Система и способ создания многоязычной базы данных




























Формула / Реферат
1. Способ перевода сегмента документа на первом языке в сегмент документа на втором языке, содержащий следующие этапы:
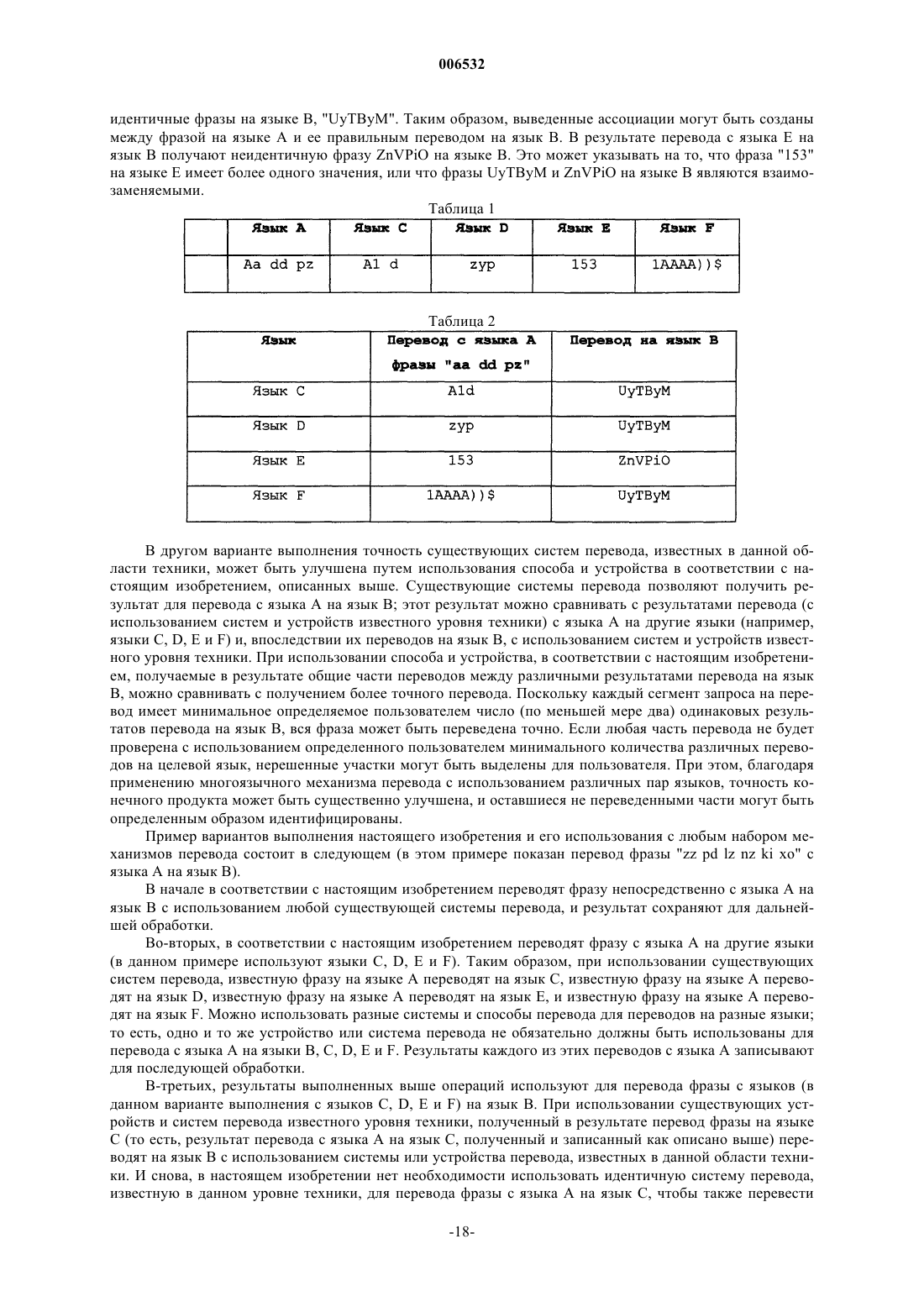
получение первой ассоциации между сегментом документа на первом языке и сегментом документа на каждом из множества третьих языков с использованием существующих систем перевода;
манипулирование первой ассоциацией для получения второй ассоциации между сегментом документа на каждом из множества третьих языков и вторым языком с использованием существующих систем перевода;
идентификация по меньшей мере двух идентичных сегментов выборки, в качестве выведенного сегмента ассоциации на втором языке, с использованием указанных вторых ассоциаций; и
ассоциирование выведенного сегмента ассоциации на втором языке с сегментом документа на первом языке.
2. Способ по п.1, в котором множество третьих языков включает по меньшей мере один третий язык.
3. Способ по п.2, дополнительно содержащий идентификацию неидентичных сегментов выборки в качестве взаимозаменяемых сегментов, с использованием способа идентификации сегментов с эквивалентным семантическим значением.
4. Компьютерное устройство, включающее в себя процессор, запоминающее устройство, подключенное к процессору, и программу, записанную в запоминающее устройство, в котором компьютер выполнен с возможностью выполнения программы и выполняет следующие этапы:
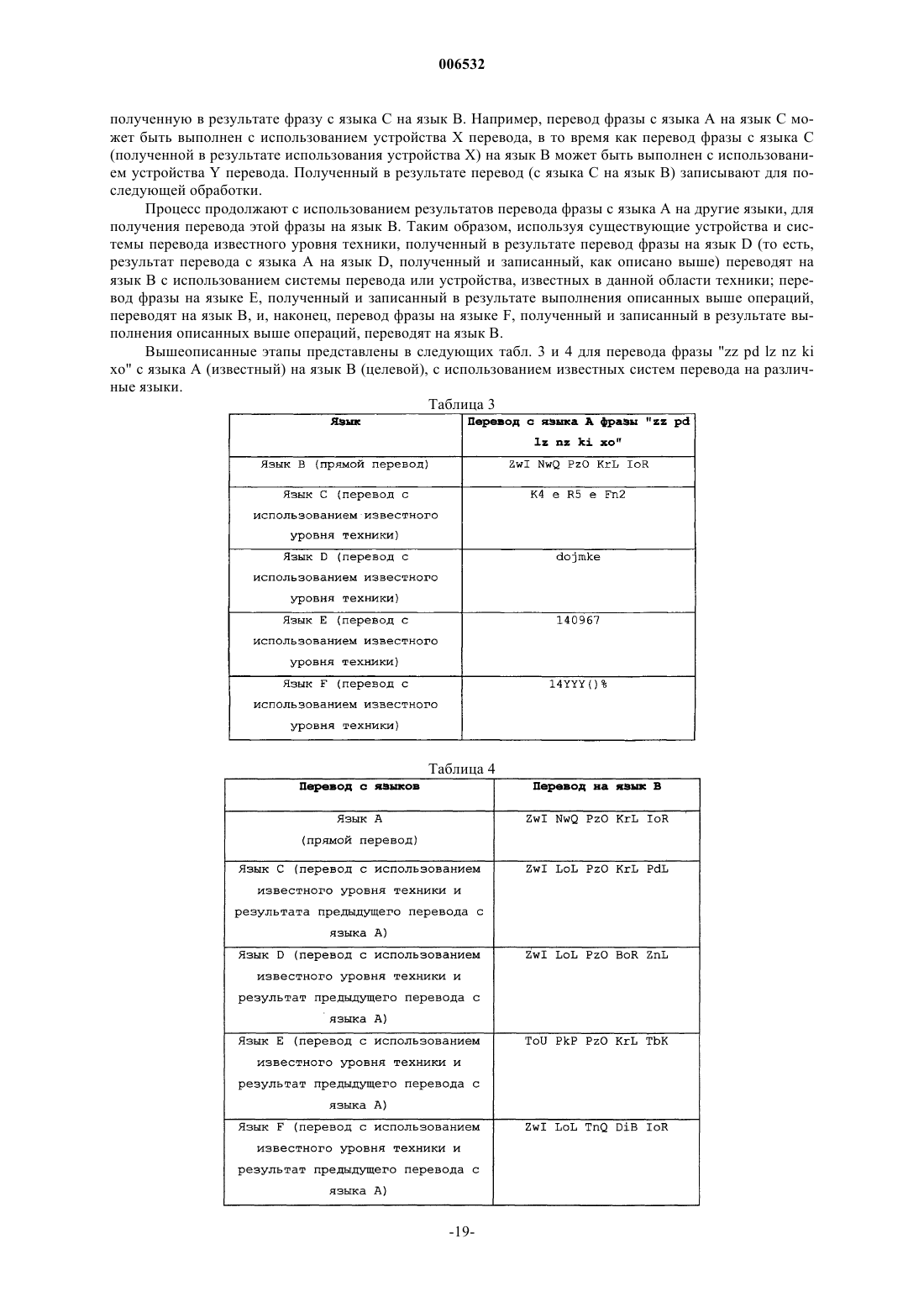
получение первой ассоциации между сегментом документа на первом языке и сегментом документа на каждом из множества третьих языков, с использованием существующей системы перевода;
манипулирование первой ассоциацией для получения второй ассоциации между сегментом документа на каждом из множества третьих языков и вторым языком с использованием существующих систем перевода;
идентификация по меньшей мере двух идентичных сегментов выборки, в качестве выведенного сегмента ассоциации на втором языке, с использованием указанных вторых ассоциаций; и
ассоциирование выведенного сегмента ассоциации на втором языке с сегментом документа на первом языке.
5. Компьютерное устройство по п.4, в котором множество третьих языков включает по меньшей мере один язык.
6. Компьютерное устройство по п.5, дополнительно выполненное с возможностью выполнения этапа идентификации неидентичных сегментов выборки в качестве взаимозаменяемых сегментов путем идентификации сегментов с эквивалентным семантическим значением.
7. Считываемый компьютером носитель записи, на котором записана программа, выполняемая компьютерным процессором, для выполнения следующих этапов:
получение первой ассоциации между сегментом документа на первом языке и сегментом документа на каждом из множества третьих языков, с использованием существующей системы перевода;
манипулирование первой ассоциацией для получения второй ассоциации между сегментом документа на каждом из множества третьих языков и вторым языком с использованием существующих систем перевода;
идентификация по меньшей мере двух идентичных сегментов образца, в качестве выведенного сегмента ассоциации на втором языке, с использованием указанных вторых ассоциаций; и
ассоциирование выведенного сегмента ассоциации на втором языке с сегментом документа на первом языке.

