Способ и система ввода данных для интерфейса




















Формула / Реферат
1. Способ интерфейса для ввода данных, содержащий
обнаружение ввода относительно интерфейса, в котором обнаружение ввода содержит обнаружение нажатия в первой зоне ряда зон, в которой по меньшей мере один ряд зон не является примыкающим по меньшей мере к одному другому ряду зон и по меньшей мере один из ряда зон отличается по форме по меньшей мере от одного другого ряда зон;
обнаружение освобождения во второй зоне ряда зон и обнаружение движения между нажатием и освобождением, в котором обнаружение движения дополнительно включает обнаружение входа или выхода одного или нескольких рядов зон между нажатием в первой зоне и освобождением во второй зоне, при поддержании контакта с интерфейсом между нажатием в первой зоне и освобождением во второй зоне; и
установление связи семантического значения с вводом, основанным на ряде семантических значений, связанных с первой зоной, в котором семантическое значение выбрано из ряда семантических значений, связанных с первой зоной, основанной на второй зоне.
2. Способ по п.1, в котором связь семантического значения с вводом включает
группирование каждого из ряда зон в один из рядов зон выбора, в котором каждый ряд зон выбора связан с соответствующим рядом семантических значений, связанных с первой зоной; и
определение, с каким из рядов зон выбора связана вторая зона.
3. Способ по п.2, в котором каждый ряд семантических значений отображен на интерфейсе в связи с первой зоной, в котором каждый ряд семантических значений отображен на соответствующем месте первой зоны и каждый из ряд зон выбора связан одним из соответствующих мест.
4. Способ по п.1, в котором ряд зон содержит ряд межклавишных зон и ряд клавишных зон, в котором никакие две клавишные зоны не являются смежными и каждая клавишная зона является смежной по меньшей мере с одной межклавишной зоной ряда зон.
5. Способ по п.4, в котором ряд зон выполнен в виде набора рядов.
6. Способ по п.5, в котором набор рядов формирует по меньшей мере одну концентрическую кривую.
7. Способ по п.6, в котором каждый ряд имеет клавишную зону на каждом конце и имеет межклавишную зону рядом с каждой клавишной зоной в ряду.
8. Способ по п.7, в котором каждая межклавишная зона перекрывает по меньшей мере две соседние клавишные зоны, к которым она примыкает.
9. Способ по п.8, в котором каждая часть каждой межклавишной зоны связана по меньшей мере с одной из двух соседних клавишных зон, к которым она примыкает.
10. Способ по п.9, в котором указанная связь основана на движении.
11. Способ по п.1, дополнительно включающий формирование дискретного сообщения, содержащего первую зону, соответствующую начальному нажатию, и вторую зону, соответствующую освобождению.
12. Способ по п.11, в котором связь семантического значения основана на дискретном сообщении.
13. Система интерфейса для ввода данных, содержащая
датчик, имеющий ряд зон, в котором по меньшей мере один из рядов зон не примыкает по меньшей мере к одному из другого ряда зон и по меньшей мере один из рядов зон отличается по форме по меньшей мере от одного другого ряда зон, при этом датчик выполнен с возможностью обнаружения ввода относительно интерфейса, в котором обнаружение ввода включает обнаружение нажатия в первой зоне ряда зон, обнаружение освобождения во второй зоне ряда зон и обнаружение движения между нажатием и освобождением, причем обнаружение движения дополнительно включает обнаружение входа или выхода из одного или большего количества рядов зон между нажатием в первой зоне и освобождением во второй зоне, при этом поддерживается контакт с интерфейсом между нажатием в первой зоне и освобождением во второй зоне; и
логический модуль, служащий для связи семантического значения с вводом, на основе ряда семантических значений, связанных с первой зоной, в котором семантическое значение выбрано из ряда семантических значений, связанных с первой зоной, основанной на второй зоне.
14. Система по п.13, в которой связь семантического значения с вводом включает
группирование каждого ряда зон в один из ряда зон выбора, в котором каждый ряд зон выбора связан с соответствующим рядом семантических значений, связанных с первой зоной; и
определение, с каким рядом зон выбора связана вторая зона.
15. Система по п.14, в которой каждый ряд семантических значений отображен на интерфейсе в связи с первой зоной, в которой каждый ряд семантических значений отображен на соответствующем месте первой зоны и каждый ряд зон выбора соответствует одному из соответствующих мест.
16. Система по п.13, в которой ряд зон содержит ряд межклавишных зон и ряд клавишных зон, в которой никакие две клавишные зоны не являются смежными и каждая клавишная зона является смежной по меньшей мере с одной межклавишной зоной.
17. Система по п.16, в которой ряд зон выполнен в ряде набора рядов.
18. Система по п.17, в которой набор рядов формирует по меньшей мере одну концентрическую кривую.
19. Система по п.18, в которой каждый ряд имеет клавишную зону на каждом конце и имеет межклавишную зону рядом с каждой клавишной зоной в ряду.
20. Система по п.19, в которой каждая клавишная зона перекрывает по меньшей мере две соседние клавишные зоны, к которым она примыкает.
21. Система по п.20, в которой каждая часть каждой межклавишной зоны связана по меньшей мере с одной из двух соседних клавишных зон, к которым она примыкает.
22. Система по п.21, в которой указанная связь основана на движении.
23. Система по п.13, в которой логический модуль служит для формирования дискретного сообщения, содержащего первую зону, соответствующую начальному нажатию, и вторую зону, соответствующую освобождению.
24. Система по п.23, в которой логический модуль служит для связи семантического значения с дискретным сообщением.

