Согласно данной методике предполагается, что большая часть взаимодействий между неполярными фрагментами происходит между смежными алкильными группами и водородами ароматических соединений и неполярными субъединицами рецептора. Предполагается, что при этих условиях величинаявляется постоянной. Вклад гидрофобной силы и исключения воды. При определении сродства к связыванию важное значение имеют эффекты сольватации. Например, образование гидрофобной связи основывается на близкой пространственной ассоциации неполярных гидрофобных групп, при этом контакт между гидрофобными участками и молекулами воды уменьшается до минимума. Вклад образования гидрофобной связи равен половине величины общей прочности связей антитело-антиген. Гидратация поверхностей рецептора и субстрата также является значительным фактором. Вода, связанная с полярными сайтами поверхности рецептора или субстрата, может влиять на связывание или увеличивать сродство за счет образования поперечных мостиков между поверхностями. Гидрофобное взаимодействие характеризует сильное притяжение между гидрофобными молекулами в воде. В случае взаимодействий рецептор-мишень следует указать на притяжение между неполярными фрагментами мишени и соседних доменов субъединиц неполярных рецепторов. Эффект появляется в основном вследствие энтропийных факторов, приводящих к перестройке поверхностей с исключением наличия воды между соседними неполярными доменами. Точные теоретические обоснования 18 гидрофобного взаимодействия отсутствуют,однако, установлено, что вклад гидрофобных сил составляет до 50% от величины силы притяжения между антителами и антигенами. Для определения гидрофобного взаимодействия между мишенями и виртуальными рецепторами данная методика предусматривает оценку части рецептора, которая эффективно защищена от сольватирования за счет связывания с мишенью. Считается, что все неполярные (незаряженные) субъединицы, которые находятся не далее фиксированного расстояния неполярных атомов мишени, защищены от сольватирования молекулами растворителя, диаметр которых равен или больше лимитирующего расстояния. Расчет общего сродства. Расчет общего сродства, используемый в данном методе, сочетает два компонента взаимодействия: суммарные силы взаимодействия заряд-диполь и величина близости. Предполагается, что в данном случае эти оба фактора являются изотропными. Специалистам в данной области очевидно, что можно получить большую степень разрешения, если используются анизотропные определения сродства, хотя вычисления при этом гораздо сложнее. Взаимодействие заряд-диполь рассчитывается как D=1/rijv, где 1=дипольный момент iго атома мишени и rij=расстояние между i-им атомом и j-им сайтом заряда на рецепторе, и коэффициент v может быть 2, 3 или 4. Вклад D в величину общего сродства более чувствителен к разделению зарядов для больших величин v. Мера проксимации определяется какP=ni/N, где ni=числу незаряженных субъединиц рецептора, которые определены максимальным расстояниемот i-го атома мишени с дипольным моментом 0,75 Дебая. В данном методеможет колебаться от 1 до 4 диаметров субъединицы (эта величина приближается к вандерваальсовому радиусу воды). N обозначает общее количество субъединиц, образующих рецептор. Величина сродства А рассчитывается по величинам D и Р с использованием следующего уравнения A=[P(D+NP/k)]0,5, где k обозначает константу соответствия (в данном случаеk=10000). Величина Р в уравнении играет две роли. В первом случае это весомый фактор. Как мера "высокой степени соответствия" она используется для того, чтобы перевесила величина сродства в отношении тех конфигураций, в которых неполярные участки мишени и рецептора находятся в тесном контакте. В этих условиях величины энергии гидрофобных взаимодействий будут большими и будут значительно влиять на стабильность и силу связи. В этих условиях у мишени имеется меньше возможных траекторий для того, чтобы избежать контакта, и время ее удержания будет больше. Во втором случае Р используется для оценки вклада энер 19 гии дисперсии в силу взаимодействия. Предполагается, что энергия дисперсии будет значительной только для незаряженных, неполярных сайтов и что она значительна только тогда, когда мишень и рецептор близки друг другу (т.е. когда расстояние между ними меньше ). Величины k имогут быть подобраны так, чтобы возможно было изменить относительный вклад Р и D. В общем Р доминирует в случае неполярных мишеней, а D более значительна для мишеней с большими локальными диполями. Связывание водорода аппроксимируется спаренными отрицательно и положительно заряженными единицами рецептора, одновременно взаимодействующими с гидроксильными, карбоксильными или аминными группами мишени. Альтернативные подходы к определению сродства-поляризуемости связи. В некоторых случаях в методику определения сродства может быть предпочтительным ввести параметр, соответствующий относительной поляризуемости атомов мишени. В этом случае уравнение для расчета Р 2 в равенствеA=[P(D+NP2/k)]0,5 не является: P2=ni/N. Вместо этoго Р 2 рассчитывается по уравнению Р 2=ini/N, где ni=числу заряженных или незаряженных субъединиц рецептора, которые определены максимальным расстояниемот i-го атома мишени, и i обозначает относительную поляризуемость i-го атома мишени. Для простоты Н для алифатического водорода принимается равной 1,0. Величина k должна быть подобрана, если используются поляризуемости. Величины поляризуемостей на основе сумм поляризуемостей соседних связей приведены в табл. 5. Поскольку поляризуемость связана со смещением электронного облака, поляризуемость молекулы может быть рассчитана как сумма поляризуемостей е ковалентных связей. Эта аддитивность действует для неароматических молекул, которые не имеют делокализованных электронов. Альтернативная методика-специфичность функциональных групп. Аппроксимация сродства, используемая в данном случае, может быть заменена функционально сходными вычислениями, при которых сохраняется отношение между локальными зарядами, дисперсионной энергией и расстоянием мишень-рецептор. Кроме того, могут быть определены величины сродства для заряженных мишеней. Данный метод оценивает только нековалентные взаимодействия, однако, метод может быть расширен при включении в виртуальный рецептор субъединиц, способных к реакциям образования специфичных ковалентных связей с выбранными функциональными группами мишени. Модуль 5 отражает пример схемы предпочтительного расчета эффективного сродства, используемого в данном изобретении.(5) Оценка селективного сродства Высокая степень соответствия между виртуальным рецептором и рядом субстратовмишеней оценивается при сравнении величины известной активности или сродства для мишеней с величинами, полученными для комплекса виртуальный рецептор-мишень. Максимальные величины сродства оптимального виртуального рецептора должны быть скоррелированы с известными величинами сродства. Последовательные повторения эволюционного процесса могут быть использованы для повышения степени этой корреляции (фиг. 3). Известными величинами могут быть любой показатель, который зависит (или предполагается, что зависит) от сродства к связыванию,включая (не ограничивая) ED50, ID50, сродство к связыванию и величины когезии. Испытуемые величины должны быть положительными. Может потребоваться логарифмическая трансформация данных. Нельзя использовать необоснованно ранжированные данные. Оптимальная ориентация мишеней для достижения максимального сродства к связыванию до опытов неизвестна. Для того чтобы получить репрезентативную величину значений сродства рецептора к мишени, каждую мишень следует испытать повторно, используя различные случайные ориентации относительно поверхности рецептора. В каждом опыте для оценки сродства используется Модуль 4. В общем, надежность полученных величин максимального сродства зависит от размера образца,так как возрастает вероятность того, что образец будет характеризоваться подлинной максимальной величиной. Тот же набор ориентаций мишени используется для испытания каждого рецептора. В данном способе используются две методики для того, чтобы избежать необходимости в наличии большого набора образцов для генерирования оптимизированных рецепторов: 1) использование метода измерения, объединяющего среднее (или суммарное) сродство и максимальное сродство для выбора рецепторов с более высокой селективностью; и 2) увеличение с приращением числа ориентаций, изучаемых с последовательными изменениями процесса оптимизации (оптимизация начинается с небольшого числа ориентаций мишени, как только генерируются рецепторы с высокой степенью соответствия, испытывается большее число ориентаций). В соответствии с данным методом определяется сумма величин сродства, полученных для всех испытанных ориентаций каждой мишени. Эта степень суммарного сродства является мерой средней величины сродства между рецептором и мишенью. В то же самое время также определяется величина максимального сродства. Рассматривается корреляция между известными значениями и как суммарным сродст 21 вом, так и максимальным сродством, чтобы получить rSA2 и rMA2 соответственно. Исходная точка (0,0) включена в корреляцию на основе предположения, что соединения-мишени, не проявляющие никакой активности, должны обладать небольшим сродством к виртуальному рецептору или не обладать сродством совсем. Это предположение не может быть всегда достоверным, и в некоторых опытах могут потребоваться другие величины. Корреляция суммарного сродства является мерой средней степени соответствия. Если эта корреляция значительна, а корреляция между максимальным сродством и известным сродством незначительна, результат предполагает, что виртуальный рецептор не является селективным, т.е. многочисленные ориентации мишени могут эффективно взаимодействовать с рецептором. Наоборот, если максимальное сродство коррелируется в значительной степени с известными величинами сродства и корреляция суммарного сродства мала, виртуальный рецептор может быть высоко селективным. Если и суммарное сродство, и максимальное сродство в значительной степени коррелируется с известным сродством, вероятно, что ориентации образцов идентифицировали характеристики реакции рецептора с ограниченными погрешностями (уменьшаются ошибки типа I и типа II: сходство неверного положительного или неверного отрицательного результата). В некоторых случаях может быть целесообразным свести к минимуму корреляцию между известными величинами сродства и величиной суммарного сродства, в то же время выбирая повышенную степень корреляции между максимальным сродством и известной величиной сродства. Такой выбор потребует вычитания максимального сродства из общей суммы, чтобы исключить эти величины, как неоднозначные. Согласно данному методу используется величина объединенной корреляции на основе выбора селекции. Эта величина определяется как квадратный корень произведения суммарного сродства и максимального сродстваF=(rMA2rSA2)0,5 Эта величина оптимизируется в эволюционном процессе, применяемом для виртуальных рецепторов. Примечание: Если rMA2 и rSA2 коррелируются в значительной степени друг с другом, тогда величины, влияющие на rSA2, должны или индивидуально коррелироваться с величиной максимального сродства, или незначительно влиять на суммарную величину. Помимо этого может быть рассчитана корреляция (rSA-MA) для зависимости величины (суммарное сродство- максимальное сродство) от известной величины сродства и критерийF=(rMA2(1-rSA-MA20,5 максимизирован. Использование этого критерия позволяет выбрать рецепторы, которые имеют 22 высокое сродство к очень ограниченному набору ориентаций мишени. Модуль 5 иллюстрирует схему расчета степени соответствия образца.