Текст
006532 Ссылка на родственные заявки на патент Настоящая заявка представляет собой частичное продолжение заявки на американский патент 10/024,473, поданной 21 декабря 2001 г., и требует приоритета предварительной заявки на американский патент 60/276,107, поданной 16 марта 2001 г., и предварительной заявки на американский патент 60/299,472 поданной 21 июня 2001 г., причем все эти публикации включены в настоящее описание в качестве ссылки. Область техники, к которой относится изобретение Настоящее изобретение относится к способу и устройству, предназначенным для создания многоязычной базы данных, которые можно использовать для преобразования содержания из одного состояния во второе состояние. Уровень техники Известны устройства и способы, предназначенные для автоматического перевода документов с одного языка на другой. Однако эти устройства и способы часто не позволяют получить точный перевод с одного языка на другой, для их работы может требоваться значительное время и они могут быть неудобными для использования. Кроме переводчиков, работающих с непосредственным участием человека,другие известные устройства включают коммерчески доступные программные средства машинного перевода. Такие известные системы имеют недостатки, что делает их подверженными ошибкам, снижает скорость работы и повышает неудобство. Известные устройства и способы перевода не позволяют постоянно получать точный перевод вводимого текста и поэтому часто требуют интенсивного вмешательства пользователя для проверочного чтения и редактирования. Обеспечить точный машинный перевод более сложно, чем создать устройства и способы, выполняющие дословный перевод документов. В системах с дословным переводом результат часто получается бессмысленным для читателя переведенного документа, поскольку способ дословного перевода приводит к неверному выбору слов и несогласованным грамматическим единицам. Для преодоления этих недостатков при разработке известных устройств перевода в течение многих десятилетий делались попытки обеспечить перевод слов в соответствии с контекстом предложения, на основе комбинации или набора лексических, морфологических, синтаксических и семантических правил. Эти системы, известные в данной области техники, как системы машинного перевода (МП, МТ), "основанные на определенных правилах", обладают недостатками, поскольку существует такое большое количество исключений из правил, что они не позволяют постоянно обеспечить получение точного перевода. В дополнение к способу МТ на основе правил, за последнее десятилетие был разработан новый способ МТ, известный как способ "основанный на примере" (ОПМП, ЕВМТ). В ЕВМТ используют предложения (или, возможно, части предложений), записанные на двух различных языках в базе данных сопоставления языков. Когда запрос на перевод находит соответствующее предложение в базе данных,перевод предложения на целевом языке получают с использованием базы данных, что обеспечивает точный перевод на второй язык. Если часть запроса на перевод соответствует части предложения в базе данных, эти устройства делают попытку точного определения, какая часть предложения, сопоставленная с предложением на языке-источнике, представляет собой перевод запроса. Системы ЕВМТ не позволяют обеспечить точный перевод широко употребляемого языка, поскольку базы данных с сопоставленными предложениями на разных языках строят вручную, и они всегда остаются преимущественно "неполными". Другой недостаток систем ЕВМТ состоит в том, что при частичном совпадении не получают надежный перевод. Были сделаны попытки автоматизировать создание баз данных, в которых сопоставляются разные языки, с использованием частей переведенных документов,предназначенных для использования в ЕВМТ. Однако эти попытки не были успешными при создании осмысленных, точных баз данных с сопоставлением языков достаточного размера. Ни в одной из этих попыток не использовали алгоритм, который позволил бы надежно и точно корректировать переводы с существенным количеством слов и строк слов, полученных из пары переведенных документов. В некоторых устройствах перевода комбинируют оба механизма перевода - на основе правил и ЕВМТ. Хотя такая комбинация подходов может обеспечить более высокую точность, чем любая из этих систем по отдельности, результаты остаются неадекватными для использования без существенного вмешательства и редактирования пользователя. Проблемы, с которыми сталкиваются при попытке перевода документов с одного языка на другой,в более общем смысле, можно свести к проблеме преобразования данных, представляющих идеи или информацию, из одного состояния, скажем, в форме слов, в данные, представляющие идеи в другом состоянии, например, в виде математических символов. В таких случаях требуется использовать базы данных ассоциаций сопоставленных идей, которые ассоциируют данные в одном состоянии с эквивалентными данными во втором состоянии. Поэтому существует потребность в улучшенном и более эффективном способе и устройстве, предназначенных для создания словарей или баз данных, которые содержат ассоциированные эквивалентные идеи на разных языках или в различных состояниях (например, в виде слов, строк слов, звуков, движений и т.п.), и для перевода или преобразования идей, передаваемых документами на одном языке или в одном состоянии, в те же или аналогичные идеи, представленные документами на втором языке или в другом состоянии.-1 006532 Настоящее изобретение относится к изменению состояния с использованием базы данных ассоциаций сопоставленных идей. В частности, настоящее изобретение относится к способу и устройству, предназначенным для создания базы данных ассоциированных идей, и направлено на способ и устройство,направленное на использование этой базы данных, для преобразования идей из одного состояния в другие состояния. В одном варианте выполнения и в качестве примера, настоящее изобретение предлагает способ и устройство, предназначенные для создания базы данных перевода с языка, в которой формируют базу данных ассоциированных идей на двух языках. Настоящее изобретение также направлено на способ и устройство, предназначенные для использования языковой базы данных для преобразования документов(представляющих идеи) с одного языка на другой (или, в более общем случае, из одного состояния в другое). Однако настоящее изобретение не ограничивается переводом с языка, хотя этот предпочтительный вариант выполнения будет представлен ниже. Аспект создания базы данных, в соответствии с настоящим изобретением, может быть применен к любым идеям, которые связаны друг с другом определенным образом, но выражены в различных состояниях, и аспект преобразования в соответствии с настоящим изобретением можно использовать для точного перевода идеи из одного состояния в другое. Ниже будет описан вариант применения настоящего изобретения для перевода с языка. Используемые здесь термины, связанные с преобразованием, переводом и изменением, являются взаимозаменяемыми и применяются в их самом широком смысле. Раскрытие изобретения Настоящее изобретение направлено на обеспечение эффективного перевода документов с одного языка или из одного состояния на другой язык или в другое состояние с помощью способа и устройства,направленных на создание и дополнение баз данных ассоциаций сопоставленных идей. В этих базах данных обычно ассоциируют данные в первой форме или состоянии, которые представляют конкретные идеи или части информации, с данными во второй форме или во втором состоянии, которые представляют те же идеи или части информации. Другая цель настоящего изобретения состоит в облегчении перевода документов с одного языка или из одного состояния на другой язык или в другое состояние с использованием способа и устройства,предназначенных для создания второго документа, содержащего данные во втором состоянии, форме или на втором языке, из первого документа, содержащего данные в первом состоянии, форме или на первом языке, в результате чего первый и второй документы будут представлять, по существу, одни и те же идеи или информацию. Еще одна цель настоящего изобретения состоит в облегчении перевода документов с одного языка или состояния на другой язык или состояние с помощью способа и устройства, предназначенных для создания второго документа, содержащего данные во втором состоянии, форме или на втором языке, с первого документа, содержащего данные в первом состоянии, форме или на первом языке, в результате чего первый и второй документы представляют, по существу, одни и те же идеи или информацию, и в котором способ и устройство включают использование базы данных ассоциаций сопоставленных идей. Еще одна цель настоящего изобретения состоит в получении перевода документов (в широком смысле, преобразование идей из одного состояния в другое состояние) в режиме реального времени. Настоящее изобретение обеспечивает достижение этих и других целей с помощью способа и устройства, предназначенных для создания базы данных сопоставленных идей. Способ и устройство для создания базы данных сопоставленных идей могут включать получение одной или нескольких пар документов на двух (или больше) различных языках, представляющих один и тот же общий текст (то есть,точный перевод текста ("Параллельный текст") или, в общем, взаимосвязанный текст ("Сопоставимый текст"). В настоящем изобретении выбирают, по меньшей мере, первое и второе место появления всех слов и строк слов, которые появляются в множестве мест появления на первом языке, в доступных документах на сопоставленных языках. Затем в настоящем изобретении выбирают, по меньшей мере, первый диапазон слова и второй диапазон слова в документах на втором языке, в котором первый и второй диапазоны слов соответствуют первому и второму местам появления выбранных слов или строк слов в документах на первом языке. Затем выполняют сравнение слов и строк слов, найденных в первом диапазоне слов со словами и строками слов, найденными во втором диапазоне слов и, находят общие слова и строки слов для обоих диапазонов слов, и записывают эти найденные общие слова и строки слов в базу данных сопоставленных идей. Настоящее изобретение затем ассоциирует в указанной базе данных сопоставленных идей найденные общие слова или строки слов в двух диапазонах на втором языке с выбранным словом или строками слов на первом языке, ранжированными по частоте их ассоциации (количеству повторений), после установки частоты ассоциации, как подробно описано в настоящем описании. Путем проверки общего слова и строки слов по языкам в Параллельных или Сопоставимых текстах, база данных позволяет находить больше ассоциаций, по мере того, как большее количество Параллельных или Сопоставимых текстов становится доступным на множестве различных языков. Настоящее изобретение также позволяет достичь эти и другие цели с помощью способа и устройства, предназначенных для преобразования документа из одного состояния в другое состояние. Настоящее изобретение направлено на базу данных, состоящую из сегментов данных на первом языке, ассоцииро-2 006532 ванных с сегментами данных на втором языке (созданную с помощью описанных выше способов или вручную). Настоящее изобретение переводит текст путем поиска в вышеуказанной базе данных, и идентифицирует самую длинную строку слов в переводимом документе (измеряемую по количеству слов),начинающуюся с первого слова в документе, который имеется в базе данных. Система затем находит в базе данных строку слов на втором языке, ассоциируемую с найденной строкой слов из документа на первом языке. Система затем выбирает вторую строку слов в документе, находящемся в базе данных, и содержит перекрывающееся слово (или, в качестве альтернативы, строку слов) с ранее идентифицированной строкой слов в документе, и находит в базе данных строку слов на втором языке, ассоциированном со второй строкой слова на первом языке. Если ассоциации строки слов на втором языке содержат перекрывающееся слово (или, в качестве альтернативы, слова), ассоциации строки слов на втором языке комбинируют (удаляя избыточные слова в перекрывающейся части) для формирования перевода; в противном случае получают ассоциации на втором языке для строки слов на первом языке и проверяют возможность комбинирования с использованием наложения слов до тех пор, пока не будет получен успешный результат. Следующую строку слов в документе на первом языке выбирают путем поиска самой длинной строки слов в базе данных, которая содержит перекрывающееся слово (или, в качестве альтернативы, слова) с ранее