Текст
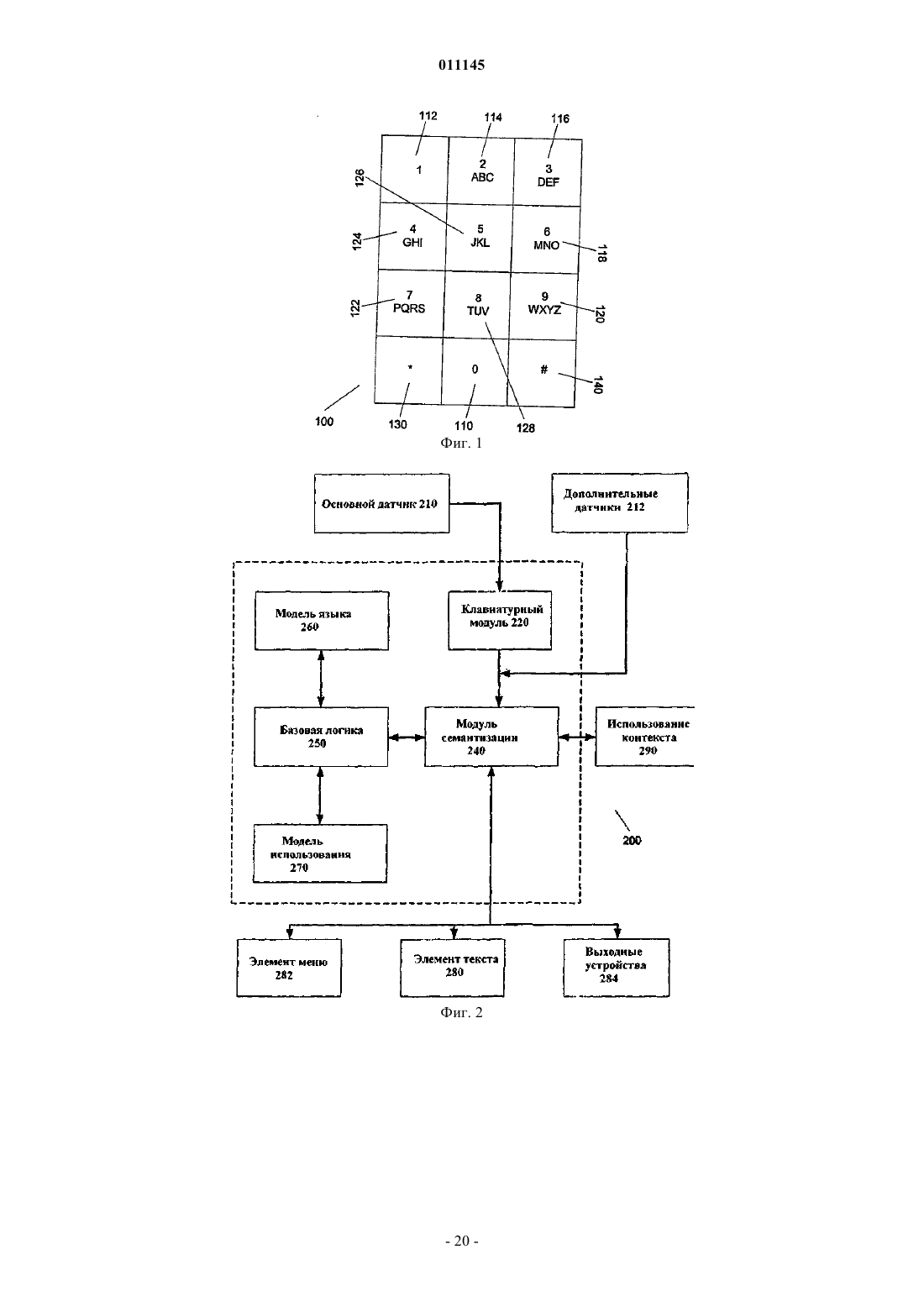
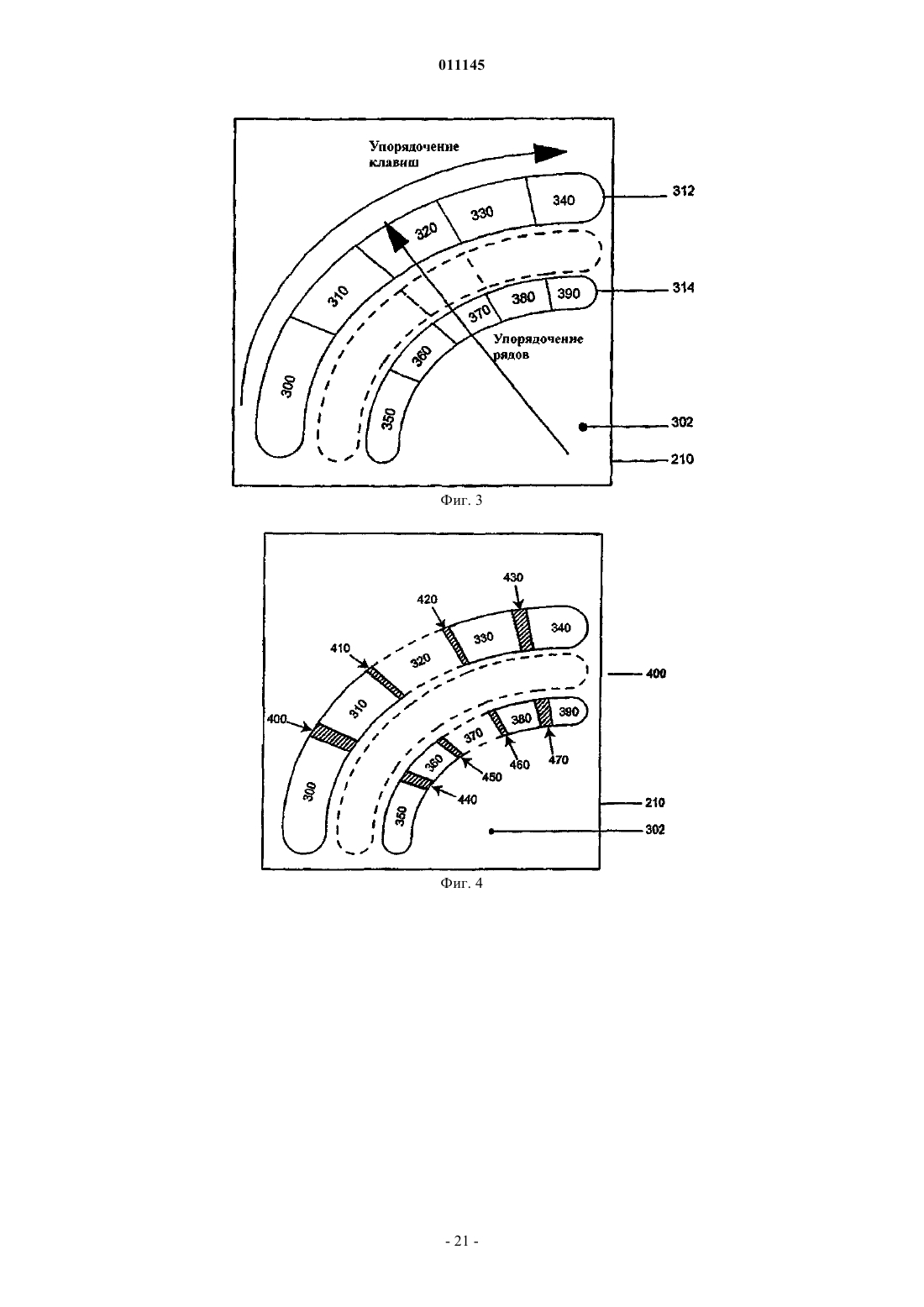
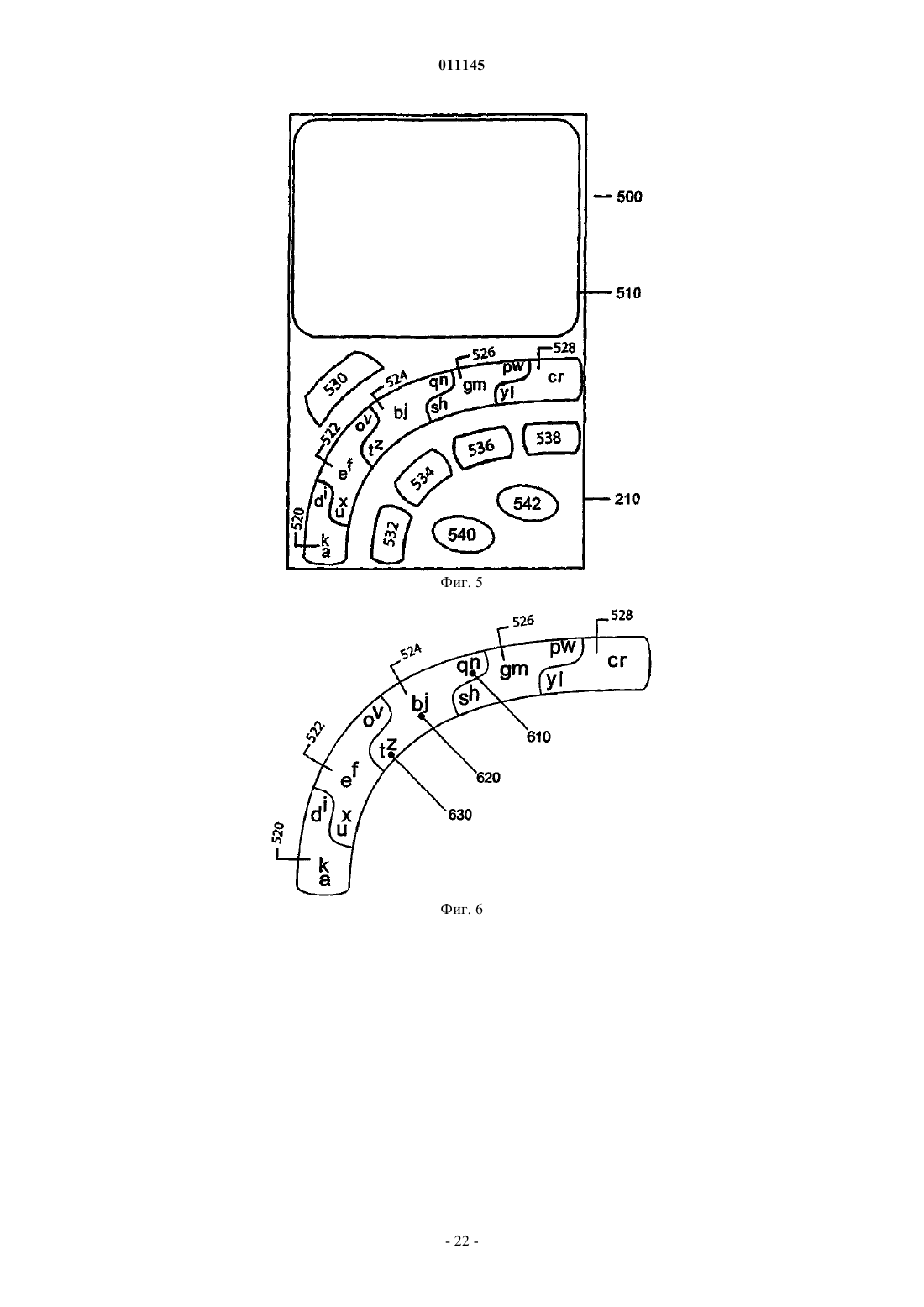
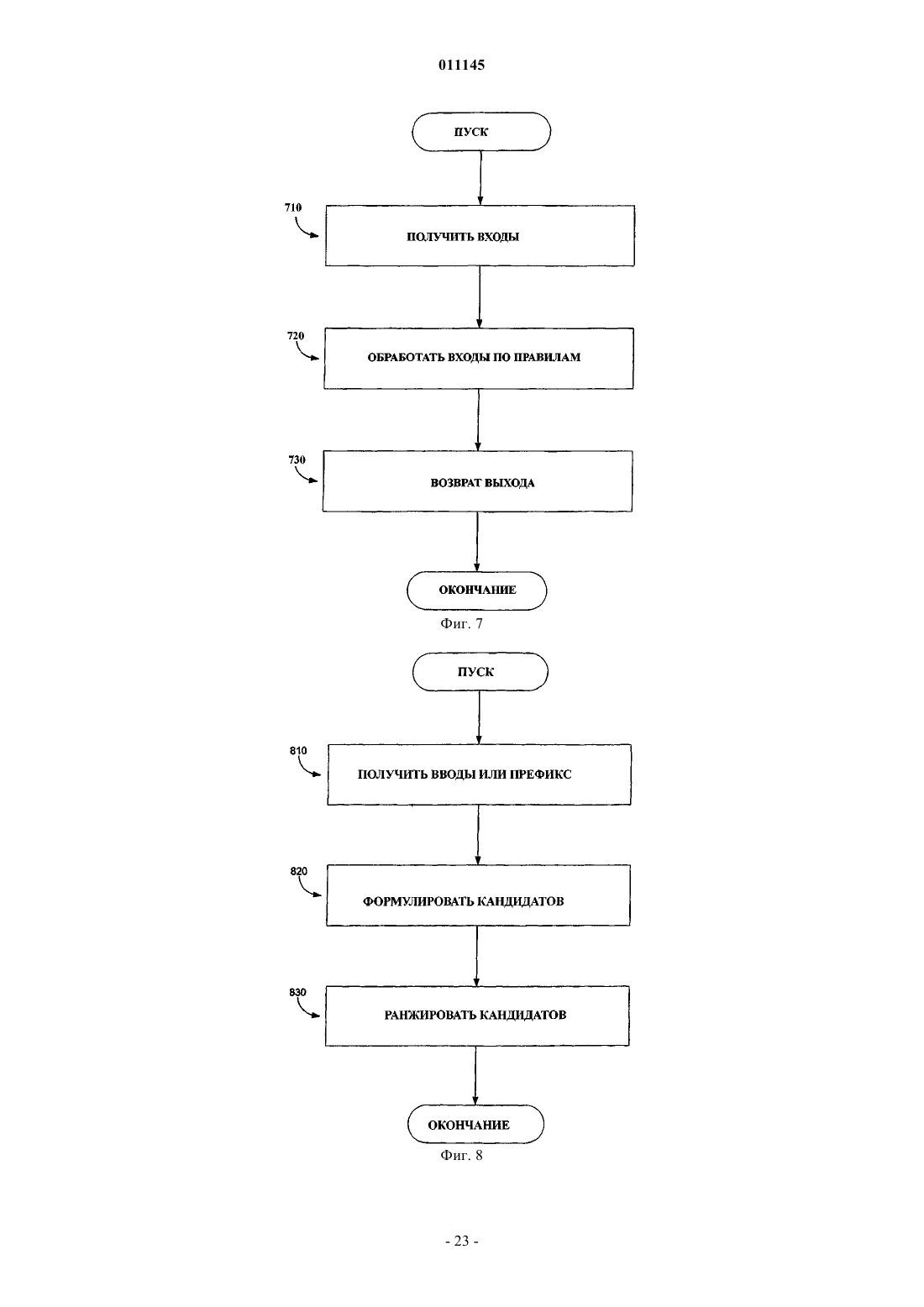
011145 Родственные заявки Заявка на данное изобретение связана с патентной заявкой США 10/800203 Способ и система для снятия неоднозначности и прогнозируемого разрешения на имя Van der Hoeven, зарегистрированной 12 марта 2004 г. Все заявки, цитируемые в рамках изобретения, приводятся в качестве ссылки. Область техники Изобретение в основном относится к вводу данных и более конкретно - к интерфейсам и логике для эффективного входа данных в устройства. Предпосылки создания изобретения Начиная с зарождения компьютерной эры, одна из наиболее устойчивых и непрерывных тенденций состояла в миниатюризации оборудования. Эта тенденция проявляется почти в каждой области техники. Сотовые телефоны, персональные цифровые помощники (PDA), переносные компьютеры и т.д. все время уменьшались в размере с поразительной скоростью. Вместе с тем, эти компактные устройства стали более мощными. Эта дихотомия несколько проблематична. Потребность в передаче и приеме информации повышается вместе с увеличением мощности устройства, в то время как неподвижные системы, доступные для такого дисплея и интерфейс ввода данных, естественно, сжимаются вместе с устройством. В каждой из двух подсистем ввода данных и дисплея имеются свойственные им физические ограничения на возможное уменьшение размера, до того как каждая подсистема станет либо неэффективной,либо бесполезной. Физические ограничения, накладываемые на связь с пользователем, намного больше,чем такие ограничения, накладываемые на интерфейс для ввода данных. Эти ограничения могут включать аппаратные ограничения, физиологические ограничения и то обстоятельство, что в большинстве случаев данные должны быть сообщены пользователю визуально. Поэтому большинство устройств, зарезервированных для связи и ввода данных, может быть основано на визуальном дисплее. Этот визуальный дисплей оставляет мало места для интерфейса для ввода данных. Были изобретены устройства для решения этой задачи, включая разработку программного обеспечения для распознавания почерка, вводимого в устройство. При использовании этого устройства пользователь может непосредственно вводить текст рукой на чувствительном к прикосновению дисплее. Эти рукописные данные затем преобразуются программой распознавания почерка в цифровые данные. Хотя это решение позволяет сообщать информацию и получать данные от пользователя по одному дисплею,точность и скорость программного обеспечения распознавания почерка оставляют желать лучшего. Кроме того, писание пером вообще медленнее, чем печать на клавиатуре, которая требует использования обеих рук. Поэтому выгодно использовать интерфейсы для ввода данных, которые имеют определенный объем и могут вводиться одной рукой. Предыдущие попытки в области такой клавиатуры привели к развитию клавиатуры, которая имеет уменьшенное число клавиш. На фиг. 1 показан прототип уменьшенной вспомогательной клавиатуры 100 для устройства. Вспомогательная клавиатура 100 является стандартной телефонной клавиатурой, имеющей десять цифровых клавиш 110-128, клавишу 130 и номерную клавишу 140. Для английского языка и многих других языков на основе алфавита цифровая клавиатура телефона дополнена буквенной клавиатурой, где три буквы связаны с каждой цифровой клавишей 110128. Например, двойка (2) клавиши 114 связана с буквами a-b-с. С некоторыми из этих уменьшенных клавишных устройств пользователь может использовать многочисленные нажатия клавиш для ввода слов или имен. Однако это решение также имеет недостатки, так как китайские и другие основанные на символах языки типа японского не имеют управляемого числа символов, которые могут быть нанесены на цифровую клавиатуру. Дополнительная проблема состоит в том, что каждое нажатие клавиши может соответствовать многим символам, создавая неоднозначность при последовательном нажатии клавиш. Решение проблемы неоднозначности состоит в том, чтобы сделать так, чтобы пользователь произвел два или несколько нажатий клавиш для определения каждого символа, причем клавиши могут быть нажаты одновременно (в сочетании) или последовательно. Однако такой подход требует многих нажатий клавиш и, следовательно, неэффективен. Идеальным является способ ввода данных, который требовал бы одного нажатия клавиши на букву. В прошлом снятие неоднозначности уровня слова использовалось для снятия или разрешения неоднозначности полных слов, сравнивая последовательность полученных нажатий клавиши с возможными значениями в словаре. Однако из-за ограничений декодирования снятие неоднозначности уровня слова не обеспечивает безошибочного декодирования неограниченных данных с эффективностью одного нажатия клавиши на знак. Таким образом, имеется потребность в устройствах, способах и системах для интерфейсов, которые допускают эффективный ввод различных данных одной рукой, и возможность уменьшения числа ударов,требуемых для ввода данных, используя логику для разрешения неоднозначности символов и предсказуемого завершения ввода.