(6) Процесс оптимизации Цель процесса оптимизации заключается в выявлении виртуального рецептора, который имеет селективное сродство к набору мишеней. Требуется высокоэффективный механизм нахождения решений, так как общее число возможных генотипов, содержащих 300 команд, равно 7300 или примерно 10253. Следующие четыре фазы суммируют стадии процесса оптимизации,причем каждая фаза обсуждается более подробно с приведением примеров расчетов. Фаза 1: Генерировать набор произвольных генотипов и осуществить поиск минимального уровня активности. Использовать выбранный генотип как основу для дальнейшей оптимизации с использованием генетического алгоритма(рекомбинация) и методики однонаправленной мутации. Фаза 2: Осуществить мутацию выбранного генотипа с получением селекционной популяции отличающихся друг от друга, но родственных генотипов для рекомбинаций. Выбрать самые селективные мутанты из популяции для рекомбинации. Фаза 3: Осуществить генерирование новых генотипов путем рекомбинации селективных мутантов. Выбрать из полученных генотипов те,которые проявляют самую высокую степень соответствия. Использовать эту субпопуляцию для последующего рекомбинантного или мутационного генерирования. Фаза 4: Выбрать лучшие продукты рекомбинации и осуществить повторные точечные мутации для увеличения селективности. Фаза 1: Эволюция-генерирование первичного кода. Для поиска оптимальных решений многих проблем может быть использован генетический алгоритм, разработанный Holland (Holland, J.H.(1975) Adaptation in Natural and Artificial Systems. U. Michigan Press. Ann Arbour). Обычно эта методика применяется для большого числа первоначально произвольных решений. При осуществлении данного метода методику значительно изменили для того, чтобы уменьшить число испытаний и итераций, требующихся для нахождения виртуальных рецепторов с высокой селективностью. Это изменение осуществили путем использования набора родственных генотипов в качестве первоначальной популяции и применения высоких скоростей мутации при каждой итерации. Для любого набора соединений-мишеней можно создать различные рецепторы с оптимальными величинами сродства. Например, рецепторы могут оптимально связываться с одними и теми же мишенями, но в разных ориентациях. Использование первоначальной популяции близкородственных генотипов увеличивает вероятность того, что процесс оп 23 тимизации сведтся к одному решению. Рекомбинация неродственных генотипов, хотя и может привести к образованию новых генотипов с повышенной степенью соответствия, скорее приведет к различным решениям. Цель первой стадии процесса оптимизации заключается в получении генотипа с минимальной степенью сродства к набору мишеней. Этот генотип затем используется для генерирования популяции родственных генотипов. Схема процесса генерирования генотипа с минимальной степенью сродства отражена в Модуле 6. Фаза 2: Эволюция-мутация первичного кода. Мутация генотипа состоит в изменении одного или нескольких признаков кода. Согласно данному методу мутации не приводят к изменению числа субъединиц, образующих полимеры рецептора, и не влияют на длину генотипа. Ясно, что эти условия являются произвольными и понятно, что в некоторых системах могут использоваться другие варианты. Мутации могут изменить характер укладки фенотипа, приводя к изменению пространственной формы рецептора и расположения или экспозиции сайтов связывания. Мутации, влияющие на конфигурацию периферических участков фенотипа, могут привести к смещению центра рецептора относительно центра мишени. Нейтральные мутации. Все виды мутации приводят к изменению структуры фенотипа, однако, не все вызывают изменение функциональности рецептора. Такие нейтральные мутации могут вызывать изменение компонентов рецептора, которые не влияют на величину сродства. В некоторых случаях эти нейтральные мутации могут объединяться с последующими мутациями, что приводит к появлению синергичного эффекта. Популяция для воспроизводства. Цель второй фазы эволюционного процесса заключается в генерировании различных, но родственных генотипов, полученных из первичного генотипа. Затем члены этой популяции используются для генерирования рекомбинантов. Эта селекционная популяция создается путем множественной мутации первичного генотипа. Осуществляют трансляцию и скрининг полученного генотипа для достижения селективности. Продукты с наибольшей селективностью сохраняются для рекомбинации. Модуль 7 отражает схему процесса множественной мутации генотипа. Фаза 3: Эволюция-рекомбинация. Цель рекомбинации состоит в создании новых генотипов с повышенной степенью соответствия. Рекомбинация облегчает сохранение фрагментов генотипа, которые существенны для соответствия фенотипа, причем в то же самое время она приводит к интродукции новых комбинаций команд. В общем рекомбинация в сочетании с результатами селекции приводит к 24 быстрой оптимизации селективности. Модуль 8 иллюстрирует схему процесса рекомбинации генотипа. Данный способ предусматривает сохранение популяции, использованной для рекомбинации, с целью испытаний на стадии 7 Модуля 8. Это приводит к тому, что генотипы с высокой селективностью не вытесняются генотипами с более низкой селективностью. Кроме того, мутации (Модуль 7) применяются для 50% рекомбинантных генотипов до испытаний (стадия 7 Модуль 8). Эта стадия приводит к вариабильности рекомбинантной популяции. Испытуемые популяции согласно данному методу могут насчитывать от 10 до 40 генотипов. Это популяция сравнительно небольшого размера. В некоторых условиях могут потребоваться популяции большего размера. Фаза 4: Эволюция-созревание. Методика прогрессивной микромутации. Заключительная стадия процесса оптимизации имитирует созревание антител в иммунной системе млекопитающего. К генотипу применяются серии единичных точечных мутаций и оценивается влияние на соответствие фенотипа. В отличие от рекомбинации этот процесс обычно приводит только к небольшим инкрементным изменениям в селективности фенотипа. Процесс созревания используется в эволюционной стратегии (1+1) Рехенберга (Rechenberg, I.(1973), Evolutionsstrategie. F. Frommann. Stuttgart). При каждом генерировании соответствие генотипа предшественника сравнивается с соответствием его продукта мутации, и для следующего генерирования сохраняется генотип с большей селективностью. В результате этот процесс является строго однонаправленным, так как менее селективные мутанты не замещают своих предшественников. Модуль 9 отражает схему примера созревания генотипа (этот пример не является ограничивающим). Во время каждой итерации процесса созревания изменяется только одна команда кода. Если предшественник и продукт его мутации обладают одной и той же селективностью,предшественник заменяется его продуктом в следующем поколении. Этот метод приводит к аккумуляции нейтральных мутаций, которые могут давать синергичный эффект в сочетании с последующими мутациями. Это условие является произвольным. Если рекомбинация или созревание не приводят к появлению улучшенной селективности после повторных итераций, может быть необходимым повторить фазу 2 для того, чтобы повысить вариабельность генома селекционной популяции. Некоторые применения данного способа Способ по данному изобретению можно использовать в нескольких областях, включая 1) скрининг для соединений с выбранными фармакологической или токсикологической активно 25 стями; и 2) создание новых химических структур с выбранными функциональными характеристиками. Ниже рассматриваются примеры этого применения. 1 А) Метод скрининга Популяция рецепторов, которые были выявлены как имеющие селективное сродство со специфической группой соединений, обладающих одинаковыми фармакологическими свойствами, может быть использована в качестве зондов для идентификации других соединений с такой же активностью, при условии, что эта активность зависит от сродства к связыванию. Например, может быть выявлена популяция рецепторов, обладающих специфическим сродством к салицилатам. Если сродство этих рецепторов к салицилатам близко коррелируется со сродством циклооксигеназы к салицилатам, рецепторы должны, по меньшей мере, частично имитировать функционально релевантные признаки сайта связывания молекулы циклооксигеназы. Эти рецепторы могут поэтому быть использованы для скрининга других соединений с возможным сродством к связыванию с циклооксигеназой. Эта методика также может быть использована для скрининга соединений, потенциально проявляющих токсикологическую или карциногенную активность. Например, могут быть выявлены рецепторы, которые имитируют сродство к специфическому связыванию рецепторов стероидных гормонов. Затем эти рецепторы могут быть использованы для оценки сродства пестицидов, растворителей, пищевых добавок и других синтетических материалов на предмет наличия возможного сродства к связыванию до испытаний in vitro или in vivo. Могут быть созданы моделированные рецепторы, проявляющие сродство к чередующимся сайтам мишени,транспортированным протеином или не связывающиеся с мишенями. 1 В) Скрининг для выявления субмаксимальной активности В некоторых случаях соединения с высоким сродством могут проявлять вредные побочные эффекты или могут быть неподходящими для введения хроническим больным. В этом случае могут потребоваться соединения с меньшим сродством к связыванию. Такие методики как комбинаторный синтез, не обеспечивает легкое генерирование или идентификацию таких соединений. По контрасту, моделированные рецепторы могут быть использованы для эффективного скрининга структур, которые проявляют сродство к связыванию любого уровня. 1 С) Измерение молекулярного подобия Селективность моделированных рецепторов может быть использована как количественная мера молекулярного подобия. 26 Пример моделированных рецепторов. В этом примере для демонстрации способности программы генерирования рецепторов с получением моделированных рецепторов, имитирующих любую произвольно выбранную активность, были выбраны величины фиктивных испытаний сродства мишеней. В этом примере все рецепторы состоят из 15 полимеров. Величины ширины, длины и глубины обозначают первоначальные координаты 15 полимеров относительно центра рецептора. Пример 1. Был получен моделированный рецептор со следующими характеристиками: число субъединиц: 240; ширина: 6; длина: 6; глубина: 25 Код:"4100033103212204103333424052312013341024 12402223233401003224251014405133243400324 62041210013131004311210113241202242130241 32311243301331003230523000433414010202230 21404144435026520341310331022051414141021 40 2134014310010231110331235210016240" Каждая мишень испытывалась 20 раз в отношении рецептора. Степень сродства оптимизированного рецептора равна 0,9358, т.