идентифицированной стройкой слов на первом языке, и вышеуказанный процесс повторяют до тех пор, пока весь документ на первом языке не будет переведен в документ на втором языке. Краткое описание чертежей На прилагаемой фигуре представлен вариант выполнения базы данных сопоставленных идей в соответствии с настоящим изобретением. Осуществление изобретения Настоящее изобретение направлено на способ и устройство, предназначенные для создания и дополнения базы данных сопоставленных идей и для перевода документов с первого языка или из первого состояния на второй язык или во второе состояние с использованием базы данных сопоставленных идей. Описываемые здесь документы представляют собой подборку информации в форме идей, которые представлены символами и знаками, зафиксированными на некотором носителе. Например, документы могут представлять собой электронные документы, записанные на магнитном или оптическом носителях, или бумажные документы, такие как книги. Символы и знаки, содержащиеся в документах, представляют идеи и информацию, выраженную с использованием одной или больше систем выражения, предназначенных для понимания пользователями документов. В настоящем изобретении изменяют документы в первом состоянии, то есть, в состоянии, когда они содержат информацию, выраженную в одной системе выражения, для получения документов во втором состоянии, то есть, когда они содержат, по существу,ту же информацию, выраженную с использованием второй системы выражения. Таким образом, настоящее изобретение позволяет применять или переводить документы между системами выражения, например, с одних письменных и разговорных языков, таких как английский, иврит и кантонский диалект китайского языка, на другие языки. Ниже будет представлено подробное описание настоящего изобретения, включая способ и устройство, предназначенные для создания базы данных, а также способ и устройство, предназначенные для преобразования. 1. Способ и устройство для создания базы данных. а. Обзор. В способе в соответствии с настоящим изобретением используют базу данных сопоставленных идей для изменения содержания документа. На фигуре представлен вариант выполнения базы данных сопоставленных идей. Этот вариант выполнения базы данных сопоставленных идей содержит список ассоциированных сегментов данных, представленных в колонках 1 и 2. Сегменты данных представляют собой символы или группы знаков, которые представляют определенную идею или часть информации в системе выражения. Таким образом, сегменты системы А в колонке 1 представляют собой сегменты данных, которые представляют различные идеи и комбинации идей Da1, Da2, Da3 и Da4 в гипотетической системе выражения А. Сегменты в системе В, представленные в колонке 2, являются сегментами данныхDb1, Db3, Db4, Db5, Db7, Db9, Db10 и Db12, которые представляют различные идеи и некоторые комбинации этих идей в гипотетической системе выражения В, которые упорядочены по частоте ассоциации с сегментами данных в системе выражения А. В колонке 3 представлена непосредственная частота, которая представляет собой количество ассоциаций сегмента или сегментов на языке В с приведенным в списке сегментом (или сегментами) на языке А. В колонке 4 представлены частоты после вычитания, которые представляют собой количество ассоциаций сегмента (или сегментов) данных на языке В с сегментом (или сегментами) на языке А после вычитания количества ассоциаций сегмента (или сегментов), в качестве части более крупного сегмента, как более полно описано ниже. Как показано на фигуре, возможен случай, когда одиночный сегмент, например Da1, наиболее соответствующим образом будет ассоциирован с множеством сегментов Db1, вместе с Db3 и Db4. Чем выше значение частоты после вычитания (как описано в настоящем описании) между сегментами данных,тем выше вероятность, что сегмент в системе А будет эквивалентен сегменту в системе В. В дополнение-3 006532 к измеренным откорректированным частотам по общему количеству случаев появления, откорректированные частоты также можно измерять, например, путем расчета процентных отношений соответствия конкретных сегментов системы А конкретным сегментам системы В. Когда базу данных используют для перевода документа, ассоциированный сегмент с наивысшим рангом получают из базы данных, прежде всего, в процессе перевода. Однако часто при использовании способа, обычно применяемого для проверки комбинации ассоциированных сегментов для перевода (как описано ниже), определяют, что должна быть проверена другая ассоциация, с более низким рангом, поскольку ассоциацию с более высоким рангом после проверки нельзя использовать. Например, если в базу данных был сделан запрос для ассоциации Da1, будет получено Db1+Db3+Db4; и если Db1+Db3+Db4 нельзя использовать, что определяют с помощью процесса, который точно комбинирует сегменты данных для перевода, база данных тогда вернет Db9+Db10 для проверки на наличие точной комбинации с другим ассоциированным сегментом для перевода. В общем, способ создания базы данных сопоставленных идей, в соответствии с настоящим изобретением, включает проверку и работу с использованием подходов Параллельного или Сопоставимого текста. При использовании способа и устройства в соответствии с настоящим изобретением создают базу данных ассоциаций между двумя состояниями - точными преобразованиями, или более конкретно, ассоциаций между идеями, в том виде, как они выражены в одном состоянии, и идеями в том виде, как они выражены в другом состоянии. Перевод и другие соответствующие ассоциации между двумя состояниями становятся более строгими, то есть, более частыми, по мере увеличения проверяемых документов в ходе работы настоящего изобретения, так что при работе по достаточно большой "выборке" документов наиболее часто встречающиеся (и, в определенном смысле, правильные) ассоциации становятся все более очевидными, и тогда способ и устройство в соответствии с настоящим изобретением можно использовать для преобразования. В одном варианте выполнения настоящего изобретения два состояния представляют языки мира(например, английский язык, иврит, китайский язык и т.д.) так, что настоящее изобретение позволяет создать базу данных сопоставленных языков, выполняющую корреляцию слов и строк слов на одном языке с их соответствующими переводами на другом языке. Строки слов могут быть определены как группы последовательных, расположенных рядом друг с другом слов и часто включают знаки пунктуации и любые другие отметки, используемые в языке выражения. В данном примере в настоящем изобретении создают базу данных путем анализа документов на двух языках и базу данных перевода для каждого возникающего слова или строки слов на обоих языках. Однако настоящее изобретение не обязательно должно быть ограничено переводом на языки. Настоящее изобретение позволяет пользователю создавать базу данных и идей и ассоциировать эти идеи с другими, отличными идеями с использованием иерархического порядка. При этом идеи ассоциируют с другими идеями и ранжируют в соответствии с частотой возникновения. Удельный вес, задаваемый для частоты возникновения, и использование, применимое к полученной, таким образом, базе данных, могут изменяться в зависимости от требований пользователя. Например, в контексте преобразования текста с одного языка на другой, настоящее изобретение может работать для создания языкового перевода слов и строк слов между английским и китайским языками. Настоящее изобретение позволяет получать ранжирование ассоциаций между словами и строками слов для двух языков. С учетом достаточно большого размера выборки слово или строка слов, появляющиеся более часто, будут представлять собой один из китайских эквивалентов английского слова или строки слов. Однако настоящее изобретение также позволяет получать другие ассоциации на китайском языке для английских слов или строк слов, и пользователь может регулировать эти ассоциации по собственному усмотрению. Например, для слова "mountain" (гора), когда с ним работают в соответствии с настоящим изобретением, могут быть получены список слов и строк слов на китайском языке при исследовании этого языка. Эквиваленты на китайском языке для слова "mountain", наиболее вероятно, будут иметь самый высокий ранг; однако, настоящее изобретение позволяет получать другие слова на иностранном языке или строки слов, ассоциированные со словом "mountain", такие, как "snow" (снег), "ski"(лыжи), "dangerous sport" (опасный спорт), "the highest point in the world" (самая высокая точка в мире),или "Mt.Everest" (гора Эверест). Этими словами и строками слов, которые, вероятно, будут иметь более низкий ранг, чем переводы слова "mountain", можно манипулировать по желанию пользователя. Таким образом, настоящее изобретение представляет собой устройство для автоматизированного создания базы данных ассоциаций. Самые строгие ассоциации представляют собой "переводы" или "преобразования" в одном смысле, но другие часто возникающие (но более слабые) ассоциации представляют идеи, которые близко связаны с исследуемой идеей. Базы данных поэтому можно применять в системах, в которых используют приложения искусственного интеллекта, которые хорошо известны в данной области техники. В этих системах в настоящее время используют неполные, созданные вручную базы данных идей или онтологии в качестве "нейронных сетей" для различных вариантов применения. В других вариантах выполнения настоящего изобретения используется вычислительное устройство,такое, как система персонального компьютера, доступная в известном уровне техники. Хотя вычислительное устройство обычно представляет собой персональный компьютер общего назначения (как от-4 006532 дельный, так и подключенный к сетевому окружению), возможность применения других вычислительных устройств типа КПК (карманный персональный компьютер), беспроводные устройства, серверы,универсальные ЭВМ и т.п., также рассматривается в настоящем изобретении. Однако способ и устройство, в соответствии с настоящим изобретением, не обязательно требуется использовать с таким вычислительным устройством, и их можно непосредственно выполнять с использованием других средств, включая создание сопоставленных ассоциаций вручную. Способ, с помощью которого выполняют анализ последующих документов для увеличения "выборки" документов и создания базы данных сопоставленных ассоциаций, может быть выполнен различным образом - документы можно анализировать и изменять вручную, путем автоматической подачи (например, с использованием автоматических загрузчиков листов бумаги, как известно в предшествующем уровне техники), или с использованием технологий поиска по Интернет, для автоматического поиска соответствующих документов, например сетевых поисковых механизмов. Следует отметить, что настоящее изобретение позволяет формировать ассоциированную базу данных путем анализа Сопоставимого текста, в дополнение к (или даже вместо) Параллельного текста. Кроме того, способ позволяет выполнять просмотр всех доступных документов в совокупности при поиске встречающегося слова или строки слов в языке.b. Построение базы данных. В соответствии с настоящим изобретением документы анализируют с целью построения базы данных. После ввода документа (снова, пар документов, представляющих один и тот же текст на двух различных языках), процесс создания начинается с использования способов и/или устройства, описанных в настоящем описании. Для иллюстрации предположим, что документы содержат одинаковое содержание (или, в общем смысле, идею) на двух различных языках. Документ А написан на языке А, Документ В написан на языке В. Документы содержат следующий текст: Первый этап в соответствии с настоящим изобретением состоит в расчете диапазона слова для определения приблизительного расположения возможных ассоциаций для любого заданного слова или строки слов. Поскольку анализ дословного сопоставления языков, сам по себе, не позволяет получить результат (то есть, слово 1 в документе А часто не существует как дословный перевод слова 1 в документе В), и структура предложения одного языка может выражать эквивалентную идею с использованием различного расположения (или порядка) слов в предложениях, чем в другом языке, техника построения базы данных, в соответствии с настоящим изобретением, ассоциирует каждое слово или строку слов на первом языке со всеми словами и строками слов, найденными в выбранном диапазоне в документе на втором языке. Это также важно, поскольку один язык часто выражает идеи с использованием более длинных или более коротких строк