-1 011145 Краткое описание изобретения В изобретении раскрыты устройства, способы и системы для эффективного ввода текста в систему с ограниченным набором входных каналов. Эти устройства, системы и способы могут использовать интерфейс пользователя, который обеспечивает эффективную работу одной рукой, используя размещение клавиш, которые могут управляться большим пальцем одной руки. Этот интерфейс может быть адаптирован для конкретного устройства, в котором он используется, и в некоторых случаях множественные символы могут быть связаны с каждой клавишей или частью клавиши. Чтобы обеспечить эффективный ввод данных, эти устройства, системы и способы могут снимать или разрешать неоднозначность ввода пользователя в случае, когда данные, введенные пользователем, могут иметь несколько интерпретаций, и обеспечить эффективный способ определения точного ввода или прогнозировать ввод пользователя, и представить этот прогноз пользователю. Эти прогнозирующие системы и способы могут также приспосабливаться к склонностям определенного пользователя и включать сокращения, переводы и синонимы для часто используемых вводов. В одном варианте обнаруживается начальное нажатие клавиши, освобождение клавиши и движения между нажатиями клавиш, используя набор зон; начальное нажатие, освобождение и движение затем нормализуются в дискретное сообщение. В других вариантах набор зон содержит набор межклавишных зон и набор клавишных зон, при котором никакие две клавишных зоны не являются смежными, и каждая клавишная зона примыкает по меньшей мере к одной межклавишной зоне. В еще одном варианте набор зон размещается в наборе строк. В других вариантах каждая строка имеет клавишную зону на одном конце и межклавишную зону между двумя клавишными зонами в строке. В другом варианте каждая межклавишная зона перекрывается по меньшей мере двумя смежными клавишными зонами, к которым она примыкает. В еще одном варианте каждая часть каждой межклавишной зоны связана по меньшей мере с одной из двух смежных клавишных зон, к которым она примыкает. В некоторых вариантах семантическое значение связано с дискретным сообщением. Эти и другие особенности изобретения будут лучше поняты и оценены при чтении последующего описания вместе с приложенными чертежами. Это описание с указанием на различные варианты изобретения и подробные описания этих вариантов дается как иллюстрация, а не ограничение изобретения. Могут быть сделаны различные модификации замены, добавления или перестановки в пределах настоящего изобретения, и изобретение включает все такие замены, модификации, добавления или перестановки. Краткое описание чертежей В настоящее изобретение чертежи включены как сопроводительная и формирующаяся часть этого описания, чтобы проиллюстрировать некоторые аспекты изобретения. Четкое представление об изобретении и о компонентах и работе систем, предусмотренных изобретением, станет более очевидным при чтении описания примерного и, следовательно, не ограничивающего варианта, показанного на чертежах,в котором одинаковые цифровые обозначения определяют те же самые компоненты. Отметим, что отдельные части, изображенные на чертежах, не обязательно вычерчены в масштабе. На фигурах показано следующее: фиг. 1 - прототип малой клавиатуры; фиг. 2 - блок-схема одной возможной архитектуры для осуществления раскрытых в изобретении систем и способов; фиг. 3 - схема одного варианта размещения клавиш для использования зон с главным датчиком; фиг. 4 - еще одна схема варианта размещения клавиш для использования зон с главным датчиком; фиг. 5 - схема одного варианта размещения клавиш для использования зон для ввода данных в устройство; фиг. 6 - более подробное представление некоторых из зон, изображенных на фиг. 5; фиг. 7 иллюстрирует методологию обработки вводов базовой логикой; фиг. 8 иллюстрирует методологию формулирования предварительных оценок, которые могут использоваться базовой логикой при обработке вводов; фиг. 9 иллюстрирует одну конкретную методологию формулировки предварительных оценок, которые могут использоваться базовой логикой; фиг. 10 иллюстрирует один вариант структуры данных для сохранения модели языка. Описание предпочтительных вариантов Настоящее изобретение, различные признаки и детали этого изобретения описываются ниже более подробно на примерах, не ограничивающих изобретение вариантов, которые показаны на сопроводительных чертежах и детализированы в описании. Описания известных исходных материалов, способов обработки, известные компоненты и оборудование подробно не описываются, чтобы излишне не усложнять изложение сущности изобретения. Квалифицированные специалисты понимают, что подробное описание и конкретные примеры при раскрытии предпочтительных вариантов изобретения даются только для иллюстрации, а не для ограничения.-2 011145 Различные замены, модификации, добавления или перестановки в пределах основной изобретательской концепции станут очевидными квалифицированным специалистам после чтения настоящего раскрытия изобретения. Ниже приводится подробное описание примерных вариантов изобретения со ссылками на сопроводительные чертежи. Везде, где возможно, одинаковые цифровые позиции будут использоваться на всех чертежах для обозначения одних и тех же частей (элементов). Некоторые термины определены или разъяснены, чтобы помочь в понимании терминов, как они используются везде в описании. Термин знак означает любой символ вообще, причем знаком может быть буква, диакритический знак, часть кандзи, любой символ с коннотацией в области записи, печати и т.д. Термин клавиша предполагает обозначение зоны интерфейса, чувствительного к действию пользователя, включая касание. Семантическое значение может быть связано с клавишей или частями клавиши, и это семантическое значение может состоять из одного или большего количества символов или управляющей информации. Термин клавиатура означает группу клавиш. Термин предсказание означает попытку предсказать завершение последовательности символов. Это предсказание может быть основано на любом типе системы, включая вероятностный, математический, лингвистический или любой другой. Термин синоним используется в смысле используемой модели и означает возможную альтернативу прогнозу. Эти синонимы могут быть связаны с прогнозом и могут быть сохранены в структуре данных, соответствующей прогнозу, или конечному объекту, соответствующему прогнозу. Термин предложение означает последовательность из одного или нескольких знаков или набора этих последовательностей. Термин префикс означает последовательность из одного или большего количества знаков, которые могут или не могут быть расширены вводом пользователя, результатами снятия неоднозначности или прогноза и т.