е. сравнительно низкая. Субстраты-мишени, используемые для оптимизации рецептора, представляли собой бензол, фенол, бензойную кислоту и осалициловую кислоту. Предшественник аспирина о-салициловая кислота является ингибитором синтеза простагландинов при помощи циклооксигеназы. Бензойная кислота и фенол обладают гораздо более низким сродством к этому же сайту. Величины сродства мишеней и степени сродства для рецептора приведены ниже в табл. А, которая показывает, что моделированный рецептор обладает максимальным сродством к о-салициловой кислоте. Степень суммарного сродства 20,88 8,03 Таблица А Степень максимального сродства 3,38 4,99 Бензол Фенол Бензойная кислота о-Салициловая кислота Осуществлялась оценка трх испытуемых субстратов с применением моделированного рецептора. Известно, что два соединения менее активны, чем о-салициловая кислота: мсалициловая кислота и п-салициловая кислота. Третье соединение, Diflusinal, представляет собой производное фторированной салициловой кислоты, эффективность которого равна или выше эффективности салициловой кислоты. Результаты оценки приведены в табл. В. Степень суммарного сродства 45,9 63,5 117 80,33 Степень максимального сродства 12,3 27,5 71,2 34,71 Результаты, полученные с использованием моделированного рецептора, соответствуют фармакологическим данным для этих соединений: м-салициловая кислота и п-салициловая кислота характеризуются более низкими степенями сродства, чем о-салициловая кислота, adiflusinal более активен, чем о-салициловая кислота. Дальнейшая очистка моделированного рецептора и использование дополнительных,независимо оптимизированных рецепторов потребуются для повышения правильности этих предсказаний активности. Часть В. Создание новых соединений с выбранными функциональными свойствами Эволюция новых лигандов. Популяция моделированных рецепторов,обладающих селективным сродством к набору соединений-мишеней с одинаковыми функциональными свойствами, может быть использована для создания новых соединений с одинаковыми свойствами, при условии, что эти свойства тесно коррелируются со структурой или сродством к связыванию модельных соединений. Используя взаимодействие с рецепторами как критерий выбора, можно выявить новые химические структуры, оптимально соответствующие рецепторам. Поскольку эти соединения должны отвечать необходимым и достаточным требованиям к селективности рецептора, вероятно, что эти новые соединения также обладают активностью, подобной активности первоначальных молекулярных мишеней. Общая схема процесса. 1. Получить популяцию моделированных рецепторов с оптимизированной селективностью к набору охарактеризованных соединениймишеней. В некоторых случаях может быть желательным осуществить генерирование нескольких популяций с различными показателями сродства. Например, могут быть получены три популяции моделированных рецепторов,первая - имитирующая свойства выбранного сайта мишени, вторая - имитирующая сайт, требуемый для транспорта лиганда к его основной мишени и третья - популяция моделированных рецепторов, имитирующая сайт мишени, обуславливающий нежелательные побочные эффекты. Создание новой структуры лиганда в этом случае потребует одновременной оптимизации сродства к первым двум популяциям рецепторов и минимизации сродства к третьей популяции. 28 2. Определить сродство новой основной структуры к популяции(ям) моделированных рецепторов. 3. Модифицировать основную структуру и оценить сродство с использованием популяции(ий) моделированных рецепторов. Если модификация улучшает сродство, модифицированная структура сохраняется для дальнейшей модификации. В противном случае испытывается другая модификация. Ранее отвергнутые модификации могут быть вновь использованы в сочетании с другими модификациями. 4. Стадия 3 повторяется до тех пор, пока не получится соединение с подходящими величинами сродства. Примечание: Используя дискриминирующие моделированные рецепторы, можно выявить химические структуры со сродством к выбранному сайту мишени ниже максимального. 1) Генерация кода молекулярного генотипа Кодирование фенотипа лиганда (молекулярной структуры) в виде линейного генотипа,представленного нитью признаков (символов),облегчает процессы мутации, рекомбинации и наследования структурных признаков лиганда во время эволюционного процесса. Лиганды, выявленные данным методом,состоят из замещенных углеродных скелетов. Каждый код состоит из трех векторов признаков. Вектор первичного кода содержит изменяющиеся команды для генерации углеродного скелета и определяет положение каждого атома углерода в скелете. Вектор вторичного кода идентифицирует функциональные группы, присоединенные к каждому атому углерода. Вектор третичного кода определяет положение функциональной группы по отношению к углеродухозяину. Молекулярные скелеты, соединяющие атомы кроме углерода (например, в простых эфирах, амидах и гетероциклах), могут быть созданы гомологическим путем с использованием дополнительных символов в коде для обозначения атомов, замещающих атомы углерода в скелете. Углеродный скелет создается из серий точек, которые образуют узлы трехмерной тетраэдральной системы координат. Во время создания углеродного скелета расстояние между ближайшими точками равно средней длине связи между углеродными атомами алкила. Вектор первичного кода: детерминанты скелета лиганда. Вектор первичного кода состоит из символов, идентифицирующих изменяющуюся команду в отношении данного положения атома. Каждая изменяющаяся команда определяет координаты следующего атома в тетраэдральной матрице. От каждого атома могут быть взяты четыре направления (1, 2, 3, 4), соответствующие незаполненным валентностям sp3 углерода. Каждый из углеродных атомов принадлежит ральной матрицы, в которой замкнутые 6 членные кольца (циклогексаны) принимают конформацию ванны. Условие образования конформации кресла приводит к генерации матрицы, в которой циклогексильные кольца принимают конформацию кресла. Можно объединить оба условия во время генерации кода. В примерах, обсуждаемых в данном описании,используется только условие образования конформации кресла. Таблица В 1 Условия образования конформации ванны Настоящее положение = (х, у, z) Новое положение после поворота одному из четырех возможных состояний (A, B,C, D). Эти состояния соответствуют числу узлов в тетраэдральной системе координат. Соотношение между направлением поворота и новыми координатами для следующего атома в скелете приведено в следующих таблицах. Две таблицы В 1 и В 2 ниже представляют два меняющихся условия, требующихся для создания лигандов. Условие образования конформации ванны приводит к генерации тетраэд Настоящее положение А В С Каждый поворот приводит только к определению состояния нового атома: Новое состояние после поворота Настоящее положение А В С Условия образования конформации кресла Настоящее положение = (х, у, z) Новое положение после поворота Настоящее положение А В С Каждый поворот также приводит к определению положения нового атома: Новое состояние после поворота Настоящее положение А В С Используя эти соотношения, можно декодировать векторы первичного кода, состоящие из нитей символов 1, 2, 3 и 4 с созданием трхмерных образований атомов углерода. Полученной нити атомов углерода позволяют складываться или образовывать замкнутые петли с получением коротких боковых цепей и кольцевых структур. Могут быть введены специфические кольцевые структуры (например, цикло гексаны) непосредственно в виде характерных последовательностей символов, как показано ниже. Вектор вторичного кода: заместители. Вектор вторичного кода, той же длины,что и вектор первичного кода, применяется для выделения типа заместителя при атоме углерода, определяемом вектором первичного кода. Каждый заместитель идентифицируется отдель 31 ным символом. Заместители добавляют по одному к углеродному скелету. Отдельный атом углерода может иметь более одного заместителя, но только в случае, если он описывается первичным кодом более одного раза. В процессе построения лиганда в данном методе все валентности, не заполненные заместителями, описываемыми вектором вторичного кода, автоматически насыщаются атомами водорода. Для насыщения свободных валентностей атомами, отличными от водорода, можно применять другие правила. Третичный вектор: вектор связи с заместителем. Вектор третичного кода, той же длины, что и вектор первичного кода, применяется для выделения валентности, связывающей заместитель, описываемый вектором вторичного кода. Третичный код состоит из символов 1, 2, 3 и 4,каждый из которых относится к направлению поворота, определяемому для первичного кода. Заместители распределяются только в случае,если валентность ещ не заполнена либо атомом углерода, определяемым вектором первичного кода, либо другим, предварительно выделенным(распределенным) заместителем. Или же последующие заместители могут заменить предварительно распределнные заместители. 2) Создание программы (кода) Чтобы создать углеродные скелеты, конструируется первичная программа (первичный код) с помощью случайной упорядоченности(последовательности) символов, относящихся к множеству (набору) "1", "2", "3", "4". Создание гетероциклических структур, простых эфиров, амидов имидов и карбоксильных соединений выполняется заменой скелетного атома углерода на другой атом, определяемый вторичным кодом (вторичной программой). Вторичный код создают, исходя из случайной упорядоченности символов, определяющих типы заместителей. Частота символов может быть случайной или ранее фиксированной до генерации команд. Третичный код состоит из символов из набора (множества) "1", "2", "3", "4". Циклические структуры можно конструировать сознательно (в противоположность случайной генерации), добавляя (последовательности) упорядоченности конкретных символов к первичному коду. Например, "431423" кодирует циклогексильные кольца. Сумма из 24 строк кодирует все возможные положения циклогексильных групп в тетраэдральной матрице. Векторы вторичного и третичного кода для первичных кодов цикла создают так, как описано выше. Модуль 10 представляет блок-схему примерного создания программы для генерации углеродных скелетов, включающих циклы. Относительные положения точек входа и выхода из части углеродного скелета, содержащей цикл, определяется длиной упорядоченно 001095 32 стей символов, применяемых для создания цикла. Конкретно, если упорядоченности (последовательности) содержат шесть символов, например, 432413, то точка входа и выхода представляет собой тот же самый член цикла. Если последовательность является частично повторной и добавляется к первоначальным шести символам, точка входа и точка выхода не будут являться тем же самым членом цикла. Например,4314134 и 43141343141 образуют циклы, у которых точки выхода у членов кольца прилегают к точкам входа. В данном случае кольца присоединяют к скелету, добавляя последовательности (упорядоченности) из 6 или более символов к коду. Для цикла, описываемого 431413, возможными используемыми последовательностями (упорядоченностями) являются: 431413 4314134 43141343 431413431 4314134314 43141343141 431413431413 431413431413 Предлагаемые правила создания нового генотипа лигандов можно применять для кодирования других химических структур в линейном формате как для хранения (в памяти), так и для введения в процесс эволюции лигандов. Например, известный фармакофор можно кодировать в линейном формате и применять в качестве исходной точки для выявления новых лигандов с подобными или улучшенными функциональными свойствами. Подобным образом,наборы фармакофоров, взаимодействующих с общим сайтом мишени, можно кодировать в линейном формате и использовать для рекомбинации. 