слов, чем в другом языке. Диапазон определяют путем анализа двух документов и используют для сравнения слов и строк слов во втором документе со словами и строками слова в первом документе. То есть, диапазон слов или строк слов во втором документе анализируют для поиска возможных ассоциаций для каждого слова и строки слов в первом документе. При проверке диапазона способ создания базы данных устанавливает количество слов или строк слов на втором языке,которые могут быть эквивалентными, и переводит слова и строки слов на первом языке. Существуют два атрибута, которые следует определять для установления диапазона в документе на втором языке, для поиска ассоциаций любого заданного слова или строки слов на языке первого документа. Первый атрибут представляет собой значение или размер диапазона во втором документе, измеряемый по количеству слов в диапазоне. Второй атрибут представляет собой местоположение диапазона во втором документе, измеряемое путем размещения средней точки диапазона. Оба атрибута определяются пользователем, но примеры предпочтительных вариантов выполнения приведены ниже. При определении размера и местоположения диапазона цель состоит в том, чтобы обеспечить высокую вероятность того, что будет включен перевод слова или строки слов на второй язык анализируемого сегмента на первом языке. Для определения размера или значения диапазона можно использовать различные методики, включая общие статистические методики, такие как отклонение кривой нормального распределения, полученной на основе количества слов в документе. При использовании статистической методики, такой как кривая нормального распределения, в начале и в конце документа будет получено меньшее значение диапазона, чем в середине документа. Частота по кривой нормального распределения для диапазона позволяет получить разумную возможность экстраполяции перевода, независимо от того, получена ли она по абсолютному количеству слов в документе или в соответствии с определенным процентом появления слов в документе. Существуют другие способы расчета диапазона, такие как "пошаговая" методика, в которой существует определенный диапазон на одном уровне для определенного процентного содержания слов, второй более высокий уровень для другого процентного содержания слов и третий уровень,-5 006532 равный первому уровню для последнего процентного содержания слов. И снова, все атрибуты диапазона могут быть определены пользователем или установлены в соответствии с другими возможными параметрами, с целью захвата полезных ассоциаций для анализируемого слова или строки слов на первом языке. Местоположение диапазона в документе на втором языке может зависеть от сравнения количества слов в двух документах. Определение документа для целей расположения диапазона зависит от пользователя и, в качестве примера, можно привести статьи новостей, разделы книги и любые другие дискретно идентифицируемые блоки содержания, состоящие из множества сегментов данных. Если содержание слов в двух документах примерно одинаково, расположение диапазона во втором языке будет приблизительно совпадать с расположением анализируемых слова или строки слов на первом языке. Если количество слов в двух документах не равно, тогда можно использовать соотношение для правильной установки и расположения диапазона. Например, если документ А содержит 50 слов, и документ В содержит 100 слов, тогда отношение между двумя документами составит 1:2. В середине документа А находится положение 25 слова. Однако, анализ слова 25 в документе А с использованием этой срединной точки (положение 24 слова), как положение середины диапазона в документе В, не будет эффективным, поскольку это положение (положение 25 слова) не является серединой документа В. Вместо этого срединную точку диапазона в документе В для анализа слова 25 в документе А можно определить по соотношению слов между двумя документами (то есть, 25 х 2/1=50), с использованием расположения вручную в срединной точке документа В или с помощью других методик. При анализе положения слова или строки слов в документе, когда отмечают все слово или строки слов, которые находятся в пределах диапазона, как описано выше, техника создания базы данных, в соответствии с настоящим изобретением, позволяет получить возможный набор слов или строк слов в документе на втором языке, которые позволяют переводить каждое слово или строку слов в первом анализируемом документе. При использовании техники создания базы данных, в соответствии с настоящим изобретением, набор слов и строк слов, которые можно квалифицировать, как возможные переводы, будет сужаться по мере развития частот ассоциации. Таким образом, после анализа пары документов настоящее изобретение позволяет создавать частоты ассоциации для слов и строк слов на одном языке со словами или строками слов на втором языке. После анализа множества пар документов в соответствии с настоящим изобретением (и, таким образом, после создания большой выборки), методика создания базы данных ассоциаций сопоставленных языков будет обеспечивать все более и более высокие частоты ассоциаций для любого одного слова или строки слов. После использования достаточно большой выборки,наивысшие частоты ассоциации позволят получить возможные переводы; конечно, конечная точка, в которой частота ассоциации рассматривается как точный перевод, определяется пользователем и зависит от других методик перевода (таких, как описаны в предварительной заявке на патент 60/276107, под названием "Method and Apparatus for Content Manipulation", поданной 16 марта 2001 г. и приведенной здесь в качестве ссылки). Как указано выше, в настоящем изобретении выполняют проверку не только слов, но также и строк слов (множества слов). Как отмечено, строки слов включают всю пунктуацию и другие имеющие в тексте метки. После анализа одного слова на первом языке по методике создания базы данных, в соответствии с настоящим изобретением, выполняют анализ строки слов, состоящей из двух слов, затем строки слов, состоящей из трех слов, и так далее с постепенным приращением. Такая методика позволяет переводить слова или строки слов на одном языке, с использованием более короткой или более длинной строки слов (или слова) на другом языке, как часто случается при переводе. Если слово или строка слов появляется только один раз во всех доступных документах на первом языке, процесс немедленно переходит к анализу следующего слова или строки слов, при этом снова выполняется цикл анализа. Анализ останавливается, когда все слово или строки слов, которые появляются много раз на первом языке во всех доступных Параллельных и Сопоставимых текстах, будут проанализированы. В определенном смысле любое количество документов могут быть объединены и их можно обрабатывать как один целый документ для поиска мест повторного появления слов или строк слов. В сущности, слово или строка слов, для которых отсутствует повторение, может появляться только один раз во всем доступном Параллельном и Сопоставимом тексте. Кроме того, в качестве другого варианта выполнения, можно анализировать диапазон, соответствующий каждому слову и строке слов независимо от того, появляется ли оно более, чем один раз во всем доступном Сопоставимом и Параллельном тексте. В качестве другого варианта выполнения, база данных может быть построена на основе поиска решения для конкретных слов и строк слов, которые представляют собой часть запроса. Когда слова и строки слов вводят для перевода, настоящее изобретение может осуществлять поиск множества мест появления слов или строк слов в документах сопоставленных языков, записанных в запоминающем устройстве, которые еще не были проанализированы, путем размещения текста сопоставленных языков в сети Интернет, с использованием системы поиска всемирной сети и других устройств и, наконец, устройство может попросить пользователя ввести отсутствующую ассоциацию на основе анализа запроса и отсутствия достаточного объема доступного материала для сопоставления языков.-6 006532 Настоящее изобретение, таким образом, при работе анализирует строки слов, которые зависят от правильного расположения слов (в этой строке слов), и может учитывать контекст выбора слова, а также грамматические идиосинкразии, такие как порядок построения фразы, стиль или аббревиатуры. Эти ассоциации строк слов также используют для методики перевода с двойным перекрытием, которую используют в процессе перевода, описанного в настоящем описании. Важно отметить, что настоящее изобретение может работать в ситуациях, когда слово из поднабора или строку слов из большей строки слов постоянно получают, как ассоциацию для большей строки слов. Настоящее изобретение учитывает такую структуру путем изменения получаемой частоты. Например,имена собственные иногда представляют в полной форме (как, например, "John Doe"), сокращают до имени или фамилии ("John" или "Doe"), или сокращают другим способом ("Mr.Doe"). Поскольку настоящее изобретение, вероятнее всего, будет получать больше отдельных слов, чем строк слов (то есть,больше результатов для имени или фамилии, чем для полной строки слов, содержащей полное имя "JohnDoe"), и поскольку слова, которые составляют строку слов, обязательно будут подсчитаны отдельно, так же, как часть фразы, требуется использовать механизм изменения ранжирования. Например, в некотором документе имя "John Doe" может появляться сто раз, в то время как имя "John" в отдельности или как часть имени John Doe может появляться сто двадцать раз, и фамилия "Doe" отдельно или как часть полного имени John Doe может появляться сто десять раз. Нормальный перевод (в соответствии с настоящим изобретением) при анализе строки слов "John Doe" будет ранжировать имя "John" более высоко, чем фамилию "Doe", и оба этих слова более высоко, чем строку слов "John Doe". В результате вычитания количества появлений большей строки слов из количества появлений поднабора (или отдельных возвратов) может быть получено правильное упорядочение (хотя, конечно, другие способы можно использовать для получения аналогичного результата). Таким образом, путем вычитания числа сто (количество появлений"John Doe"), из ста двадцати (количество появлений слова "John"), правильный результат для имени"John" составит двадцать. В результате применения этого анализа получают сто как количество появлений строки слов "John Doe" (при анализе и переводе этой строки слов), двадцать для слова "John" и десять для строки слов "Doe", в результате чего получают правильные ассоциации. Следует отметить, что такой подход не ограничен именами собственными и часто появляется в общих фразах и во множестве различных контекстов. Например, каждый раз, когда строку слов "I love you"(Я вас люблю) переводят с использованием ее наиболее часто встречающейся ассоциации из слов на другом языке, слово - эквивалент для слова "love" (любить, любовь) на другом языке также может быть ассоциировано независимо каждый из этих случаев перевода. Кроме того, когда строку слов переводят подругому в другом анализируемом тексте, слово "love" может быть повторно ассоциировано. Это будет искажать анализ и приводить к получению слова "love" во втором языке вместо "I love you" на втором языке для перевода фразы "I love you" на первом языке. Поэтому снова отметим, что система вычитает количество появлений более крупной ассоциации слов из частоты всех ассоциаций поднаборов при ранжировании ассоциаций большей строки. Эти концепции также отражены на фигуре. Кроме того, в базе данных могут быть установлены инструкции, направленные на игнорирование общих слов, таких как "it", "an", "a", "of", "as", "in" (различные предлоги, артикли и вспомогательные слова английского языка) и тому подобное или любые общие слова при подсчете частоты ассоциации для слов и строк слов. Такой подход позволяет более точно отражать истинные значения частоты ассоциаций, которые в противном случае будут искажены в результате многократного появления общих слов, входящих в любой заданный диапазон. Это позволяет с помощью методики создания базы данных ассоциаций, в соответствии с настоящим изобретением, исключить влияние общих слов на результаты анализа без необходимости выполнения объемных вычислений, связанных с вычитанием. Следует отметить, что, если эти или любые другие общие слова "не будут удалены" из базы данных ассоциаций, они в результате могут не быть приняты как перевод, если только их учет не потребуется специально, поскольку в процессе двойного перекрытия, более подробно описанном ниже, они не будут приняты в расчет. Следует отметить, что другие расчеты для коррекции частот ассоциации можно выполнять для обеспечения точного отражения количества общих появлений слова и строк слов. Например, коррекция для исключения двойного подсчета может потребоваться в случае перекрытия диапазонов анализируемых слов. Коррекция требуется в этих случаях для получения более точных частот ассоциаций. Пример вариантов выполнения способа и устройства для создания и дополнения базы данных сопоставленных идей, в соответствии с настоящим изобретением, будет описан ниже с использованием двух документов,описанных выше в качестве примера, при этом снова создают следующую таблицу: Следует снова отметить, что хотя данный вариант выполнения фокусируется на частоте появления слова и строк слов только в одном документе, этот пример, в основном, приведен для иллюстрации. Появление слов и строк слов анализируют с использованием всего возможного Параллельного и Сопоставимого текстов в совокупности.