д. Термин кандидат означает последовательность из одного или большего количества знаков и соответствующей оценки в баллах. Эта оценка в баллах может быть основана на любой модели, включая вероятностную, математическую, лингвистическую или любую другую. Термин активная зона означает зону интерфейса, который является частью интерфейса, используемого для приема ввода от пользователя. Термин зона означает область интерфейса или зону в пределах области действия датчика. Термин неоднозначный подразумевает, что кое-что может иметь несколько возможных значений. Термин завершение представляет собой набор символов, которые могут формировать желательную конечную или промежуточную последовательность из символов, когда она связана с начальным набором символов (обычно называемый префиксом). Во многих случаях завершение можно рассчитать,чтобы иметь высокую вероятность формирования желательной конечной или промежуточной последовательности. Термин послать сообщение означает передачу или обмен или использование информации. Важно отметить, что не может быть сделано никакого предположения о том, как сообщение будет послано или даже необходима ли посылка сообщения в данном конкретном варианте. Термин последовательность означает конечное число элементов с понятием порядка. Набор может быть пуст или содержать только один элемент. Это определение обычно используется в математике. Авторы понимают его как (e1, , en,). Термин набор означает конечное число элементов без понятия порядка. Набор может быть пуст или содержать один элемент. Этот термин обычно используется в математике. Авторы понимают его как(e1, , en). Термин печать предназначен означать диапазон величин или классов. Это может быть печать переменной величины или величины для ее нумерации или чтобы определить значения или классы. Печатание элемента E с типом T пишется как: E:T. Термин структура означает упорядоченный набор элементов (e1, , en). Каждый элемент ei может быть напечатан с указателем типа ti. Тип структуры в этом случае будет последовательностью (e1, , en). Термин поле означает элемент структуры. Поля могут быть названы: P(e:t) подразумевает, что структура Р имеет поле е типа t. Если р типа Р (как указано выше), р.е представляет собой поле элемента р. Теперь обратим внимание на устройства, способы и системы для эффективного ввода текста в устройство с ограниченным набором входных каналов. Эти устройства, системы и способы могут использовать интерфейс пользователя, который обеспечивает эффективную работу одной рукой, используя размещение клавиш, которые могут набираться большим пальцем одной руки. Этот интерфейс может быть адаптирован к определенному устройству, в котором он используется, и когда, в некоторых случаях, с каждой клавишей или частью клавиши может быть связано множество знаков. Чтобы помочь в эффективном входе данных, эти устройства, системы и способы могут устранять неоднозначность ввода поль-3 011145 зователя от этих клавиш в случае, когда данные, введенные пользователем, могут иметь несколько значений или когда они могут обеспечить эффективный путь для пользователя, чтобы точно определить ввод. Эти системы и способы могут также прогнозировать ввод пользователя и представить этот прогноз пользователю, чтобы он мог быть выбран пользователем, вместо ввода полного текста вручную. Эти прогнозирующие системы и способы могут быть также приспособлены к склонностям определенного пользователя и включать определяемые пользователем сокращения и синонимы для часто используемых вводов. В примерном варианте изобретения выполняемые компьютером команды, могут быть строками ассемблерного кода или компилированного кода С, Java или кода другого языка. Может использоваться другая архитектура. Кроме того, компьютерная программа или ее программные компоненты с таким кодом могут быть выполнены в более чем одной среде, считываемой компьютером, и в более чем одном компьютере. Вернемся к фиг. 2, на которой представлен один вариант архитектуры 200 для осуществления и организации устройств, способов и систем. После чтения этого описания квалифицированные специалисты поймут, что в вариантах настоящего изобретения могут быть использованы многие другие архитектуры. В одном варианте эти архитектуры включают основной датчик 210, дополнительные датчики 212, клавиатурный модуль 220, модуль семантизации 240, базовую логику 250, модель языка 260 и модель использования 270. Клавиатурный модуль 220 может получать данные от основного датчика 210. Клавиатурный модуль 220 обрабатывает эти данные и посылает результаты в модуль семантизации 240. Модуль семантизации 240 получает результаты от клавиатурного модуля 220 и от любых дополнительных датчиков 212. Модуль семантизации 240 затем может обработать эти данные, чтобы сформулировать данные для использования базовой логикой 250, используя контекст 290, текстовый элемент 280, элемент меню 282 и устройства вывода 284. Базовая логика 250 может устранить неоднозначность или предсказуемо завершить ввод пользователя, используя ввод модуля семантизации 240, модель языка 260 или модель использования 270. Базовая логика 250 может представлять свои результаты модулю семантизации 240. Модуль семантизации затем может вывести результаты через комбинацию контекстов использования 290, текстовый элемент 280, элемент меню 282 и устройства вывода 284. В целом, эта архитектура предназначена для расширения возможностей пользователя по вводу данных в устройства, обеспечивая широкий диапазон конфигураций для устройства ввода данных, включая конфигурацию, предназначенную для использования большого пальца одной руки. В этом варианте можно также устранить неоднозначность ввода, предоставляя пользователю эффективный способ однозначного определения точного ввода и представляя предсказуемое завершение ввода пользователю, чтобы избежать дополнительного ручного ввода. Обычный специалист в данной области техники после чтения этого описания поймет, что эта архитектура представлена только для целей иллюстрации возможностей изобретения и что все описанные функциональные возможности могут быть воплощены в широком разнообразии направлений, включая большее или меньшее количество модулей, с посылкой сообщений или без них, что реализуется программными средствами, аппаратными средствами и т.