3) Трансляция кода и конструирование (построение) лиганда Векторы кода преобразуют в трхмерные изображения лигандов в процессе трансляции,состоящем из трх дискретных стадий. На первой стадии (конструируют) строят углеродный скелет, используя первичный (основной) код. На второй стадии углеродный скелет дополняют заместителями, применяя команды векторов вторичного и третичного кода. Команды векторов вторичного и третичного кода могут также определять (устанавливать) замещение атомов углерода в скелете на другие атомы. Команды вторичного и третичного кодов могут также менять число и направление валентностей,имеющихся у атома углерода или другого атома, составляющего часть основного (первичного) скелета. Например, добавление карбонильного кислорода насыщает (заполняет) две свободные валентности. На третьей стадии все валентности, не заполненные заместителями на(если не указано иначе). Первичное декодирование: построение скелета лиганда. Первичное декодирование использует команды поворота от вектора первичного кода для установления положения каждого атома углерода. Предполагается, что первый атом расположен в начале системы координат. Предполагается, что первый атом занимает в матрице состояние А. Декодирование происходит последовательно. Результат процесса первичного декодирования представляет собой 3n матрицу, содержащую координаты х, у и z каждого из n скелетных атомов углерода. Поскольку петли и повороты разрешены, одно и то же положение в пространстве может занимать не один углеродный атом. В подобных случаях допускают, что только один атом углерода занимает данное положение. В результате число атомов углерода,образующих окончательный скелет, может быть меньше, чем число символов в векторе первичного кода. Когда первичный код считан, создается перечень (список) из вторичного кода, который определяет заместители у каждого атома углерода. В то же самое время создается параллельный список с использованием третичного кода для определения валентности, насыщаемой каждым заместителем. Вторичное декодирование: введение (добавление) заместителей. Заместители добавляют (вводят) последовательно к каждому атому углерода на основе списка, образованного из вторичного кода при первичном декодировании. Для определения положения валентности заместителя относительно основного (скелетного) углерода (углерода-"хозяина") используют соответствующее значение из третичного кода. Если положение уже занято либо соседним атомом углерода,либо ранее описанным заместителем, замещение не выполняется. Или же может создаваться процесс декодирования, в котором осуществляется замещение в следующее незанятое положение, или происходит замена ранее описанного заместителя. Расстояние между заместителем и атомом углерода вычисляют исходя из справочных таблиц длин связей. Данные положения(позиции) и длины связей используют для расчета координат заместителя. В случае многокомпонентных заместителей, например, гидроксильной, нитро- и аминогрупп, для каждого атома в заместителе рассчитывают координаты относительно углерода-"хозяина". После того, как все заместители, описанные с помощью вектора вторичного кода, введены в скелет, все незаполненные позиции, остающиеся в скелете, насыщают атомами водорода. Для расчета координат каждого водород 001095 34 ного атома используют длину связи водородsp3-углеродный атом. Отдельные атомы углерода могут иметь более одного заместителя, отличного от водорода. Это может происходить, если одно и то же положение описывается вектором первичного кода более одного раза. Данный вариант осуществления изобретения не включает множественные заместители, непосредственно использующие вторичный код, хотя это можно легко осуществить. Заместители разрешены только в положениях, не занятых атомами углерода, образующими скелет лиганда. Сводный (кумулятивный) список содержит все занятые сайты (положения) в тетраэдральной матрице. В процессе вторичного декодирования транслируется список типов, радиусов и положения всех атомов, содержащихся в лиганде. Этот список является основой для последующей генерации мишеней. На этой стадии процесса не оценивается осуществимость структуры, создаваемой на основе упорядоченности (последовательности) кода. В некоторых случаях координаты атомов можно вводить в программы минимизации энергии с целью создания более правдоподобных структур. Однако в данном случае не делается никаких допущений относительно конфигурации лиганда во время связывания. Кроме того, данный вариант осуществления способа сохраняет уникальность структуры специфической конфигурации той же молекулы. Например, данная разработка различает три вращательных изомера бутана и рассматривает каждый изомер как отдельную молекулу. Векторы кодов составляют генотип соответствующего лиганда и могут подвергаться(изменению) мутации и рекомбинации, изменяя в результате структуру лиганда. Сама по себе структура лиганда представляет собой фенотип,используемый для оценки сродства к связыванию с выбранной популяцией виртуальных рецепторов. 4) Презентация мишеней Химические структуры мишеней лигандов первоначально строят на основе случайно генерированных (созданных) кодов. После декодирования из справочных таблиц получают значения координат, радиусов, дипольных моментов и поляризуемостей каждого атома в мишенилиганде и используют для оценки сродства к связыванию между лигандом и выбранной популяции виртуальных рецепторов. Сродство мишени к каждому из виртуальных рецепторов проверяют для многих ориентаций мишени относительно поверхностей рецептора. Не делается никаких допущений насчет относительной ориентации лиганда и моделированного рецептора. Прежде, чем оценивать сродство к связыванию, мишень и рецептор должны войти в контакт. Способ презентации 35 мишени и расчета сродства между химическими структурами и моделированными рецепторами практически такой же, как обсуждавшийся выше в Модуле 4 между молекулами известных мишеней и моделированными рецепторами. 5) Оценка сродства к связыванию и соответствия Сродство к связыванию лиганда-мишени с каждым из моделированных рецепторов, применяемое для (оценки) определения соответствия, рассчитывают, применяя тот же способ расчета эффективного сродства, который описан для генерации моделированных рецепторов с применением молекул мишеней. Как отмечено ранее, можно вводить в процесс проверки соответствия расчеты сродства с применением других критериев, но эффективность и точность вычислений в данном случае зависит частично от использования того же самого расчета эффективного сродства к генерации виртуальных рецепторов и генераций химических структур с применением популяций моделированных рецепторов. 6) Изменение (эволюция) лиганда Проверка степени соответствия. Степень соответствия между выбранной популяцией моделированных рецепторов и новым лигандом или химической структурой оценивают, сравнивая значения активности или сродства мишени к лиганду с таковыми, полученными для моделированных комплексов рецептор-лиганд. Максимальные значения сродства оптимального селективного виртуального рецептора должны чтко коррелировать с величинами сродства мишени. Последующие операции процесса эволюции (изменения) применяют для повышения степени этой корреляции (соответствия). Значения сродства к связыванию мишени могут (находиться на любом уровне) быть различными. Не требуется, чтобы у лиганда было одинаковое сродство к связыванию со всеми виртуальными рецепторами в процессе отбора. В данном случае для расчета величины сродства мишени к связыванию используют величины максимального сродства к связыванию оптимизированных виртуальных рецепторов с известными субстратами. Например, величины сродства мишеней могут составлять до 90% от сродства к связыванию каждого члена популяции виртуальных рецепторов с конкретным субстратом. Или же величина сродства мишени к связыванию может находиться около нуля, если взаимодействие между лигандом и виртуальным рецептором должно быть сведено к минимуму. Путем сочетания моделированных рецепторов, оптимизированных для различных наборов субстратов, и ассоциацией выбранных значений сродства мишени с каждым рецептором,можно выбрать новые лиганды с конкретными параметрами сродства к связыванию. Соответствие лиганда является мерой того, насколько 36 совпадают значения вычисленного для лиганда сродства к связыванию и сродства мишени. Процесс оптимизации делает соответствие лиганда максимальным. Оптимальная ориентация лигандов с целью достижения максимального сродства к связыванию до тестирования неизвестна. Чтобы получить репрезентативный порядок (размер) интервала сродства рецептор-лиганд, каждый новый лиганд нужно проверять неоднократно при различных случайных ориентациях относительно плоскости (поверхности) рецептора. Каждый тест использует Модуль 4, обсуждаемый в части А, для оценки сродства. В целом надежность полученных величин максимального сродства зависит от размера выборки, так как увеличивается вероятность того, что выборка содержит действительно максимальное значение. Чтобы избежать необходимости в большой выборке для генерации оптимизированных новых лигандов или химических структур, в данном аспекте изобретения используют две методики: 1. Применение величины, сочетающей среднее (или суммарное) сродство и максимальное сродство, с целью выбора лигандов с оптимизированными профилями сродства. 