-7 006532 При использовании двух документов, приведенных выше (А на первом языке и В на втором языке) в соответствии с методикой создания базы данных выполняют следующие этапы. Этап 1. Сначала определяют размер и расположение диапазона. Как указано выше, размер и расположение могут определяться пользователем или могут быть приблизительно оценены с использованием множества способов. Результаты подсчета слов в двух документах приблизительно равны (10 слов в документе А, 8 слов в документе В), поэтому среднюю точку диапазона устанавливают так, что она совпадает с расположением слова или строки слов в документе А. (Следует отметить, что, поскольку отношение подсчета слов между документами составляет 80%, расположение диапазона в качестве альтернативы можно установить с использованием коэффициента 4/5). В данном примере размер диапазона или значение три может обеспечить наилучшие результаты для получения приблизительной кривой нормального распределения; диапазон составит 1 вначале и конце документа, и 2 в середине. Однако,как указано выше, диапазон (или способ, используемый для определения диапазона), полностью определяется пользователем. Этап 2. Затем первое слово в документе А определяют и проверяют в документе А для определения количества появлений этого слова в документе. В данном примере первое слово в документе А представляет собой X: Х появляется три раза в документе А, в положениях 1, 4 и 9. Номера положений слова или строк слов представляют просто местоположение этого слова, или строки слова в документе по отношению к другим словам. Таким образом, номера положений соответствуют номерам слов в документе, без учета пунктуации, например, если документ содержит десять слов, и слово "king" (король) появляется дважды, номера положений слова "king" попросту представляют собой номера позиций в строке из десяти слов, в которых появляется это слово. Поскольку слово Х появляется в документе больше, чем один раз, процесс продолжается до следующего этапа. Если бы слово Х появлялось только один раз, тогда это слово было бы пропущено, и процесс продолжился бы до следующего слова, и при этом процесс создания базы данных также был бы продолжен. Этап 3. Получают возможные варианты перевода на второй язык для слова Х на первом языке в позиции 1: приложение диапазона к документу В приводит к получения слов в позициях 1 и 2 (11) в документе В: АА и ВВ (расположенные в позициях 1 и 2 в документе В). Все возможные комбинации возвращают как потенциальный перевод или соответствующие ассоциации для X: АА, ВВ, и АА ВВ (как комбинацию строк слов). Таким образом, для X1 (первое появление слова X) получают АА, ВВ и АА ВВ в качестве ассоциации. Этап 4. Анализируют следующую позицию слова X. Это слово (Х 2) появляется в позиции 4. Поскольку позиция 4 расположена близко к центру документа, диапазон (как определено выше) будет представлять собой по два слова с обеих сторон позиции 4. Возможные ассоциации получают путем поиска слова 4 в документе В и с применением диапазона 2, таким образом, получают два слова перед словом 4 и два слова после слова 4. При этом получают слова в позициях 2, 3, 4, 5 и 6. Эти позиции соответствуют словам ВВ, СС, АА, ЕЕ и FF в документе В. Просматривают все перестановки вперед этих слов(и их комбинированные строки слов). В результате, в качестве возможных ассоциаций для Х 2 получают ВВ, СС, АА, ЕЕ, FF, ВВ СС, ВВ СС АА, ВВ СС АА ЕЕ, ВВ СС АА ЕЕ FF, СС АА, СС АА ЕЕ, СС АА ЕЕFF, АА ЕЕ, АА ЕЕ FF и ЕЕ FF. Этап 5. Результаты для первых появлений Х (позиция 1) сравнивают с результатами для второго места появления Х (позиция 4) и определяют соответствие. Следует отметить, что результаты, которые включают одинаковое слово или строки слов, появляющиеся при перекрытии двух диапазонов, следует уменьшать до одного появления. Например, в данном примере слово в позиции 2 представляет собой ВВ; это слово получено как для первого места появления Х (при работе в диапазоне), так и во втором появлении Х (при работе в диапазоне). Поскольку одна и та же позиция получена как для слова X1, так и для Х 2, это слово учитывают как одно появление. Однако, если одно и то же слово получают в перекрывающемся диапазоне, но для двух различных позиций слова, тогда слово подсчитывают дважды, и записывают частоту ассоциации. В этом случае результат для слова Х будут составлять АА, поскольку слово(АА) появляется в обоих результатах ассоциации для X1 и Х 2. Следует отметить, что другое слово, которое появляется в обоих результатах ассоциации, представляет собой ВВ; однако, как описано выше, поскольку это слово находится в той же позиции (и, следовательно, представляет собой то же самое слово),полученной в результате работы в диапазоне по первому и второму местам появления X, это слово можно не учитывать. Этап 6. Анализируют следующую позицию слова Х (позиция 9) (Х 3). Применяют диапазон 1(ближе к концу документа), получают ассоциации в позициях 8, 9 и 10 документа В. Поскольку документ В имеет только 8 позиций, результат сокращают и получают только позицию 8 слова, как возможное значение для X:СС. (Следует отметить, что в качестве альтернативы, параметры, определяемые пользователем,могли бы вызывать, как минимум, два знака, как часть анализа, в результате которого могла бы быть получена позиция 8 и следующая ближайшая позиция (в которой представлено слово GG в позиции 7.-8 006532 Сравнивая результаты Х 3 с результатами X1, не находят совпадений и, таким образом, ассоциации будут отсутствовать. Этап 7. Анализируют следующую позицию слова X; однако в документе А слово Х больше не появляется. В этом пункте частоту ассоциации, равную единице (1), устанавливают для слова Х на языке А,для слова АА на языке В. Этап 8. Поскольку в документе слово Х больше не появляется, процесс увеличивают на одно слово и проверяют строку слов. В данном случае анализируемая строка слова представляет собой "X Y", первые два слова в документе А. К этой фразе применяют ту же методику, описанную на этапах 2-7. Этап 9. При просмотре документа А, можно видеть, что в нем строка слов Х Y появляется только один раз. В этом пункте процесс приращения останавливается и не происходит создание базы данных. Поскольку была достигнута конечная точка, анализируют следующее слово (этот процесс происходит всякий раз, когда для строки слов не находят соответствие); в этом случае слово в позиции 2 в документе А представляет собой "Y". Этап 10. При использовании процесса, описанного в этапах 2-7 для слова "Y", получают следующее: имеются две позиции появления слова Y (позиции 2 и 7), так что процесс создания базы данных продолжается (снова отметим, что, если слово Y появляется в документе А только один раз, тогда словоY не будет проанализировано); размер диапазона в позиции 2 составляет 1 слово; в результате применения диапазона к документу В (позиция 2 первого появления слова Y) получают результаты в позициях 1, 2 и 3 в документе В; соответствующие слова иностранного языка в этих полученных позициях представляют собой: АА,ВВ и СС; после применения перестановок вперед получают следующие возможные варианты для Y1: АА,ВВ, СС, АА ВВ, АА ВВ СС и ВВ СС; анализируют следующую позицию Y (позиция 7); размер диапазона в позиции 7 составляет 2 слова; в результате применения этого диапазона к документу В (позиция 7) получают позиции 5, 6, 7 и 8: ЕЕ, FF, GG и СС; все перестановки приводят к следующим вариантам для Y2: ЕЕ, FF, GG, СС, ЕЕ FF, ЕЕ FF GG, ЕЕ FF GG СС, FF GG, FF GG СС и GG СС; при сопоставлении с результатами для Y1 получают СС как единственное соответствие; путем комбинирования соответствий для Y1 и Y2 получают СС как частоту ассоциации для Y. Этап 11. Конец приращения диапазона: поскольку единственное возможное соответствие для словаY (слово СС) появляется в конце диапазона для первой позиции появления Y (СС появляется в позиции 3 в документе В), диапазон увеличивают на 1 при первом появлении так, что получают позиции 1, 2, 3 и 4: АА, ВВ, СС и АА; или следующие перестановки вперед: АА, ВВ, СС, АА ВВ, АА ВВ СС, АА ВВ СС АА,ВВ СС, ВВ СС АА и СС АА. При использовании этих результатов опять получают СС как возможный перевод для Y. Следует отметить, что диапазон увеличили, поскольку возвращенное соответствие находилось в конце диапазона для первого случая появления (основного появления слова "Y"); при появлении этой структуры всегда заканчивают приращение диапазона, как подэтап (или альтернативный этап),для обеспечения полноты. Этап 12. Поскольку в документе А слово "Y" больше не появляется, анализ документа А увеличивают на одно слово, и анализируют строку слов "Y Z" (следующее слово после слова Y). Переход к следующей строке (Y Z) и повторение процесса приводит к следующему: строка слов Y Z появляется дважды в документе А: позиции 2 и 7. Возможные варианты для Y Z в первом месте появления (Y Z1) представляют собой АА, ВВ, СС, АА ВВ, АА ВВ СС, ВВ СС; (следует отметить, что в качестве альтернативы параметры диапазона можно было бы определить так, чтобы они включали расширение размера диапазона по мере того, как анализируемые строки слов на языке А становятся более длинными). Возможные варианты для Y Z во втором месте появления (Y Z2) представляют собой ЕЕ, FF, GG,СС, ЕЕ FF, ЕЕ FF GG, ЕЕ FF GG СС, FF GG, FF GG СС и GG СС; сопоставление приводит к получению СС в качестве возможной ассоциации для строки слов Y Z; Расширение диапазона (конец приращения диапазона) приводит к получению следующих значений для Y Z: АА, ВВ, СС, АА ВВ, АА ВВ СС, АА ВВ СС АА, ВВ СС, ВВ СС АА и СС АА. После применения результатов опять получим СС, как частоту ассоциации для строки слов Y Z. Этап 13. Поскольку в документе А строка слов "Y Z" больше не появляется, анализ документа А увеличивают на одно слово, и производят анализ строки слов "Y Z X" (следующее слово после слова Z в позиции 3 в документе А). Приращение до следующей строки слов (Y Z X) и повторение процесса (строка слов Y Z X появляется дважды в документе А), приводит к следующему: результаты для первой позиции появления слов Y Z X расположены в позициях 2, 3, 4 и 5; перестановки представляют собой ВВ, СС, АА, ЕЕ, ВВ СС, ВВ СС АА, ВВ СС АА ЕЕ, СС АА, СС АА ЕЕ и АА ЕЕ;-9 006532 результаты для второй позиции появления слов Y Z X расположены в позициях 5, 6, 7 и 8; перестановки представляют собой ЕЕ, FF, GG, СС, ЕЕ FF, ЕЕ FF GG, ЕЕ FF GG СС, FF GG, FF GG СС и GG СС. При сравнении этих двух результатов получают СС в качестве частоты ассоциации для строки словY Z X; при этом снова можно отметить у что результат ЕЕ, в качестве возможной ассоциации не учитывают, поскольку это слово появляется в обоих случаях как одно и то же слово (то есть, в той же позиции). Этап 14. Приращение до следующей строки слов (Y Z X W) позволяет найти только одну позицию появления; поэтому создание базы данных строк слов завершается, и анализируют следующее слово: Z(позиция 3 в документе А). Этап 15. Применение этапов, описанных выше для слова Z, которое 3 раза появляется в документе А, позволяет получить следующее: результаты для Z1 представляют собой: АА, ВВ, СС, АА, ЕЕ, АА ВВ, АА ВВ СС, АА ВВ СС АА,АА ВВ СС АА ЕЕ, ВВ СС, ВВ СС АА, ВВ СС АА ЕЕ, СС АА, СС АА ЕЕ и АА ЕЕ; возвраты для Z2 представляют собой: FF, GG, СС, FF GG, FF GG СС и GG СС; после сравнения Z1 и Z2 получают СС как частоту ассоциации для Z;Z3 (позиция 10) не дает результатов в определенном диапазоне. Однако, если мы добавим к параметрам условие, что должен существовать по меньшей мере один результат для каждого слова или строки слов на языке