д. В конкретных вариантах изобретения действия пользователя фиксируются датчиками 210, 212 и сообщаются модулю семантизации 240. В некоторых вариантах информация от основного датчика 210 может быть обработана клавиатурным модулем 220 перед передачей сообщения в модуль семантизации 240. Модуль семантизации 240 может быть единственным интерфейсом связи с пользователем и может быть элементом, ответственным за передачу и форматирование всех приходящих и уходящих сообщений. Передача модуля семантизации 240 может зависеть от ситуации или может обеспечивать параметризацию для интеграции в систему. Базовая логика 250 может содержать правила для управления взаимодействием между модулем семантизации 240 и пользователем, включая прогноз ввода пользователя и устранение неоднозначности. Базовая логика 250 может использовать структуры данных, включая модель языка 260 для устранения неоднозначности ввода пользователя и модели пользователя 270 для прогноза ввода пользователя. Текстовый элемент 280, элемент меню 282 и другие дополнительные устройства вывода 284 могут использоваться модулем семантизации 240, чтобы показать результаты работы логики или состояния системы. Текстовый элемент 280 может быть интерфейсом ввода данных, с помощью которого пользователь может вставлять или вводить последовательность символов или расширять существующую последовательность символов и через который эта последовательность символов может быть отображена. В одном конкретном варианте, текстовый элемент 280 представляет собой устройство, в котором пользователь может вставлять последовательность символов или расширить существующую последовательность. Текстовый элемент 280 может посылать сообщение (EditText) в систему или в модуль семантизации 240, содержащее информацию относительно возможного префикса, или послать другой вводимый пользователем текст. Текстовый элемент 280 затем получает сообщение SubstituteText (заменить текст) от модуля семантизации 240, содержащее последовательность символов (S) в ответ на сообщениеEditText (редактировать текст). Текстовый элемент 280 может также получать сообщение EndEdit (конец редактирования), сигнализируя о завершении сообщения EditText, когда пользователь закончил ввод по-4 011145 следовательности символов. Когда текстовый элемент 280 получает сообщение SubstituteText, текстовый элемент 280 может ответить соответственно. Если это первое полученное сообщение SubstituteText после посылки последнего сообщения EditText и последнее сообщение EditText имело префикс, то аргументSubstituteText меняется на последовательность символов относительно префикса в текстовом элементе 280, который затем отображается пользователю. Если это первое сообщение SubstituteText, полученное после того, как было послано последнее сообщение EditText, и последнее сообщение EditText не имели никакого префикса, текстовый элемент 280 может только вставить аргумент SubstituteText в последовательность, отображаемую пользователю. Для двух последовательных сообщений SubstituteText без сообщений EndEdit между ними этот элемент заменяет текст первых сообщений аргументом SubstituteText второго сообщения и отображает информацию пользователю. Элемент меню 282 может представлять пользователю ряд выборов или опций в зависимости от вывода или состояния системы. В некоторых вариантах элемент меню 282 может быть объединен с текстовым элементом 280. Элемент меню 282 может отображать список выборов или дерево выборов для выбора пользователем. Элемент меню 282 может получать сообщения SetMenu (установка меню), содержащие аргумент, от модуля семантизации 240. Этот аргумент может быть простым перечнем выборов,когда меню представляет собой список, или аргумент относится к позиции выбора в дереве или во вложенном списке выборов в случае меню дерева. Выборы могут быть последовательностями символов или констант. Когда пользователь делает выбор из представленного списка Selectltem (выбрать позицию),сообщение может быть послано на модуль семантизации 240 со значением выбора в виде аргумента. Контекст использования 290 может включать управление свойствами и конфигурацией датчиков 210, 212 и уведомление пользователя о некоторых событиях. В одном варианте контекст использования 290 может включать TextInputQuery (запрос на ввод текста), чтобы подготовить текстовый элемент 280 или элемент меню 282 для взаимодействия с пользователем. Текстовый элемент 280 может ответить на запрос, передавая сообщение EditText с флажком запроса (QueryFlag) на модуль семантизации 240, указывая, что текстовый элемент 280 подготовлен для редактирования. Контекст использования 290 может также определить, когда редактирование текста в текстовом элементе 280 выполнено через перехват сообщений StartEdit (начало редактирования) при редактировании в начале передачи или EditStop (конец редактирования) при редактировании окончаний. Контекст использования 290 может также управлять различными свойствами основного датчика 210 и уведомлять пользователя о некоторых событиях. Эти события начинаются с сообщения UserNotify (уведомление пользователя), которое может содержать информацию о типе уведомления. Система может интерпретировать это действие, чтобы реагировать на каждый тип уведомления. Эта интерпретация может быть выполнена модулем семантизации 240. Основной датчик 210 может контролировать набор переменных в среде и посылать результаты путем дискретной передачи сообщений на клавиатурный модуль 220. Кроме того, основной датчик 210 может реагировать на действия пользователя, что может состоять из заданной пользователю конкретной области в пределах диапазона основного датчика 210 последовательности движений, сделанных пользователем, и прекращение движения пользователя. Эти действия обычно включают прямой физический контакт между пользователем и датчиком, косвенный контакт с помощью инструмента, типа пера и т.