2. Инкрементное увеличение числа ориентаций, проверяемых последовательными итерациями процесса оптимизации. (Оптимизацию начинают с малого набора ориентаций мишени; когда генерируются более пригодные лиганды,тестируют больше ориентаций). В данном случае вычисляют сумму значений сродства, полученных для всех проверяемых ориентаций каждого лиганда. Эта величина суммарного сродства есть мера среднего сродства между рецептором и лигандом. В то же время определяется также величина максимального сродства. Как суммарное, так и максимальное сродство применяют для проверки степени соответствия виртуального рецептора и нового лиганда. Соответствие каждого нового лиганда оценивают, исходя из разницы между расчетными значениями суммарного и максимального сродства и величинами этих параметров для мишени. В данном случае величина: рассчитывается как степень соответствия для каждой новой пары лиганд-моделированный рецептор. Соответствие является максимальным, когда степень соответствия равна нулю. Величины максимального сродства и суммарного сродства мишеней получены с помощью обратных функций, найденных в процессе эволюции оптимизируемых виртуальных рецепторов,как описано в предыдущих разделах. Значения для мишеней получены следующим образом: 37 макс. сродство мишени = fмаксимальное сродство наиболее активного (сильного) субстрата,применяемого для генерации виртуального рецептора суммарное сродство мишени = fи суммарное сродство наиболее сильного субстрата, применяемого для генерации виртуального рецептора,где f = коэффициент масштабирования. Когда для оценки соответствия лиганда используют более одного моделированного рецептора, значения степени соответствия каждой пары лиганд-моделированный рецептор суммируются. В этом случае степень соответствия максимизируется, когда сумма степеней соответствия равна нулю. В некоторых случаях желательно использовать только степень максимального сродства при тестировании нового лиганда относительно панели различных моделированных рецепторов. В этом случае соответствие будет выражаться как:Ftot= В этом случае соответствие также максимизируется, когда сумма степеней соответствия равна нулю. Для измерения общей степени соответствия лиганда, проверяемого относительно ряда моделированных рецепторов, можно применять другие способы, например, геометрический способ. Использование значений как максимального сродства, так и суммарного, полученных для каждого моделированного рецептора, гарантирует, что селективность виртуальных рецепторов включается в оценку соответствия лиганда. Таким образом, соответствие лиганда отражает не только сродство лиганда, но также то, что он удовлетворяет пространственным требованиям виртуального рецептора, которые лежат в основе селективности. 6 а) Цель процесса оптимизации Создание нового лиганда с избранным сродством к мишени для набора моделированных рецепторов. Требуется высокоэффективный механизм для решения (этой задачи), так как общее число возможных генотипов, отвечающих 25 командам, составляет 25625. Процесс.(1) Фаза 1. Создайте набор случайных генотипов, кодирующих лиганды, и подвергните скринингу относительно набора моделированных рецепторов с целью выбора лигандов, превосходящих порог степени соответствия.(2) Фаза 2. Выбранный генотип используют как основу для дальнейшей оптимизации,применяя методику генетического алгоритма(рекомбинации) и однонаправленной мутации. Подвергните мутации выбранный генотип с це 001095 38 лью генерации популяции для воспроизводства отдельных, но родственных генотипов для рекомбинации.(3) Выберите наиболее селективные мутанты из популяции для рекомбинации.(4) Фаза 3. Создайте новые генотипы путем рекомбинации селективных мутантов. Выберите из полученных генотипов таковые, соответствующие наиболее высокой степени сродства. Примените эту субпопуляцию для последующей генерации рекомбинаций (повторить фазу 3) или мутаций (повторить фазу 4).(5) Фаза 4. Возьмите лучшие продукты рекомбинации и примените к ним повторные точечные мутации с целью повышения селективности.(6) Процесс оптимизации завершен, когда генерированы (созданы) лиганды с заданным соответствием. Фаза 1: Эволюция-генерация первичного кода Задачей первой стадии процесса оптимизации является создание генотипа и фенотипа соответствующего лиганда с минимальной степенью соответствия. Этот генотип затем используют для создания популяции родственных генотипов. Генетический алгоритм, открытый Holland(Холландом), можно применять для поиска оптимальных решений множества задач. Обычно эта методика применяется с использованием больших, первоначально случайных наборов решений. В данном аспекте изобретения методика значительно модифицирована с целью уменьшения числа тестов и итераций, требуемых для нахождения лигандов с высоким селективным сродством. Это было выполнено с использованием набора генотипов с близким родством в качестве исходной популяции и применения высоких скоростей мутации при каждой итерации. Для каждого набора соединениймишеней можно получить (найти) отдельные лиганды с оптимальными характеристиками сродства. Например, рецепторы могут оптимально связываться с теми же самыми мишенями, но с различной ориентацией. Применение исходной популяции близко родственных генотипов повышает вероятность того, что процесс оптимизации сведется к единственному решению. Рекомбинация неродственных генотипов,хотя она и может создать новые генотипы с повышенной совместимостью, но более вероятно то, что она приведет к дивергенции. Фаза 2: Мутация лиганда Задачей второй фазы процесса эволюции является генерация популяции отдельных, но родственных генотипов, образованных из первичного генотипа. Члены этой популяции затем используются для получения рекомбинаций. Эта популяция для воспроизводства (улучшения) создается с помощью множественной мутации первичного генотипа. Образующиеся в результате генотипы транслируются и подвер 39 гаются скринингу на предмет селективности. Продукты с наибольшей селективностью сохраняют для рекомбинации. Лиганды подвергаются мутации путем изменения признаков (символов) генотипа (векторов кода), кодирующих их структуры. Эти мутации изменяют размер лиганда, а также расположение и тип имеющейся в лиганде функциональной группы. Мутации в данном случае могут менять число атомов углерода, составляющих скелет лиганда. Модуль 11 представляет собой блок-схему примерного процесса множественной точечной мутации. Мутации могут менять характер упорядочивания фенотипа лиганда, изменяя в результате размер и местоположение или вид функциональной группы. Мутации, которые влияют на конфигурацию периферических участков фенотипа лиганда, могут приводить к сдвигу позиции относительно рецепторного центра. Нейтральные мутации. Все мутации изменяют структуру фенотипа, однако, не все мутации приводят к изменению функциональности лиганда. Такие нейтральные мутации могут менять компоненты(составляющие) лиганда, которые не влияют на сродство. В некоторых случаях такие нейтральные мутации могут сочетаться с последующими мутациями, оказывая синергичное воздействие. Мутации последовательности. Мутации последовательности не меняют непосредственно символы кода. Вместо этого изменяется последовательность символов в коде. Мутации последовательности могут менять размер лиганда, (структурную) конфигурацию и наличие и местоположение функциональных групп. По данному аспекту изобретения применяют четыре типа мутации последовательности:a) ДЕЛЕЦИЯ: из кода удаляется последовательность символов.b) ИНВЕРСИЯ: порядок символов, составляющих последовательность внутри кода, меняется на обратный.d) ИНСЕРЦИЯ: в код встраивается последовательность символов. АВСDЕАABCDBCEA Мутации по данному изобретению применяются в комбинации. Модуль 12 представляет блок-схему примерной мутации последовательности. Фаза 3: Генерация рекомбинантного кода Во время рекомбинации, случайно выбранной, происходит обмен комплементарными секциями между выбранными генотипами. Задачей рекомбинации является генерация новых 40 генотипов с повышенным соответствием. Рекомбинация облегчает сохранение фрагментов генотипа, существенных для соответствия фенотипов, и в то же время вводит новые комбинации команд. В целом, рекомбинация, соединнная с отбором, дает быструю оптимизацию селективности. Модуль 13 представляет блоксхему примерной процедуры рекомбинации. В данном случае сохраняется популяция,используемая для рекомбинации, с целью тестирования. Этим гарантируется, что генотипы с высокой селективностью не замещаются на генотипы с более низким соответствием. По данному аспекту изобретения перед тестированием множественным мутациям подвергается до 50% рекомбинантных генотипов. Этот процесс повышает вариабельность внутри рекомбинантной популяции. Тестируемые популяции, применяемые по данному изобретению, имеют размеры в интервале от 10 до 40 генотипов. Это относительно малый размер популяции. В некоторых случаях (при некоторых условиях) могут потребоваться большие популяции. Фаза 4: Созревание лиганда Методика прогрессивной микромутации. На конечной стадии процесса оптимизации имитируется созревание антител в иммунной системе млекопитающих. Проводят ряд одноточечных мутаций в генотипе и оценивают действие на соответствие фенотипов. В отличие от рекомбинации этот процесс обычно приводит только к малым изменениям, повышающим селективность фенотипа. Процесс созревания использует (1+1) эволюционный способ Рехенберга (Rechenberg). С каждым поколением (генерацией) соответствие исходного генотипа сравнивают с таковым продукта мутации и генотип с более высокой селективностью сохраняют для последующей генерации. В результате этот процесс является строго однонаправленным, так как менее селективные мутанты не замещают предшественника. При каждой итерации процесса созревания по данному изобретению меняется (только) единственная команда в коде. Если предшественник и продукт его мутации обладают одинаковой селективностью,предшественник замещается продуктом в следующей генерации. Этот способ приводит к накоплению нейтральных мутаций, которые могут оказывать действие синергичное с последующими мутациями. Это условие является необязательным, случайным. Модуль 14 представляет блок-схему примерного процесса созревания. Если рекомбинация или созревание не дают улучшенной селективности после повторных итераций, возможно, станет необходимым повторить множественные мутации (фаза 2), чтобы повысить вариабельность генома популяции для воспроизводства (размножения). 42 1. Неподвижную женскую особь, находящуюся на внутреннем сите наветренной стенки,отбирают для тестирования. 2. Обработанный конец бумажного фильтра помещают на внешней стороне экрана-сита и располагают напротив среднегрудной лапки комара. Во всех случаях начинают подход с нижнего расположения комара. 3. Кончик (фильтра) сохраняют в (данном) положении максимум в течение 3 с и отмечают реакцию комара. Затем повторяют процедуру для нового индивидуума. Комаров тестируют только один раз ежедневно на каждое соединение. Кончики(фильтров) используют для пяти тестов каждый(суммарная продолжительность использования 30 с), затем заменяют. Соединения проверяют в случайном порядке, и каждое соединение проверяют дважды в разные дни. Два набора контрольных (опытов) проводят с применением необработанных (сухих) концов фильтровальной бумаги и концов, смоченных дистиллированной водой, таким же образом, что и с обработанными концами. Тесты этих контрольных образцов регулярно распределяются среди тестов репеллентов. Реакция на контрольные соединения не изменяется в течение эксперимента(р 0,25). Отмечено (записано) четыре поведенческих (бихевиористских) реакции: 1. Нет реакции: комар остается неподвижным. 