А, результат для Z будет СС. Сравнивая результаты для Z3 и Z1, получаем СС как частоту ассоциации для слова Z. Однако эту ассоциацию не учитывают, поскольку СС в позиции 8 слова уже было учтено раньше в ассоциации дляZ2. Когда перекрывающийся диапазон приводит к двойному учету позиций появлений в процессе, система может уменьшить частоту ассоциаций для того, чтобы более точно отображать количество истинных появлений. Этап 16. При переходе к следующей строке слов получаем строку слов Z X, которая дважды появляется в документе А. Применяя этапы, описанные выше для Z X, получаем следующее: результаты для Z X1 представляют собой: ВВ, СС, АА, ЕЕ, FF, ВВ СС, ВВ СС АА, ВВ СС АА ЕЕ,ВВ СС АА ЕЕ FF, СС АА, СС АА ЕЕ, СС АА ЕЕ FF, АА ЕЕ, АА ЕЕ FF и ЕЕ FF; результаты для Z X2 представляют собой: FF, GG, СС, FF GG, FF GG СС и GG СС; при сравнении результатов получают ассоциации между строкой слов Z Х и СС. Этап 17. При следующем приращении получают фразу Z X W. Она появляется только один раз, так что анализируют следующее слово (X) в документе А. Этап 18. Слово Х было уже проанализировано в первой позиции. Однако вторая позиция слова X,по отношению к другому документу, не была проанализирована с точки зрения возможных результатов для слова X. При этом слово Х (во второй позиции) теперь исследуют как первой позиции появления слова X, далее в документе: результаты для Х в позиции 4 представляет собой: ВВ, СС, АА, ЕЕ, FF, ВВ СС, ВВ СС АА, ВВ СС АА ЕЕ, ВВ СС АА ЕЕ FF, СС АА, СС АА ЕЕ, СС АА ЕЕ FF, АА ЕЕ, АА ЕЕ FF и ЕЕ FF. Результат для Х в позиции 9 представляет: СС; сравнение результатов для позиции 9 с результатами для позиции 4 дает СС как возможное соответствие для слова Х и ему задают частоту ассоциации. Этап 19. Приращение до следующей строки слов (поскольку далее в документе Х более не появляется, для сравнения со вторым появлением X), позволяет получить строку слов XW. Однако эта строка слов не появляется более чем один раз в документе А, поэтому процесс переходит к анализу следующего слова (W). Слово "W" появляется только один раз в документе А, так что происходит переход не к следующей строке слов, поскольку слово "W" появляется только один раз, а к следующему слову в документе А - к слову "V". Слово "V" появляется только один раз в документе А, так что анализируют следующее слово (Y) . Слово "Y" не появляется ни в каких других позициях после позиции 7 в документе А,так что анализируют следующее слово (Z). Слово "Z" снова появляется после позиции 8, в позиции 10. Этап 20. Применяя описанный выше процесс ко второй позиции появления слова Z, получаем следующее: результаты для Z в позиции 8 позволяют получить: GG, СС и GG CC; результаты для Z в позиции 10 позволяют получить: CC; сравнение результатов в позиции 10 с позицией 8 не дает ассоциации для слова Z. Снова отметим, что слово CC получается как возможная ассоциация; однако, поскольку CC представляет ту же позицию слова, полученную при анализе Z в позиции 8 и Z в позиции 10, эту ассоциацию не учитывают. Этап 21. Приращение до следующего слова приводит к строке слов Z X; эта строка слов больше не появляется (в направлении вперед) в позициях в документе А, так что процесс снова начинается со следующего слова в документе А - слова "X". Слово Х больше не появляется (в направлении вперед) в позициях документа А, так что процесс начинается снова. Однако при этом был достигнут конец документа А и анализ прекращается.-10 006532 Этап 22. Конечное значение частоты ассоциаций табулируют путем комбинирования всех результатов, приведенных выше, и вычитают совпадения, как описано выше. Для получения результатов, по которым можно делать вывод, может быть недостаточно данных для слов и строк слов в документе А. Однако по мере анализа большего количества пар документов, содержащих слова и строки слов с использованием ассоциаций, описанных выше, частоты ассоциаций становятся статистически более надежными так, что слова или строки слов между Языками А и В будут формировать строгие ассоциации для возможных переводов слов и строк слов. Пример варианта выполнения способа создания базы данных, работающего совместно с компьютерной системой такого типа, как известна в данной области техники, может быть представлен следующей программой: Как показано в данной иллюстрации, такой вариант выполнения представляет используемую методику создания ассоциаций. Методика, в соответствии с настоящим изобретением, не обязательно должна быть ограничена переводом с языка. В широком смысле эту методику можно применять к любым двум формам выражения одной идеи, которые могут быть ассоциированы, поскольку, в сущности, перевод с иностранного языка просто представляет собой спаренные ассоциации одной идеи, представленной различными словами или строками слов. Таким образом, настоящее изобретение может быть применено к ассоциированным данным, звуку, музыке, видеоизображению или любой концепции в широком диапазоне, существующей в виде идеи, включая идеи, которые могут представлять любой чувственный опыт(звуковой, видимый образ, запах и т.д.). Для настоящего изобретения при этом только требуется анализировать два варианта выполнения (при переводе с языков, два варианта документов; в области музыки варианты могут представлять собой цифровые представления музыкальных партитур и частот звуков,обозначающих одни композиции и т.п.). В другом варианте выполнения определенные алгоритмы, основанные на правилах, хорошо известные в данной области техники, могут быть внедрены в изучение ассоциации представлений языков для обработки определенных классов текстов, которые в отношении контекста и значения являются, взаимо-16 006532 заменяемыми (и иногда могут иметь потенциально бесконечное количество вариантов словообразования) такие как имена, числа и даты. Кроме того, если доступные документы сопоставляемых языков не позволяют получить статистически значимые результаты для перевода, пользователи могут исследовать возможные варианты для переводов и другие ассоциации и одобрять, а также ранжировать соответствующие варианты выборов. Как описано выше, частоты ассоциации становятся более сильными между словами и строками слов, по мере увеличения количества анализируемых документов, представленных в виде переведенных пар для определения частот ассоциации. По мере того как исследуют все большее количество документов на разных языках, способ и устройство, в соответствии с настоящим изобретением, начинает заполнять "выведенные ассоциации" между парами языков на основе тех языков, которые имеют общие ассоциации с третьим языком, но не имеют ассоциации непосредственно друг с другом, кроме того, когда переведенные документы существуют на множестве языков, результаты для общих ассоциаций могут быть проанализированы с использованием нескольких языков, до тех пор, пока между всеми ними не будет найдена общая ассоциация, которая является переводом. Ниже приведен пример компьютерной программы, которая (при работе с компьютерной системой известного в данной области техники типа) обеспечивает способ, в котором данные на этих языках используют в вариантах выполнения настоящего изобретения: Выведенные ассоциации могут быть получены между текстом на паре языков, когда текст на этих языках имеет общие определения на третьем языке или языках. Текст может представлять собой часть или сегмент переводимого документа, например слова или фразы. Например, если недостаточно текста на сопоставляемых языках для непосредственного перевода фразы на языке А "аа dd pz" в фразу на языке В, вывод ассоциации может включать сравнение этой фразы на языке А с переводом фразы на языки С,D, Е и F, для которых существует текст достаточного объема на сопоставимых языках, для получения перевода, показанного в табл. 1. Затем переводы "аа dd pz" на языки С, D, Е и F могут быть переведены на язык В, если существует текст достаточного объема на сопоставимых языках, для получения этих переводов, как показано в табл. 2. Вывод ассоциации между фразой "аа dd АА pz" на языке А и фразой на языке В дополнительно включает сравнение фраз на языке В, которые были переведены при переводе с языков С, D, Е и F фразы "аа dd pz". Некоторые фразы на языке В, которые были переведены при переводе с языков С, D, Е и F фразы "аа dd pz", могут быть идентичными и, в данном предпочтительном варианте выполнения настоящего изобретения они будут представлять правильный перевод на язык В фразы-17 006532 идентичные фразы на языке В, "UyTByM". Таким образом, выведенные ассоциации могут быть созданы между фразой на языке А и ее правильным переводом на язык В. В результате перевода с языка Е на язык В получают неидентичную фразу ZnVPiO на языке В. Это может указывать на то, что фраза "153" на языке Е имеет более одного значения, или что фразы UyTByM и ZnVPiO на языке В являются взаимозаменяемыми. Таблица 1 В другом варианте выполнения точность существующих систем перевода, известных в данной области техники, может быть улучшена путем использования способа и устройства в соответствии с настоящим изобретением, описанных выше. Существующие системы перевода позволяют получить результат для перевода с языка А на язык В; этот результат можно сравнивать с результатами перевода (с использованием систем и устройств известного уровня техники) с языка А на другие языки (например,языки С, D, Е и F) и, впоследствии их переводов на язык В, с использованием систем и устройств известного уровня техники. При использовании способа и устройства, в соответствии с настоящим изобретением, получаемые в результате общие части переводов между различными результатами перевода на язык В, можно сравнивать с получением более точного перевода. Поскольку каждый сегмент запроса на перевод имеет минимальное определяемое пользователем число (по меньшей мере два) одинаковых результатов перевода на язык В, вся фраза может быть переведена точно. Если любая часть перевода не будет проверена с использованием определенного пользователем минимального количества различных переводов на целевой язык, нерешенные участки могут быть выделены для пользователя. При этом, благодаря применению многоязычного механизма перевода с использованием различных пар языков, точность конечного продукта может быть существенно улучшена, и оставшиеся не переведенными части могут быть определенным образом идентифицированы. Пример вариантов выполнения настоящего изобретения и его использования с любым набором механизмов перевода состоит в следующем (в этом примере показан перевод фразы "zz pd lz nz ki xo" с языка А на язык В). В начале в соответствии с настоящим изобретением переводят фразу непосредственно с языка А на язык В с использованием любой существующей системы перевода, и результат сохраняют для дальнейшей обработки. Во-вторых, в соответствии с настоящим изобретением переводят фразу с языка А на другие языки(в данном примере используют языки С, D, Е и F). Таким образом, при использовании существующих систем перевода, известную фразу на языке А переводят на язык С, известную фразу на языке А переводят на язык D, известную фразу на языке А переводят на язык Е, и известную фразу на языке А переводят на язык F. Можно использовать разные системы и способы перевода для переводов на разные языки; то есть, одно и то же устройство или система перевода не обязательно должны быть использованы для перевода с языка А на языки В, С, D, Е и F. Результаты каждого из этих переводов с языка А записывают для последующей обработки. В-третьих, результаты выполненных выше операций используют для перевода фразы с языков (в данном варианте выполнения с языков С, D, Е и F) на язык В. При использовании существующих устройств и систем перевода известного уровня техники, полученный в результате перевод фразы на языке С (то есть, результат перевода с языка А на язык С, полученный и записанный как описано выше) переводят на язык В с использованием системы или устройства перевода, известных в данной области техники. И снова, в настоящем изобретении нет необходимости использовать идентичную систему перевода,известную в данном уровне техники, для перевода фразы с языка А на язык С, чтобы также перевести-18 006532 полученную в результате фразу с языка С на язык В. Например, перевод фразы с языка А на язык С может быть выполнен с использованием устройства Х перевода, в то время как перевод фразы с языка С(полученной в результате использования устройства X) на язык В может быть выполнен с использованием устройства Y перевода. Полученный в результате перевод (с языка С на язык