д.,или по способу, не включающему физического контакта типа движений глаза, лазерного указателя и т.д. Обычные специалисты в данной области техники поймут, что существуют самые различные способы реализации основного датчика 210. Примеры такой реализации включают глаз, системы слежения, сенсорные экраны, джойстики, графические интерфейсы пользователя, традиционная клавиатура во всех их электронных или механических видах и т.д. Точно так же эти сенсорные устройства могут быть осуществлены в аппаратных средствах, программном обеспечении или комбинации их обоих. После чтения этого описания также очевидно, что главный датчик 210 может быть расположен в самых различных местах, чтобы обеспечить удобный ввода данных. Прежде чем перейти к подробному описанию взаимодействия компонентов архитектуры 200, рассмотрим один пример размещения клавиш для использования с основным датчиком 210, который может обнаруживать контакт. Этот пример представлен на фиг. 3. В основном датчике 210 может быть определен набор не перекрываемых зон 300-390. Эти зоны 300-390 могут быть клавишными зонами 300, 310390, предназначенными для оказания помощи пользователю при взаимодействии с узлами системы. Эти клавишные зоны 300, 310-390 могут быть расположены в виде одного или нескольких рядов 312, 314,причем каждый ряд содержит одну или большее количество клавишных зон 300, 310-390, и ряды, в свою очередь, могут размещаться в концентрических кривых. Зона, которая находится вне рядов 312, 314 клавишных зон 300, 310-390, является не клавишной зоной 302. Каждая клавишная зона 300 310-390 связана с уникальным идентификатором, который представляет собой упорядочение клавишных зон 300, 310-390 благодаря расположению клавишных зон 300, 310-390 по рядам и между рядами. Например, ряды 312, 314 могут быть пронумерованы от самых малых до самых больших, начиная с самого дальнего ряда. В примере, изображенном на фиг. 3, ряд 314 имел бы номер ряда 1, в то время как ряд 312 имел бы номер ряда 2. Клавишные зоны 300, 310-390 можно также упорядочить в пределах их-5 011145 соответствующих рядов. На фиг. 3 номера могут быть присвоены клавишным зонам 300, 310-390 слева направо, следовательно, зоны 300, 350 могут быть пронумерованы номером 1, зоны 320, 360 номером 2 и т.д. Используя такое упорядочивание по рядам и зонам, для каждой создаваемой зоны может быть задан уникальный идентификатор, используя основной датчик 210. В текущем примере клавишная зона 300 могла бы быть пронумерована как (2, 1), клавишная зона 350 может быть идентифицирована как (1, 1),клавишная зона 360 как (1, 2) и т.д. Как можно видеть специалистам, можно использовать много схем,чтобы уникально идентифицировать набор зон 300-390 в пределах основного датчика 210, и эти зоны 300-390 могут быть определены по различным топологиям в зависимости от размера конкретного датчика, устройства, пользователя или любых других критериев. Основной датчик 210 может контролировать окружающую среду и определять направленную зону или контактную зону, где контакт делается пользователем. Эта направленная зона может состоять только из точки или площадки, где осуществлен контакт, или может состоять из определенной области, окружающей место фактического контакта. Когда контакт сделан, основной датчик 210 может определить,перекрывают ли зоны 300-390 направленную зону. Для каждой зоны 300-390, которая перекрывает направленную зону, основной датчик 210 посылает сообщение на клавиатурную логику 220. Каждое сообщение может быть сообщением, которое идентифицирует начало контакта (StartContact) и соответствующий уникальный идентификатор для перекрывающей зоны 300-390. Когда направленная зона перемещена и начинает перекрывать любую другую зону 300-390, клавиатурная логика 220 получает сообщение, указывающее, что зона 300-390 была введена вместе с уникальным идентификатором этой зоны 300-390. Когда контакт разорван, основной датчик 210 обнаруживает это действие и посылает соответствующее сообщение (StopContact) в клавиатурный модуль 220. Следовательно, основной датчик может считывать начало контакта, прохождение этого контакта и разрыв контакта. Сообщения этого типа могут передаваться между главным датчиком 210 и клавиатурным модулем 220, используя описанный выше формат сообщений. Следует отметить, что хотя все типы контакта могут быть определены главным датчиком 210, сообщения обо всех из них нельзя передавать на клавиатурный модуль 220 или использовать для оценки контакта пользователя. Зоны 300-390 могут быть обозначены как активные или неактивные в зависимости от размещения зон 300-390, спецификации пользователя, семантического значения, связанного с зонами 300-390 и т.