2. Взлт: комар улетает с места расположения. 3. Подъем ипсилатеральной ноги (лапки): комар поднимает среднегрудую лапку на той же стороне, где находится источник раздражителя. 4. Подъем контралатеральной лапки: комар поднимает среднегрудую лапку на стороне, противоположной той, где находится источник раздражителя. За подъемом ипсилатеральной лапки часто следует взлет, в этом случае регистрируют оба вида поведения. При тестировании и на всех фазах приготовления соединения используются полиэтиленовые перчатки. Примеры генерации лиганда Общее представление Комаров(табл. 1). Этот вид не отпугивает в значительной степени циклогексан или гексан (табл. 1). В следующем тесте новой генерации лигандов используется способ для создания, аb initio (с начала), соединений, которые имели бы подобную бензальдегиду активность в качестве репеллентов. На первой стадии генерации лигандов были созданы моделированные рецепторы с высоким сродством к бензальдегиду и низким сродством к бензолу. На второй стадии выявляются лиганды со сродством к связыванию с моделированными рецепторами, подобным таковому (родству) бензальдегида. Реакции (ответ) комаров Комары являются выращенными в лаборатории, в возрасте 7-14 дней и не кормленными. Эксперименты проводят в течение шести дней при 20 С и ультрафиолетовом облучении. Тесты осуществляют между 12.00 и 17.00 восточного поясного времени. Испытуемые популяции в четырех наборах для испытаний содержат 200,175, 105 и 95 женских особей. Комарам дают питьевую воду. Тесты проводят в пеналах (боксах) из прозрачного плексигласа размером 353535 см с двумя противоположными сторонами, представляющими собой экраны-сита. Скрининг(просеивание) проходит через два слоя: внутренний слой из пластика с большими отверстиями и внешний нейлоновый слой с частыми(мелкими) отверстиями. Пенал помещают в атмосферу паров так, чтобы воздух поступал через одну из экранированных сторон и выходил через противоположную сторону. Ток воздуха 0,5 см/с. Комары помещаются на стенках пенала(бокса) головками вверх. Для подачи стимулирующего вещества используют треугольные (441 мм) бумажные фильтры (Whatman, Ватман,1). Концы погружают в испытуемый раствор на глубину 0,5 см и используют немедленно. Реакцию (ответ) на испытуемые растворы определяют следующим образом: Таблица Е 1 Соединение Бензальдегид Бензол Толуол Циклогексан Гексан Контрольный Реакция комаров на выбранные летучие соединения Температура киN% Реакция% Реакция пения, С взлет подъем лапки 178 130 90 10 80 72 72 12.5 110 166 67 27 81 80 6 0 69 100 4 0 450 Относительная отталкивающая способность 178 68 94 4.9 2.8 Относительная отталкивающая способность = [(% Реакция-взлет + % Реакция лапки) Ч температура кипения /100 Генерация модулированного рецептора и лиганда. Моделированные рецепторы генерируют(получают), используя те же критерии отбора. Каждый рецептор используют независимо для получения набора лигандов. Подбор молекул 1 Фаза 1: генерация рецептора. Выявляется рецептор с селективным сродством к бензальдегиду. Испытуемыми мишенями являются бензол и бензальдегид. Для расчета величин сродства используют пятнадцать ориентаций каждой мишени. Результаты процесса эволюции таковы: Мишень Бензол БензальдегидC8H17C12OH Суммарное сродство 75,87 74,03 Максимальное сродство 13,02 12,82 Выделенные лиганды от 1.1 до 1.4 показаны на фиг. 4b. По меньшей мере, одна ориентация каждого лиганда сходна по структуре с бензальдегидом. Подбор молекул 2 Фаза 1: генерация рецептора. Рецептор 2567 выявляют по избирательному сродству к бензальдегиду. В качестве испытуемых мишеней используют бензол и бензальдегид. Для расчета величин сродства берут пятнадцать ориентаций каждой мишени. Результаты процесса эволюции таковы: Мишень Бензол Бензальдегид Значения сродства к лиганду следующие: Бензальдегид Лиганд 2.1 С 8 Н 13 Сl(=O) Суммарное сродство Максимальное сродство Степень соответствия 44 Степень сродства к рецептору равна 0,992. Код для оптимизированного 2567 рецептора бензальдегида: 231014406145 412061421302 022224-31514 402131114311 Фаза 2: генерация лиганда Оптимизированный моделированный рецептор используют в качестве матрицы для эволюции новых лигандов. С помощью случайной мутации и селекции подбирают четыре различных лиганда. Лиганды отбирают по сходству с бензальдегидом. Фаза 2: генерация лиганда. В качестве матрицы для эволюции новых лигандов используют оптимизированный моделированный рецептор. Случайной мутацией и селекцией подбирают четыре различных лиганда. Лиганды отбирают по сходству с бензальдегидом. Выделенные лиганды от 2.1 до 2.4 изображены на фиг. 4 с. По меньшей мере, одна ориентация каждого лиганда по структуре сходна с бензальдегидом. Соединения 2.1 и 2.4 являются производными замещнного циклогексанона. Лиганд 2.2 представляет собой 5-хлорнона-2,7-дион и лиганд 2.3 является 2-цианогексан-5-оном. Лиганд 1.4 содержит фрагмент, соответствующий по строению метилциклогексилкетону. Эксперименты по проверке отталкивающей способности циклогексанона, ментона, метилциклогексилкетона и октан-2-она (см. фиг. 4 а) подтверждают, 46 что эти лиганды также являются репеллентами по отношению к комарам (табл. Е 2). Таблица Е 2 Реакция комаров на выбранные летучие соединения Соединение Температура% Реакция% Реакция Относительная отталкикипения, С взлет подъем лапки вающая способность Бензальдегид 178 130 90 10 178 2-Октанон 173 80 82 12,5 162 2-Ацетилциклогексанон 225 100 54 24 175 Циклогексанон 156 134 99 1 154 Ментон 207 110 72 11 172 Контрольный (слепой) 450 5 0 Относительная отталкивающая способность = [(% взлет + % реакции лапки)температура кипения /100 Предлагаемый в данном описании способ построения новых химических структур, проявляющих выбранные заранее функциональные характеристики или свойства, был описан только на примере. Например, способ можно легко применить на практике, используя другие известные или приемлемые значения поляризуемостей, дипольных моментов, ковалентных радиусов и тому подобное. Кроме того, блоксхемы, дающие стадии расчета процесса в модулях, предназначены только для иллюстрации. Например, расчет сродства можно провести с применением доступных вычислительных пакетов, используя меньше аппроксимаций (приближений), чем сделано в данном описании. Способ образования новых химических структур опирается на первую генерацию одного или более моделированных рецепторов, проявляющих заранее выбранное сродство к известным соединениям-мишеням со сходными функциональными характеристиками и на использовании этих рецепторов для создания новых структур, обладающих этими характеристиками в заданной степени. Рецепторы сами по себе можно использовать для других применений,помимо образования (генерации) новых химических структур, например, как средство для скрининга фармацевтических или токсокологических свойств известных соединений. Таким образом, специалистам в данной области понятно, что многие изменения способа, данного в настоящем описании, могут быть сделаны не за рамками изобретения. Таблица 1 Переходные состояния и коэффициенты добавлений Коэффициенты присоединения Новое состояние для поворота = Правый Вверх Левый Вниз Взято из: N.S. Issacs, 1987. Physical Organic Chemistry. Longman Scientific and Technical, New York. 828 pp. Таблица 3 Радиус ковалентных связей (пМ) Порядок связи Первый Первый Второй Третий Ароматический Первый Первый Взято из: N.S. Issacs (1987). Таблица 4 Значения эффективных дипольных моментов, применяемых для отнесения заряда Связь Атом Величина дипольного момента (Дебай) С-Н Н+0,35 или +0,084 С нет отнесения заряда АrС-Н Н-0,366 или нет отнесения заряда-0,6 или нет отнесения заряда С=O-2,7 С нет отнесения заряда или +1,35 С-О-СS в тиофене или диметилсульфиде +1,5 (может быть отрицательно заряжен в контексте)N в пиридине или СН 3-N=СН 2 +1,5 или +1,3-2,0 Предпочтительно в большинстве случаев Каждый атом мишени полностью описывается набором из восьми значений хi, yi, zi, ri, bri, cri, di,i, где хi, у и z координаты положений относительно геометрического центра молекулы, ri означает радиус Ван дер Ваальса, bri означает связь или ковалентный радиус, сri означает радиус перекрывания(столкновения) (=ri+0,5), i означает поляризуемость и di означает величину эффективного дипольного момента. Таблица 5 Выбранные значения относительных эффективных поляризуемостей атомов отобранных мишеней Атом Контекст Относительная поляризуемость (i) Н С-Н 1,0 Н Вычислено исходя из молекулярных поляризуемостей.Значения могут быть определены на основе соответствующих молекулярных данных. Модуль 1: Генерация программного кода для расчета моделированных рецепторов. Операция 1. Введите параметры объектного кода (генерации команд): i) длина (число символов) кода; и ii) частота команд. Операция 2. Инициализируйте пустую строку для записи кода в памяти. Операция 3. Генерируйте случайное число. Операция 4. Исходя из случайного числа и частоты комaнд, выберите символ '0', '1' '6' для конкатенации со строкой кода. Повторяйте операцию 4 до тех пор, пока длина строки не сравняется с предварительно заданной длиной кода. Операция 5. Выведите код. Модуль 2: Трансляция кода для расчета моделированных рецепторов. Операция 1. Введите начальные координаты полимеров, входящих в состав (составляющих) рецептора. Операция 2. Введите код полимера. Операция 3. Прочитайте первый символ кода. Операция 4. Если символ является командой поворота, используйте алгоритм трансляции для определения координат субъединицы, иначе перейдите к операции 7. Операция 5. Введите в память координаты субъединицы. Присвойте субъединице величину заряда 0. Операция 6. Если символ не является последним символом кода, повторите операцию 3,иначе перейдите к следующей операции. Операция 7. Если символ представляет собой команду заряда, примените алгоритм трансляции для определения координат субъединицы,не предполагающих поворота. Операция 8. Сохраните в памяти координаты субъединицы. Присвойте субъединице величину заряда +1 или 1 в зависимости от символа. Операция 9. Если символ не является последним символом кода, повторите операцию 3,иначе перейдите к следующей. Операция 10. Повторите операции с 2 до 9 для каждого из полимеров, входящих в состав рецептора. Операция 11. Выведите координаты и значения зарядов субъединицы. Модуль 3: Презентация мишени. Операция 1. Введите координаты и радиусы атомов мишени (xti, yti, zti, радиусi)(i=число атомов в мишени) Введите координаты рецептора (хrj, уrj, zrj,зарядj)(j=числo субъединиц в рецепторе) Операция 2. Задайте случайные значения углов (, ) и сдвига (kx, ky). Операция 3. Вращайте и сдвигайте координаты атомов на случайную величину. Операция 3 а. Переведите координаты мишени в полярную форму (xti, yti, zti, радиусi)(i, i, i, радиусi) Операция 3b. Добавьте произвольные изменения к углам (i, фi, i, радиусi)(i+i,фi+фi, i, радиусi) Операция 