В) записывают для последующей обработки. Процесс продолжают с использованием результатов перевода фразы с языка А на другие языки, для получения перевода этой фразы на язык В. Таким образом, используя существующие устройства и системы перевода известного уровня техники, полученный в результате перевод фразы на язык D (то есть,результат перевода с языка А на язык D, полученный и записанный, как описано выше) переводят на язык В с использованием системы перевода или устройства, известных в данной области техники; перевод фразы на языке Е, полученный и записанный в результате выполнения описанных выше операций,переводят на язык В, и, наконец, перевод фразы на языке F, полученный и записанный в результате выполнения описанных выше операций, переводят на язык В. Вышеописанные этапы представлены в следующих табл. 3 и 4 для перевода фразы "zz pd lz nz kixo" с языка А (известный) на язык В (целевой), с использованием известных систем перевода на различные языки. Таблица 3-19 006532 При сравнении результатов непосредственного перевода с языка В и четырех опосредованных переводов на язык В, для сегментов, в которых существует более чем одно совпадение в переводах, больше вероятность, что они являются точным переводом. Каждый следующий 1 общий результат перевода после двух дает еще более высокую вероятность точности результатов:"ZwI" подтверждается в результате непосредственного перевода с А, С, D и F"PzO" подтверждается в результате непосредственного перевода с А, С, D и Е"KrL" подтверждается в результате непосредственного перевода с А, С и Е"IoR" подтверждается в результате непосредственного перевода с А и F При использовании описанного выше процесса получают результат в виде перевода, который должен представлять собой "ZwI LoL PzO KrL IoR". Количество языков, используемых в средстве многоязычной обработки, используемое с другими механизмами перевода, определяется пользователем. Чем больше опосредованных переводов с использованием других языков используется для проверки правильных переводов строк слов или любого другого сегмента данных, тем больше будет статистическая определенность, что при использовании настоящего изобретения будет получен точный перевод. Кроме того, в другом варианте выполнения, при сравнении между переводами с множества языков, в систему может быть добавлен тезаурус для проверки, не являются ли синонимами некоторые из несоответствующих сегментов, и в этом случае один из синонимов может быть определен или выделен как соответствующий синониму. Если выражениям в существующих состояниях искусственно придают определенные ассоциации с пунктами данных в другом состоянии и каталогизируют в базе данных, между этими двумя состояниями становятся возможными преобразования. Например, если каждой "идее", представленной в форме, состоянии или на определенном языке, назначают ассоциацию в форме электромагнитной волны (тона),будет создано "электромагнитное представление" идеи. После того, как определенное количество идей будет закодировано с использованием соответствующих электромагнитных представлений, данные (в форме идеи) могут быть переведены в форму электромагнитных волн и могут быть немедленно переданы с использованием обычной инфраструктуры передачи данных. Когда электромагнитные волны поступают в устройство назначения, это устройство будет синтезировать волны в виде отдельных компонентов и, с учетом ассоциаций (вместе с инструкциями по упорядочению, с использованием техники двойного перекрытия, описанной в настоящем изобретении, и/или других возможных способов), отображать отдельные идеи, которые были оформлены в виде электромагнитных представлений. 2. Способ и устройство преобразования идеи. В другом аспекте настоящее изобретение направлено на получение способа и устройства, предназначенных для создания второго документа, содержащего данные во втором состоянии, форме или на втором языке, из первого документа, содержащего данные в первом состоянии, форме или на первом языке, с получением конечного результата, в котором первый и второй документы представляют, по существу, одинаковые идеи или информацию, и в котором способ и устройство включают использование базы данных ассоциаций сопоставленных идей. При этом для всех вариантов выполнения способа перевода используют технику двойного перекрытия, для получения точного перевода идей из одного состояния в другое. В отличие от этого, устройства перевода известного уровня техники фокусируются на переводе отдельного слова или используют специальные коды, основанные на правилах для облегчения перевода с первого языка на второй язык. Настоящее изобретение, с использованием техники перекрытия, позволяет органически соединять слова и строки слов на втором языке так, что получают точные переводы в их правильном контексте, причем эти слова и фразы будут записаны на втором языке. В варианте выполнения настоящего изобретения способ для создания базы данных и методику перекрытия комбинируют для обеспечения точного перевода на язык. Языки могут представлять собой любой тип преобразования и не обязательно ограничиваются разговорными/письменными языками. Например, преобразование может включать компьютерные языки, определенные коды данных, такие как Код ASCII (американский стандартный код для обмена информацией) и т.п. база данных является динамической; то есть, база данных растет по мере ввода содержания в систему перевода с последующими итерациями в системе перевода с использованием содержания, введенного в предыдущее время. В предпочтительном варианте выполнения настоящего изобретения используют компьютерное устройство, такое как система персонального компьютера, такого типа, который непосредственно доступен в известном уровне техники. Однако в системе не обязательно требуется использовать такое компьютерное устройство и она может быть легко выполнена с использованием других средств, включая создание вручную базы данных и способов перевода. В настоящем изобретении можно использовать общую компьютерную систему, содержащую, по меньшей мере, средство отображения, способ ввода и способ вывода и процессор. В качестве средства отображения можно использовать любое средство, доступное в известном уровне техники, такое как терминалы на основе электронно-лучевой трубки, дисплеи на жидких кристаллах, дисплеи на основе плоских панелей и т.п. В качестве средства процессора также можно использовать любое из доступных и используемых в вычислительной среде средств, такое как средство, поставляемое для обеспечения рабо-20 006532 ты компьютера, используемого для выполнения настоящего изобретения. Наконец, способ ввода используют для обеспечения возможности ввода документов для построения базы данных сопоставленных ассоциаций; как описано выше, конкретный способ ввода для преобразования в цифровую форму может изменяться в зависимости от требований пользователя. а. Создание базы данных вручную и получение перевода с использованием техники двойного перекрытия. Ниже будет описан пример вариантов выполнения способа и устройства для перевода документа с первого языка на второй язык, в соответствии с настоящим изобретением, в котором разрабатывают базу данных сопоставленных языков на основе запроса пользователя на перевод слов и строк слов, а также для автоматического генерирования переводов сегмента с использованием техники двойного перекрытия. Описание предпочтительных вариантов выполнения будет приведено на примере, в котором данные на английском языке переводят в данные на иврите. Выбор этих языков предназначен только для описания и не означает ограничение выбора первым и вторым языками. В соответствии с предпочтительным вариантом выполнения настоящего изобретения, компьютерная система работает по созданию базы данных ассоциаций между переводами с английского языка на иврит. Способ перевода включает, по меньшей мере, следующие этапы. Вначале данные на английском языке вводят в компьютерную систему. Во-вторых, все введенные слова на английском языке вначале анализируют слово за словом. Из базы данных получают известные переводы слов на иврит. Если перевод слов не включен в базу данных,тогда компьютерная система выполняет запрос пользователя для ввода соответствующего перевода. Таким образом, если в базе данных не содержится эквивалент на иврите для введенного английского слова,компьютер просит пользователя предоставить соответствующий эквивалент на иврите. Пользователь затем получает перевод и вводит указанный перевод в базу данных. При последующем использовании компьютерная система будет так работать с базой данных, что перевод будет получен на основе введенного ранее пользователем значения. Таким образом, на втором этапе выполняют анализ введенных данных в проанализированном состоянии, то есть, дословно, и соответствующие переводы получают (путем работы с базой данных) или вводят в базу данных. В-третьих, введенные данные проверяют с увеличением анализируемых сегментов. Например, если данные вначале анализировали дословно, то в соответствии со способом перевода настоящего изобретения затем анализируют введенные данные путем оценки строк из двух слов. И снова, аналогично приведенному выше описанию, из базы данных получают переводы строк из двух слов, если такие известны; если такие неизвестны, система перевода просит пользователя ввести соответствующий перевод для всех возможных строк из двух слов. Все перекрывающиеся сегменты из двух слов затем записывают в базу данных. Например, если строка слов состоит из четырех слов, тогда базу данных проверяют на наличие приведенных комбинаций: 1,2, 2,3 и 3,4. Если такие комбинации отсутствуют, система посылает запрос пользователю. Следует отметить, что только определенным образом закодированные переводы строк из двух слов будут возвращены как правильные переводы, даже при том, что база данных будет обязательно содержать определение каждого слова после выполнения приведенного выше второго этапа. В-четвертых, если переводы на иврит двух перекрывающихся строк из двух слов на английском языке содержат перекрывающееся слово (или слова), система работает так, что она комбинирует взаимно перекрывающиеся сегменты. Избыточные сегменты на иврите устраняют в области перекрытия для получения соответствующего перевода строки из трех слов на английском языке, который получают путем комбинирования двух взаимно перекрывающихся строк на английском языке (с последующим удалением избыточности на перекрывающихся участках на английском языке). Вышеприведенные этапы повторяют, начиная с 1 этапа, повторяя неопределенное количество этапов (n) так, что получают соответствующий перевод. Способ перевода работает автоматически путем проверки соответствующих согласующихся строк, которые соединяют кодированные блоки слов на обоих языках с использованием взаимного перекрытия. Такие автоматические подтверждения перекрывающихся мостиков, согласующихся между обоими языками, создают языковую сеть, которая обеспечивает перевод с одного языка на второй с идеальной точностью, как только база данных достигает критической массы. В качестве примера рассмотрим фразу на английском языке "I want to buy a car" (Я хочу купить машину). После работы способа, в соответствии с настоящим изобретением, эта фраза будет введена в компьютер, на котором установлена база данных. Компьютер при работе определяет, содержит ли база данных эквиваленты на иврите для следующих слов: "I", "want", "to", "buy", "а" и "car". Если такие эквиваленты известны, компьютер выводит эти эквиваленты на иврите. Если такие эквиваленты не известны,компьютер просит пользователя ввести соответствующий перевод на иврит, и записывает такой перевод для использования в будущем. Затем компьютер анализирует предложение, используя сегменты из двух слов с перекрытием: "I want", "want to", "to buy", "buy а" и "a car". Компьютер при работе получает эквиваленты на иврите этих сегментов (то есть, эквиваленты на иврите для словосочетания "I want" и т.д.); если такие эквиваленты на иврите не известны, тогда компьютер просит пользователя ввести соответствующие переводы на иврит, и записывает такие переводы для использования в будущем.