д. Когда зона 300-390 обозначена как неактивная, основной датчик 210 не может сравнивать область основного датчика, соответствующего неактивной зоне, с направленной зоной, и поэтому никакие сообщения, содержащие уникальный идентификатор неактивной зоны, не будут посланы в клавиатурную логику 220. Точно так же может быть сделано сравнение, но никакие сообщения, содержащие уникальный идентификатор неактивной зоны, не будут посланы в клавиатурную логику 220. Клавиатурная логика 220 может дифференцировать ряд сообщений начала/прекращения контакта по сигналам основного датчика 210. Клавиатурная логика 220 может брать сообщения, генерируемые основным датчик 210, и интерпретировать эти сообщения, чтобы определить номер ряда клавишный зоны 300, 310-390, в которой установлен контакт и номер клавишный зоны 300, 310-390 в ряду. Кроме того, клавишная зона 300, 310-390 может быть вызвана в нескольких режимах в зависимости от движения контакта пользователя или точки освобождения пользователя, и клавиатурная логика может также определять режим, в котором вызвана клавишная зона 300, 310-390. Эти режимы могут быть обозначены как(нижний ряд) и RowUpper (верхний ряд). Эти сообщения могут соответствовать точке освобождения пользователя, относительно того, где первоначально имел место контакт пользователя. В одном варианте сообщения от основного датчика 210 могут быть обработаны по следующему алгоритму. Если StartContact Location (место начала контакта) является бесклавишным (nokey), клавиатурный модуль ждет следующее сообщение начала контакта (StartContact) без какой-либо другой деятельности. Имеются две переменные: ряд и клавиша. Каждая из них может иметь значения: верхняя, нижняя и та же самая. Для каждой операции StartContact (kr1, n1, где r1 - ряд, которому принадлежит клавиша, и n1 - номер клавиши в ряду): На фиг. 4 представлена другая схема расположения компонентов для использования с вариантами основного датчика 210. Хотя схема расположения, описанная со ссылкой на фиг. 3, совершенно адекватна, когда имеется много зон 300-390, может оказаться трудным определить место контакта пользователя,когда контакт расположен близко к границе двух зон. Чтобы устранить это затруднение, схема расположения 400 на основном датчике 210 может включать межклавишные зоны 400-470, чтобы осуществить механизм блокировки. Межклавишные зоны 400-470 могут чередоваться с клавишными зонами 300, 310390 таким образом, что никакие две клавишные зоны 300, 310-390 не будут смежными. Эти межклавишные зоны 400-470 могут также иметь уникальные идентификаторы, и основной датчик 210 может обнаружить, когда имеет место контакт в межклавишной зоне 410-470, и послать соответствующее сообщение клавиатурной логике 220. Когда присутствуют межклавишные зоны 400-470, сообщения от основного датчика 210 могут быть обработаны согласно следующему алгоритму. Номер ряда x теперь составлен из зон с отметками: (kx,1, kx,2, ix,2, , ix,y-1, kx,y), где y - число клавиш ряда с номером x. Если StartContact Location - бесклавишная или межклавишная зона, клавиатурный модуль ждет следующее сообщение StartContact без выполнения каких-либо других операций. Для специалистов в данной области техники ясно, что могут быть использованы межклавишные зоны с механизмом блокировки между двумя зонами или наборами зон. Например, межклавишная зона может быть применена с механизмом блокировки между рядами 312, 314.-7 011145 На фиг. 5 представлена подробная схема расположения интерфейса пользователя 500 для использования с вариантами настоящего изобретения. Интерфейс пользователя 500 может содержать основной датчик 210 и текстовое окно 510 для отображения информации для пользователя. Основной датчик 210 может охватывать набор зон 520-542. Каждый набор зон может представлять набор символов пользователю. Один набор зон 520-528 может соответствовать символам английского языка, в то время как другие зоны 530-542 могут соответствовать другим функциям в зависимости от ситуации или архитектуры системы, с которой используется интерфейс пользователя 500. Другие функции могут включать функции команды или функции меню. На фиг. 6 представлен набор зон 520-528 со всеми особенностями, которые присущи английскому языку. Зоны 520-528 могут быть размещены по кривой таким образом, что зоны 520-528 могут быть активированы большим пальцем руки, удерживающей устройство, в котором используется интерфейс пользователя 500. В изображенном варианте зоны 520-528 размещаются так, что они могут наиболее эффективно приводиться в действие человеком, владеющим правой рукой лучше, чем левой. Однако, как описано выше, расположение клавиш может быть изменено по любому желательному формату, включая форматы, которые позволяют эффективное приведение в действие левой рукой. Каждая зона 520-528 содержит до шести пар символов, сгруппированных клавишей в верхнюю пару 610, центральную пару 620 и нижнюю пару 630. Пользователь может приводить в действие зоны 520-528, и основной датчик 210 обнаружит это действие и передаст сообщения, соответствующие этому действию, на клавиатурную логику 220, которая, в свою очередь, передаст это сообщение как входящее сообщение. Затем логика семантизации 240 свяжет это входящее сообщение с надлежащей парой знаков. Например, чтобы выбрать центральную пару 620, пользователь может касаться зоны с желательной парой и освободить клавишу. Чтобы выбирать любую более низкую пару 630, пользователь может касаться зоны с желательной парой и скользить пальцами к любой зоне в направлении желательной пары, и обратное направление справедливо для выбора верхней пары 610. Чтобы проиллюстрировать этот пример дополнительно, предположим, что желательна буква из пары (s, h). Этот выбор может быть сделан,касаясь зоны 526, содержащей (g, m), и скользящим движением до пары (b, j). Отметим, что движение может быть остановлено в любой зоне 520-524 под зоной 526, содержащей желательную пару (s, h). Логика семантизации 240 может завершить это движение в желательной паре (s, h). Логика семантизации 