3 с. Переведите в систему декартовых (прямоугольных) координат (i+i,фi+фi, i, радиусi)(хi, уi, zi, радиусi) Операция 3d. Добавьте случайный сдвиг(xni, yni, zni, радиусi)(xi+kx, yi+ky, zi, радиусi) Операция 4. Поместите центр мишени в начало координат (0,0,0). Операция 4 а. Найдите максимальное и минимальное значения для xni, уni, zni. Операция 4b. Найдите геометрический центр рецептора хnцентр=(хnмаксимум-xnминимум)/2,ynцентр=(ynмаксимум-ynминимум)/2, znцентр=(znмаксимумznминимум)/2. Операция 4 с. Вычислите координаты относительно центра (хnсj, уnсj, zncj)=(хni-xnцентр,yni-ynцентр, zni-znмаксимум). Операция 5. Используйте радиусы атомов и преобразованные координаты (хnсi, уnсi, znсi,радиусi) для построения поверхности столкновения мишени g(xg,yg)=zg Операция 5 а. Создайте координатную сетку с интервалом, равным диаметру субъединицы рецептора (=1). Координаты сетки: Задайте нулевые начальные значенияg(xg,yg) во всех точках координатной сетки. Операция 5b. Для каждого атома (i) задайте значение g(xg,yg) (вес) каждой точки координатной сетки (xg,yg) в соответствии со следующим правилом: Для i = от 1 до числа атомов в мишени Если (хnсi-xр)2 + (уnci-уp)2 радиyсi2, тогдаg(xg,yg) = минимум (g(xg,yg), 0) Затем i Операция 6. Поместите центр рецептора в начало координат (0,0). Операция 6 а. Найдите максимальное и минимальное значения xrj, yrj и zrj. Операция 6b. Найдите геометрический центр рецептора хrцентр=(хrмаксимум-xrминимум)/2,yrцентр=(yrмаксимум-yrминимум)/2, 53zrцентр=(zrмаксимум-zrминимум)/2 Операция 6 с. Вычислите координаты рецептора относительно центра (хсj, ycj, zcj)=(xrixцентр, yri-yцентр, zri-zмаксимум). Операция 7. Постройте поверхность столкновения рецептора s(xs,ys)=zs, используя координаты рецептора относительно центра в соответствии со следующим правилом: Задайте все начальные значения s(xcs,ycs) к 0 Для j = от 1 до числа субъединиц в рецепторе, если zcjs(xcj,ycj), тогда s(xcj,ycj)=zcj Переходите к следующему j. Операция 8. Найдите минимальное расстояние между поверхностью столкновения рецептора и поверхностью столкновения мишени. Рассчитайте разностную матрицу d(xg,уg) следующим образом для всехznмаксимум) + (s(xg,уg) + zrминимум - zrмаксимум) Для всех xg,уg найдите минимальное значение d(xg,уg) = dmin dmin означает минимальное расстояние. Операция 9. Трансформируйте координаты конфигурации столкновения (коллизии) мишени и рецептора. Для рецептора:znмаксимум-dmin). Операция 10. Примените (хмишеньi, умишеньi, zмишеньi) и (хрецепторj, урецепторj,zрецепторj) для расчетов сродства. Повторите операции 2-9 для расчета конфигурации каждой испытуемой мишени. Модуль 4: Расчт сродства. Операция 1. Введите координаты столкновения мишени и рецептора (хмишеньi,умишеньi, zмишеньi) и (хрецепторj, урецепторj,zрецепторj), где i = число атомов в мишени, j = число субъединиц в рецепторе. Операция 2. Введите значения дипольных моментов для мишени (dip(i дип(i) Введите значения зарядов для рецептора заряд (j) Операция 3. Введите пороговое значение для расчета проксимальности THRESHOLD(порог) Операция 4. Рассчитайте значение сродства диполя Операция 4 а. Для каждой заряженной субъединицы 54 Операция 4b. Вычислите сумму e(i,j) для всех комбинаций i и j с зарядом (j)0.(ДИПОЛЬ) DIPOLE = e(i,j) Операция 5. Рассчитайте значение проксимальности (эту операцию можно заменить расчтом на основе поляризуемости) Операция 5 а. Для каждого атома мишени с+ (умишеньi - урецепторj)2 + (zмишеньi zрецепторj)2)0,5 Если l(i,j)ПОРОГ, тогда prox(i,j) = 1 Операция 5b. Вычислите сумму prox(i,j) для всех комбинаций i и j с дип(i)0,75prox(i,j) Операция 6. Рассчитайте значение сродства для комбинации мишень-субстрат = СРОДСТВО (AFFINITY) СРОДСТВО = (ПРОКСИМАЛЬНОСТЬ/j)(ПРОКСИМАЛЬНОСТЬ/10000 + ДИПОЛЬ),AFFINIT = (PROXIMITY/j) (PROXIMITY/ 10000) + DIPOLE) Модуль 5: Расчт степени соответствия. Операция 1. Введите значения эффективности или сродства известной мишени (уk), k = число испытуемых мишеней Операция 2. Введите координаты коллизии(столкновения) мишеней и рецептора (хмишеньi, умишеньi, zмишеньi) и (хрецепторj, урецепторj, zрецепторj), где ik = число атомов в мишени k, j = число субъединиц в рецепторе Операция 3. Введите число подлежащих тестированию ориентаций мишени (=m). Операция 4. Используйте Модуль 5 для получения значений сродства для каждой мишени и ориентации мишени (=AFFINITYk,m). Операция 5. Определите значения максимального сродства (МСk) (МАk) и суммарного сродства (ССk) (SAk) для каждой мишени. Операция 6. Вычислите коэффициенты корреляции rМС 2 (rМA2) для максимального сродства (МСk; МАk) относительно величин эффективности известной мишени или величины характеристик сродства (уk) и rSA2 для суммарного сродства (ССk; SAk) относительно величин эффективности и сродства известной мишени (уk). Операция 7. Рассчитайте коэффициент соответствия FF = (rMA2rSA2)0,5 Или Операция 6'. Рассчитайте коэффициенты корреляции rMA2 для максимального сродства(МАk) относительно величин эффективности сродства известной мишени (уk) и rSA-MA2 для суммарного сродства (SAk) - максимальное сродство относительно величин эффективности и сродства известной мишени (уk). Операция 7'. Рассчитайте коэффициент соответствия F 55 Модуль 6: Генерируйте генотип с минимальной степенью сродства. Операция 1. Задайте порог минимального соответствия Операция 2. Генерируйте случайный генотип (Модуль 1) Операция 3. Транслируйте генотип для построения фенотипа (Модуль 2) Операция 4. Проверьте сродство фенотипа к мишеням (Модули 3, 4, 5, 6) Операция 5. Если степень соответствия фенотипа превышает пороговое значение, прекратите генерацию кода и перейдите к исполнению Фазы 2. Иначе повторите операции 1-5. Модуль 7: Множественная мутация. Операция 1. Введите первичный код (из Фазы 1). Операция 2. Введите число (=q) мутаций в коде (в данном случае мутирует 2,5-5% символов в генотипе). Операция 3. Введите размер популяции(=р). Операция 4. Произвольно выберите позицию в генотипе. Операция 5. Замените символ кода в данной позиции другим, произвольно выбранным символом. Операция 6. Повторите операции 4 и 5, пока не достигнете числа q (q раз). Операция 7. Повторите операции 4-6, пока общая сумма новых генерированных кодов не достигнет р. Операция 8. Примените Модули 1-6 для проверки соответствия мутантной популяции. Выберите субпопуляцию с наибольшей селективностью для применения в Фазе 3. Модуль 8: Рекомбинация. Операция 1. Введите размер популяции(=р). Операция 2. Выберите произвольно два кода из популяции, генерированной Фазой 2. Операция 3. Произвольно выберите позицию в генотипе. Операция 4. Создайте случайное число для числа обмениваемых символов. Операция 5. Поменяйте местами символы между кодами, начиная с выбранной позиции. Операция 6. Повторите операции 2-5 до создания р новых генотипов. Операция 7. Примените Модули 2-6 для проверки соответствия мутантной популяции. Выберите субпопуляцию с наибольшей селективностью для следующей серии рекомбинаций или для созревания в Фазе 4. Модуль 9: Созревание. Операция 1. Введите начальный код, образованный на основании Фазы 3. Операция 2. Введите число итераций. Операция 3. Выберите произвольно позицию в исходном генотипе. 56 Операция 4. Замените символ кода в этой позиции на другой, произвольно выбранный символ. Операция 5. Проверьте селективность кода предшественника (Fp) и продукта мутации (Fм),используя Модули 2-6. Операция 6. Если FмFp, замените исходный генотип на продукт мутации. Операция 7. Повторите операции 3-6 требующееся число итераций. Модуль 10: Создание программного кода углеродного скелета. содержащего циклы (6 членные циклы, точка входа = точка выхода). Операция 1. Введите (длину) число символов в коде Введите v1, v2, v3, , vn (частота групп заместителей). Введите probring (частота последовательности кода цикла). (0probring1) Операция 2. Инициализируйте primecode = " ". Инициализируйте second-code = " ". Инициализируйте third-code = " ". Операция 3. Создайте строки символов. Повторите операцию 4 до получения кода заданной длины. Операция 4 а. Если probringrandom(случайное число) (0random1) то Присваивание символов кольцу (условие ванны). Задайте новыйсимвол 1 (newcharacter1) случайно выбранному члену изcharacter2) до 6 членам, произвольно выбранным из с 1, с 2, с 3, , сn, используя частоты(c1 с 2 представляют собой символы, определяющие различные функциональные группы). Присваивание символов валентностям заместителей. Задайте новыйсимволот 3character3) до 6 произвольно выбранным членам из '1', '2', '3', '4'. Иначе Операция 4b. Присваивание единичных(некольцевых) символов первичному коду. Задайте newcharacter1 (новыйсимвол 1) произвольно выбранному члену из '1', '2', '3','4'. Отнесение символов к заместителям. Задайте newcharacter2 произвольно выбранному члену из с 1, с 2, , сn, применяя частоты v1, v2, v3, , vn. Присваивание символов валентностям заместителей. 57 Задайте newcharacter3 произвольно выбранному члену из '1', '2', '3', '4'. Операция 4 с. Конкатенируйте новые символы со строками кода Primecode = Primecodecharacter3 Модуль 11: Множественная точечная мутация. Операция 1. Введите первичный код. Операция 2. Задайте число (=q) мутаций на код (В данном случае мутирует 2,5-5% символов генотипа). Операция 3. Введите размер популяции(=р). Операция 4. Произвольно выберите позицию в генотипе. Операция 5. Замените символы кода в этой позиции в каждом векторе кода другими, произвольно выбранными символами. Операция 6. Повторите операции 4 и 5 до q раз. Операция 7. Повторите операции 4-6, чтобы генерировать в сумме не р новых кодов. Операция 8. Проверьте соответствие каждого члена мутантной популяции. Отберите субпопуляцию с наибольшим соответствием для использования при рекомбинации или дополнительной множественной мутации 3. Модуль 12: Мутации последовательности. Операция 1. Задайте PDEL, PINV, PINS и PDUP как пороговые значения для наличия мутации(0 Рx1). Операция 2. Генерируйте произвольную позицию (=х) в коде (0 РДлина кода). Операция 3. Генерируйте случайную длину последовательности (=L) (0LДлина кода - х). Операция 4. Скопируйте последовательность из кода, начиная с х и с расширением до общей суммы L символов. Операция 5. Если 0 РINVСлучайное число 1 Тогда Перемените порядок символов в строке на обратный. Операция 6. Если 0 РDUPСлучайное число 1 Тогда Скопируйте последовательность и конкатенируйте копию с последовательностью. Операция 7. Если 0PDELСлучайное число 1 Тогда Элиминируйте L символов из кода, начиная с позиции х. Иначе Замените последовательность в коде на последовательность, генерированную в операциях 5 и 6. 