-21 006532 В соответствии с настоящим изобретением затем анализируют сегменты из трех слов, "I want to","want to buy", "to buy a", и "buy a car". В этом пункте процесс, в соответствии с настоящим изобретением,делает попытку комбинировать каждую пару переводов на иврит для тех переводов английских словосочетаний из двух слов, которые перекрываются и комбинирует их для того, чтобы сделать запрос на переводы каждого из трех английских слов (например, "I want", и "I want to" комбинируют с формированием,"I want to"). Если сегменты на иврите имеют общее перекрытие, которое также соединяет их, способ перевода автоматически подтверждает строки слов, содержащие три английских слова на иврите, как перевод, без какого-либо вмешательства пользователя. Если сегменты на иврите не содержат перекрытия и не комбинируются, устройство просит пользователя предоставить точный перевод. После соответствующего количества попыток перевода строк из трех английских слов, процесс продолжается со строками из четырех слов и так далее, с попыткой автоматического получения, с использованием перекрытия сопоставляемых языков, комбинаций переводов, до тех пор, пока анализируемый сегмент не будет полным (в данном случае вся фраза "I want to buy a car"). По способу, в соответствии с настоящим изобретением, в результате такого анализа затем выполняют сравнение полученных эквивалентов перевода, устраняют избыточность в перекрывающихся сегментах и выводят переведенную фразу пользователю.b. Перевод документа с использованием базы данных ассоциаций и техники двойного перекрытия. Другой предпочтительный вариант выполнения настоящего изобретения позволяет переводить документ на первом языке в документ на втором языке путем использования базы данных сопоставляемых языков, как описано выше, для получения перевода слов и строк слов в документе, с последующим комбинированием перекрывающихся строк слов на втором языке для получения перевода документа с использованием описанной выше методики двойного перекрытия сопоставляемых языков. Например, рассмотрим базу данных, имеющую доступ к достаточному количеству документов на сопоставляемых языках, для получения перевода компонентов следующего предложения, вводимого на английском языке,которое должно быть переведено на иврит: "In addition to my need to be loved by all the girls in town, I always wanted to be known as the best player to ever play on the New York state basketball team." ("Кроме того,что я хотел, чтобы меня любили все девушки в городе, я всегда хотел, чтобы меня знали как лучшего игрока баскетбольной команды штата Нью-Йорк"). Кроме использования описанного выше процесса, способ манипуляции может определить, что фраза "In addition to my need to be loved by all the girl" представляет собой самую большую строку слов в документе источника, начинающегося с первого слова документа источника и находящуюся в базе данных. Она ассоциирована в базе данных со строкой слов на иврите "benosaf ltzorech sheli lihiot ahuv al yeday kolhabahurot". Процесс с использованием описанного выше способа затем будет определять следующие переводы, то есть самая большая строка на английском языке из переводимого текста (и существующая в базе данных) с одним словом (или в качестве альтернативы, с большим количеством слов) перекрывается с ранее идентифицированной строкой слов на английском языке, и двумя переводами на иврит для этих перекрывающихся строк слов на английском языке, также имеющих перекрывающиеся сегменты: "lovedhakadursal shel medinat new york". После получения таких результатов из базы данных включают манипуляцию так, чтобы сравнить перекрывающиеся слова и строки слов и для удаления избыточности. Таким образом, фраза "In additionto my need to be loved by all the girls" будет переведена как "benosaf ltzorech sheli lihiot ahuv al yeday kolhabahurot"; и "loved by all the girls in town" будет переведена как "ahuv al yeday kol habahurot buir". При использовании методики, в соответствии с настоящим изобретением, система будет отбирать сегменты на английском языке "In addition to my need to be loved by all the girls" и "loved by all the girls in town" и будет получать сегменты на иврите "benosaf ltzorech sheli lihiot ahuv al yeday kol habahurot" и "ahuv alyeday kol habahurot buir" и будет определять перекрытие. На английском языке фразы представляют собой: "In addition to my need to be loved by all the girls" и"loved by all the girls in town". После удаления перекрытия получим: "In addition to my need to be loved byall the girls in town". На иврите фразы будут представлять собой: "benosaf ltzorech sheli lihiot ahuv al yeday kol habahurot" и "ahuv al yeday kol habahurot buir". После удаления перекрытия получим: "benosaf ltzorech sheli lihiotahuv al yeday kol habahurot buir". При использовании настоящего изобретения затем выполняют анализ следующего сегмента для продолжения процесса. В данном примере процесс манипуляции выполняют в отношении фразы "thegirls in town, I always wanted to be known". Система анализирует английский сегмент "In addition to myneed to be loved by all the girls in town" с новым набором английских слов "the girls in town, I always wantedto be known". Соответствующие наборы слова на иврите будут представлять собой "benosaf ltzorech sheli lihiotahuv al yeday kol habahurot buir" и соответствующий набор слов на иврите "habahurot buir, tamid ratzity lihiotyahua". После удаления перекрытия получают следующую английскую фразу: "In addition to my need to beaddition to my need to be loved by all the girls in town, I always wanted to be known". На иврите процесс перекрытия будет действовать следующим образом: "benosaf ltzorech sheli lihiotltzorech sheli lihiot ahuv al yeday kol habahurot buir, tamid ratzity lihiot yahua". Работа такого рода в соответствии с настоящим изобретением продолжается с остальными словами и строками слов в переводимом документе. Таким образом, в примере в соответствии с предпочтительным вариантом выполнения, следующие строки английских слов будут представлять собой "In addition tothe best player". Перевод на иврит, полученный с использованием базы данных для этих фраз, будет представлять собой: "benosaf ltzorech sheli lihiot ahuv al yeday kol habahurot buir, tamid ratzity lihiot yahua" и"tamid ratzity lihiot yahua bettor hasahkan hachi tov". После удаления перекрытия на английском языке будет получено: "In addition to my need to be loved by all the girls in town, I always wanted to be known as thebest player". После удаления перекрытия на иврите будет получено: "benosaf ltzorech sheli lihiot ahuv alyeday kol habahurot buir, tamid ratzity lihiot yahua bettor hasahkan hachi tov". Продолжение процесса: будут рассмотрены следующие строки слов: "In addition to my need to bethe New York state basketball team". Соответствующие фразы на иврите будут представлять собой: "benosaf ltzorech sheli lihiot ahuv al yeday kol habahurot buir, tamid ratzity lihiot yahua bettor hasahkan hachi tov" и"hasahkan hachi tov sh hay paam sihek bekvutzat hakadursal shel medinat new york". После удаления перекрытия на английском языке будет получено: " In addition to my need to be loved by all the girls in town, Ialways wanted to be known as the best player to ever play on the New York state basketball team". После удаления перекрытия на иврите будет получено: "benosaf ltzorech sheli lihiot ahuv al yeday kol habahurot buir,tamid ratzity lihiot yahua bettor hasahkan hachi tov sh hay paam sihek bekvutzat hakadursal shel medinat newyork", что представляет собой перевод текста, который требовалось получить. После окончания этого процесса в соответствии с настоящим изобретением получают конечный переведенный текст и выводят этот текст. Следует отметить, что полученные результаты представляют собой конечный результат с использованием базы данных, с помощью которой получают перекрывающиеся ассоциации в соответствии с описанным выше процессом. Система с использованием процесса не будет, в конечном счете, принимать результат на втором языке, который не содержит естественно соответствующие друг другу связи с непрерывными сегментами на втором языке, получаемые с использованием перекрытия. Если бы какойлибо из результатов на иврите не имел точное перекрытие с непрерывными ассоциациями строк слов на иврите, он был бы отброшен и заменен ассоциациями строк слов на иврите, которые перекрываются с получением непрерывной строки слов на иврите. В примере предпочтительного варианта выполнения настоящего изобретения используется следующая компьютерная программа, работающая совместно с компьютерной системой такого типа, как известна в данной области техники:
МПК / Метки
МПК: G10L 15/02, G06F 17/28
Метки: данных, создания, базы, система, способ, многоязычной
Код ссылки
<a href="https://eas.patents.su/30-6532-sistema-i-sposob-sozdaniya-mnogoyazychnojj-bazy-dannyh.html" rel="bookmark" title="База патентов Евразийского Союза">Система и способ создания многоязычной базы данных</a>
Способ сокращения объема памяти, требуемого базой данных для хранения данных, и создания базы данных

Номер патента: 1826
Опубликовано: 27.08.2001
Автор: Эль-Газзар Амин
МПК: G06F 17/30
Метки: хранения, базы, требуемого, данных, объема, памяти, сокращения, способ, базой, создания
Формула / Реферат:
1. Способ сокращения объема памяти, требуемого базой данных для хранения информации, отличающийся тем, что - сохраняемые единицы информации распределяют по точкам пересечения строк и столбцов, по меньшей мере, двумерной растровой матрицы, - размещенным в растровой матрице единицам информации присваивают индивидуальные координаты цвета и - сформированную таким путем матрицу изображения сохраняют в качестве базы данных или части базы данных. 2....
Способ и система для обновления удаленной базы данных

Номер патента: 6045
Опубликовано: 25.08.2005
Авторы: Макмиллен Брэдли Томас, Хауорт Уилльям Фредерик Мл., Бэлоу Аристотель Николас
МПК: G06F 17/00
Метки: базы, удаленной, способ, данных, обновления, система
Формула / Реферат:
1. Способ обновления удаленной базы данных через сеть, включающий формирование множества периодических обновлений, основанных на добавочных изменениях в локальной базе данных, причем каждое из множества периодических обновлений содержит по меньшей мере одну транзакцию, передачу множества периодических обновлений в удаленную базу данных через сеть и, при формировании множества периодических обновлений, формирование инициализирующего обновления,...
Способ и система для проверки достоверности удалённой базы данных

Номер патента: 6223
Опубликовано: 27.10.2005
Авторы: Бэлоу Аристотель Николас, Макмиллен Брэдли Томас
МПК: G06F 17/00
Метки: базы, система, способ, удалённой, проверки, данных, достоверности
Формула / Реферат:
1. Способ проверки достоверности обновления для записи в удаленной базе данных, осуществляемого через сеть, причем обновление содержит по меньшей мере одно событие, включающий в себя сравнение записи в удаленной базе данных с соответствующей записью в локальной базе данных, формирование исключения, описывающего расхождение между записью удаленной базы данных и записью локальной базы данных, для каждого расхождения, сопоставление каждому...
Система и способ обновления удаленной базы данных в сети

Номер патента: 3156
Опубликовано: 27.02.2003
Авторы: Вилльямс Мэтт О., Квинлэн Син М., Нг Мэсон, Ченг Мартин Мл., Зу Дзинг, Риггинс Марк Д., Мендез Даниэль Дж., Руан Том
МПК: G06F 17/30
Метки: система, обновления, сети, удаленной, способ, данных, базы
Формула / Реферат:
1. Способ с использованием компьютера, включающий этапы, при которых с использованием программы навигации и просмотра информации (браузера) получают идентификатор загружаемой программы из компьютерной сети, инициируют исполнение загружаемой программы, получают информацию, в которой указаны данные рабочей среды, которые должны быть синхронизированы, и указан режим синхронизации, с использованием загружаемой программы выдают команду персональному...
Создание базы данных связей между понятиями

Номер патента: 6182
Опубликовано: 27.10.2005
Автор: Абир Эли
МПК: G06F 17/28
Метки: понятиями, базы, создание, между, связей, данных
Формула / Реферат:
1. Способ установления связей для содержимого, содержащий следующие этапы: принимают содержимое, выраженное в первом состоянии; принимают содержимое, выраженное во втором состоянии; анализируют указанное содержимое, выраженное в указанном первом состоянии с указанным содержимым, выраженным в упомянутом втором состоянии, при этом в указанном анализе используют разделение указанного содержимого, выраженного в первом состоянии, на по меньшей мере...
Предыдущий патент: Способ почвенной и топографической сьёмки
Следующий патент: Порошковый ингалятор
Случайный патент: Способ индуцирования у растительной клетки или растения устойчивости к вирусу, растение и растительная клетка, обладающие такой устойчивостью