58 Операция 8. Если 0PINSСлучайное число 1 Тогда Генерируйте позицию (=у) в коде произвольно (0 уДлина кода). Вставьте последовательность, генерированную в операциях 5 и 6, в позицию у. Модуль 13: Рекомбинация. Операция 1. Задайте размер популяции(=р). Операция 2. Отберите произвольно два кода из популяции, генерированной множественной мутацией. Операция 3. Выберите произвольно позицию в генотипе. Операция 4. Генерируйте случайное число для числа подлежащих обмену символов. Операция 5. Поменяйте местами символы между каждыми из трех векторов кода, начиная с выбранной позиции. Операция 6. Повторите операции 2-5 до момента генерации р новых генотипов. Операция 7. Проверьте соответствие каждого лиганда в образующейся мутантной популяции. Отберите субпопуляцию с наибольшим соответствием для следующих серий рекомбинации или для созревания. Модуль 14: Созревание. Операция 1. Введите начальный код, образованный из рекомбинации. Операция 2. Задайте число итераций. Операция 3. Задайте произвольно позицию в исходном генотипе. Операция 4. Замените символы кода в этих позициях в каждом векторе кода на другие, произвольно выбранные символы. Операция 5. Проверьте соответствие кода предшественника (Fp) и продукта мутации (Fм),используя Модули 4 и 5. Операция 6. Если FмFp, замените генотип предшественника на продукт мутации. Операция 7. Повторите операции 3-6 до требуемого числа итераций. ФОРМУЛА ИЗОБРЕТЕНИЯ 1. Способ компьютерного конструирования химических структур, обладающих предварительно выбранной функциональной характеристикой, включающий следующие стадии:(а) создание физической модели фенотипа моделированного рецептора, кодируемого в виде линейной последовательности символов, и создание набора молекул мишеней, имеющих,по меньшей мере, одну общую поддающуюся количественному измерению функциональную характеристику;(б) для каждой молекулы мишени(i) расчет сродства между рецептором и молекулой мишени в каждой из множества ориентаций с применением расчета эффективного сродства;(ii) расчет суммарного сродства суммированием вычисленных значений сродства;(в) применение вычисленных величин суммарного и максимального сродства для(i) расчета коэффициента корреляции максимального сродства между максимальным сродством и поддающейся количественному определению функциональной характеристикой;(ii) расчета коэффициента корреляции суммарного сродства между суммарным сродством и определяемой количественно функциональной характеристикой;(г) применение максимального коэффициента корреляции и суммарного коэффициента корреляции для расчета коэффициента соответствия;(д) изменение структуры рецептора и повторение стадий от (б) до (г) до получения популяции рецепторов, обладающих заранее выбранным коэффициентом соответствия;(е) создания физической модели химической структуры, кодируемой в виде молекулярной линейной последовательности символов; расчет сродства между химической структурой и каждым рецептором из множества ориентаций с применением указанного метода вычисления эффективного сродства, применение расчетных величин сродства для расчета степени соответствия сродства;(ж) изменение химической структуры для получения варианта химической структуры и повторение стадии (е); и(з) сохранение и дальнейшее изменение тех вариантов химической структуры, степень сродства которых приближается к заранее заданной (выбранной) степени сродства. 2. Способ по п.1, отличающийся тем, что линейная последовательность символов, кодирующих указанный фенотип рецептора, получается генерацией линейной последовательности символов рецептора, которая кодирует пространственное распределение и заряд, и также отличающийся тем, что стадия создания физической модели химической структуры включает генерацию указанной молекулярной линейной последовательности символов, которая кодирует пространственное распределение и заряд. 3. Способ по п.2, отличающийся тем, что указанный расчет эффективного сродства включает два критерия, причем первый является критерием проксимальности, отличающийся тем,что незаряженные участки указанного моделированного рецептора достаточно близки к неполярным участкам указанной молекулярной структуры, чтобы интенсивность эффективной Лондоновской дисперсии стало возможным определить, а второй является суммарной интенсивностью электростатического взаимодействия заряд-диполь, возникающего между заряженными участками указанного моделированного 60 рецептора и диполями, присутствующими в указанной молекулярной структуре. 4. Способ по п.2, отличающийся тем, что указанная стадия расчета степени соответствия сродства включает расчет суммарного и максимального сродства между молекулярной структурой и каждым рецептором, причем степень соответствия рассчитывают следующим образом:вычисленное максимальное сродство - максимальное сродство мишени/максимальное сродство мишени, и отличающийся также тем,что указанная предварительно выбранная степень соответствия практически равна нулю. 5. Способ по п.2, отличающийся тем, что указанная стадия расчета степени соответствия сродства включает расчет суммарного и максимального сродства между молекулярной структурой и каждым рецептором, причем степень соответствия рассчитывают следующим образом:(расчетное максимальное сродство - максимальное сродство мишени/2 максимальное сродство мишени) + (расчетное суммарное сродство - суммарное сродство мишени), и отличающийся также тем, что указанная предварительно выбранная степень соответствия практически равна нулю. 6. Способ по п.2, отличающийся тем, что указанный коэффициент корреляции суммарного сродства представляет собой rSA2, указанный коэффициент корреляции максимального сродства представляет собой rMA2, и также тем, что указанный коэффициент соответствия означаетF = (rMA2rSA2)0,5, а также тем, что предварительно выбранный коэффициент соответствия практически равен единице. 7. Способ по п.2, отличающийся тем, что указанный коэффициент корреляции суммарного сродства представляет собой rSA-MA2, указанный коэффициент корреляции максимального сродства представляет собой rMA2, также отличающийся тем, что указанный коэффициент соответствия представляет собой F = (rMA2(1rSA-MA20,5, и также тем, что указанный предварительно выбранный коэффициент практически равен единице. 8. Способ по п.2, отличающийся тем, что указанные молекулярные линейные последовательности символов включают множество последовательностей триплетов символов, причем первый символ указанного триплета произвольно выбран из набора первых символов, определяющих положение и идентичность "заселяющего" атома в молекулярном скелете указанной молекулярной структуры, второй символ указанного триплета произвольно выбран из набора вторых символов, определяющих идентичность заместителя, связанного с указанным "заселяющим" атомом, а третий символ указанного триплета произвольно выбирается из набора треть
МПК / Метки
МПК: G06N 7/00
Метки: создания, функциональные, химических, структур, имеющих, компьютерный, общие, способ, характеристики
Код ссылки
<a href="https://eas.patents.su/30-1095-kompyuternyjj-sposob-sozdaniya-himicheskih-struktur-imeyushhih-obshhie-funkcionalnye-harakteristiki.html" rel="bookmark" title="База патентов Евразийского Союза">Компьютерный способ создания химических структур, имеющих общие функциональные характеристики</a>
Способ регулирования синтеза химических продуктов, синтез химических продуктов и устройство регулирования синтеза

Номер патента: 343
Опубликовано: 29.04.1999
Автор: Де Селлиер Жак
МПК: G05B 13/02, G05D 21/02, C08F 10/00...
Метки: синтеза, устройство, регулирования, способ, химических, синтез, продуктов
Формула / Реферат:
1. Способ регулирования синтеза, по меньшей мере, одного химического соединения, протекающего на установке, содержащей, по меньшей мере, один реактор (R) типа реактора с идеальным перемешиванием, при котором одна или несколько регулирующих величин (GC) воздействуют на ход синтеза, обеспечивая равенство одной или нескольких величин, связанных со свойствами продукта и/или с ходом синтеза, называемых регулируемыми величинами (GR), соответствующими...
Способ и устройство для уничтожения химических боевых веществ

Номер патента: 631
Опубликовано: 29.12.1999
Авторы: Эйбел Альберт Е., Хейдак Элан Ф., Мук Роберт В., Гетмэн Герри Д., Стескал Марк Д., Блам Бентли Дж.
МПК: C02F 1/76, A62D 3/00, B01J 14/00...
Метки: веществ, уничтожения, устройство, химических, боевых, способ
Формула / Реферат:
1. Способ уничтожения химического боевого вещества, включающий: А) получение реакционной смеси из исходных веществ, которые включают: (1) азотсодержащее основание; (2) по меньшей мере, одно химическое боевое вещество; и (3) активный металл в количестве достаточном для уничтожения химического боевого вещества; и Б) осуществление взаимодействия компонентов указанной смеси при наличии сольватированных электронов. 2. Способ по п.1,...
Устройство и способ разделения веществ и проведения химических реакций для отделения летучих газов из материала, содержащего, по меньшей мере, одно летучее вещество

Номер патента: 512
Опубликовано: 28.10.1999
Авторы: Олбаф Ренди, Хок Грегори Г.
Метки: химических, веществ, мере, вещество, летучих, отделения, одно, проведения, газов, устройство, летучее, разделения, меньшей, реакций, содержащего, способ, материала
Формула / Реферат:
1. Устройство для химической обработки материалов и проведения реакций, в частности для отделения летучих газов из материала, содержащего, по меньшей мере, одно летучее вещество, отличающееся тем, что оно содержит реторту размещения обрабатываемого материала, установленную с возможностью вращения относительно центральной оси, систему обработки отходящих газов и приема летучих газов из реторты, патрубок, расположенный выходящим из реторты,...
Способ и устройство для создания рисунков в литых материалах

Номер патента: 269
Опубликовано: 25.02.1999
Автор: Аустин Марк
МПК: B29C 31/02, B28B 1/08, B44F 7/00...
Метки: устройство, литых, рисунков, способ, материалах, создания
Формула / Реферат:
1. Способ создания многоцветных рисунков и узоров в литых материалах, включающий следующие этапы:a) подготовку формы для приема литейных смесей;b) подготовку, по крайней мере, двух мокрых литейных смесей разного цвета с определенной вязкостью для обеспечения ровного разлива смеси;c) загрузку литейных смесей в емкость с соблюдением определенного геометрического (пространственного) расположения в соответствии с формулой, разработанной для...
Устройство с циркуляционным кипящим слоем для химических и физических процессов

Номер патента: 664
Опубликовано: 28.02.2000
Автор: Руотту Сеппо
МПК: B01J 8/18
Метки: устройство, циркуляционным, химических, физических, кипящим, слоем, процессов
Формула / Реферат:
1.Устройство для проведения физических и химических процессов, содержащее два отдельных технологических блока, в которых используется среда с твердыми частицами, в котором второй технологический блок служит для регенерации твердых частиц, загрязненных в первом технологическом блоке, содержащее первый реактор (1-3) для проведения реакции в первом блоке, второй реактор (4-6) для проведения реакции во втором блоке, расположенный между первым...
Предыдущий патент: Персональная система электронной книги.
Следующий патент: Трансформатор / реактор постоянного тока
Случайный патент: Газовая турбина для подъёма нефти