240 может получать сообщение от клавиатурного модуля 220 или от дополнительных датчиков 212 и передать это сообщение набору символов или набору команд в зависимости от контекста, в котором получено это сообщение. В одном конкретном варианте логика семантизации 240 получает входящее сообщение от клавиатурной логики 220 и передает это сообщение набору возможных символов в соответствии с окружающей средой. Например, описанное выше действие пользователя со ссылкой на фиг. 6 может быть сведено к решению вызова пары букв (s, h). Это решение затем может быть передано в базовую логику 250. Логика семантизации 240 может также отвечать за координирование ввода и вывода системы в соответствии с окружающей средой системы. В других вариантах модуль семантизации 240 может отвечать за передачу входящих сообщений к символам или командам. Эта передача может зависеть от контекста; часть контекста, необходимая для модуля семантизации, может называться семантизацией контекста (SemantifyContext). Модуль семантизации 240 может ответить на входящее сообщение, представляющее символы в соответствии с контекстом (SemantifyContext), с сообщением SymbolMessage, содержащим набор символов. Если входящее сообщение представляет собой команду, это сообщение команды (CommandMessage) выдается с уникальным идентификатором команды. Эта информация уникального идентификатора может иметь значение, которое соответствует желательной команде, включая: BackSpaceCmd (команда стереть влево), EndLexiconCmd (команда конец лексикона), ItemSelectionCmd (команда выбор пункта), NextCharCmd (команда следующий знак) и PrevCharCmd (команда предыдущий знак). Если входящее сообщение ничего не содержит относительно контекста (SemantifyContext), никакое действие не может быть выполнено. Входящее сообщение может представлять собой как команду, так и набор символов, в этом случае сообщение SymbolMessage (сообщение набора символов) может быть послано перед посылкой сообщения CommandMessage (сообщение команды), чтобы отобразить набор символов. Модуль семантизации 240 может также отвечать за конфигурацию датчиков 210, 212. В некоторых вариантах сообщения от текстового элемента 280, элемента меню 282 или контекста пользователя 290 обрабатываются следующим образом. Сообщение SelectItem вызывает передачу команды CommandMessage с командой ItemSelectionCmd как идентификатор команды и аргумент сообщения Selectltem. Если последнее сообщение EndEdit более новое, чем последнее сообщение StartEdit, прием сообщения StartEdit вызывает передачу сообщения EditText. Если последнее сообщение StartEdit более новое,чем последнее сообщение EndEdit, прием сообщения EndEdit вызывает передачу сообщения CommandMessage в базовую логику 250 с аргументом EndLexiconCmd. Если модуль семантизации 240 готов к посылке сообщения SymbolMessage, когда последнее сообщение EndEdit более новое, чем последнее сообщение StartEdit, модуль семантизации 240 приостанавли-8 011145 вает посылку сообщения SymbolMessage, посылает сообщение на запрос ввода текста TextInputQuery в контекст пользователя 290. Если следующее полученное сообщение является сообщением EditText, связанным с сообщением QueryFlag, модуль семантизации 240 передает сообщение EditText в базовую логику 250 и посылает временно задержанное сообщение SymbolMessage.SemantifyContext может быть дополнительным результатом функции ContexGeneration, связанным с последним полученным сообщением (либо от компонентов архитектуры, либо от внешнего устройства),и предыдущего сообщения SemantifyContext в виде аргументов. В интервале между любыми двумя сообщениями SemantifyContext остается постоянным. Обратимся теперь к базовой логике 250, основанной на использовании модуля семантизации 240. На фиг. 7 представлена основная методология, используемая базовой логикой 250. Базовая логика 250 может иметь набор вводов (блок 710), применять правила обработки (блок 720) и обратный выход (блок 730), если это необходимо. Базовая логика 250 может иметь набор вводов (блок 710), причем эти вводы могут быть сформированы внутри базовой логики 250 или могут быть получены от пользователя через основной датчик 210. Вводы могут также быть получены базовой логикой 250 (блок 710) от модуля семантизации 240. Как описано выше, в некоторых случаях модуль семантизации 240 может формировать набор сообщений, в зависимости от сообщений, полученных этим блоком, и контекста, в котором этот блок работает. Модуль семантизации 240 может передавать эти сообщения к базовую логику 250, которая, в свою очередь, воспринимает эти сообщения как набор вводов (блок 710). В некоторых вариантах этот ввод может представлять собой сообщения, представленные в виде символом или команд. Кроме того, эти сообщения могут содержать префикс и последовательность символов, относящихся к префиксу. Базовая логика 250 может иметь этот набор вводов (блок 710) и обрабатывать их (блок 720) согласно определенному набору правил. Эта обработка может включать формулировку предложения, которое может быть символом, словом, произвольной последовательностью символов или любым их сочетанием. Это предложение может быть получено при снятии неоднозначности ввода и связано с прогнозированным завершением или прогнозом или некоторой комбинации из двух. Правила, которые базовая логика 250 использует при обработке набора вводов (блок 720), могут быть предназначены для использования модели языка 260 и модели использования 280, чтобы создать набор кандидатов или прогнозов и оценить эти кандидаты или прогнозы, чтобы формировать набор предложений, которые могут быть представлены пользователю. В одном варианте базовая логика 250 использует оценку баллов, чтобы обработать ввод (блок 720). Когда основная логика получает ввод, и этот ввод не имеет префикса, может быть сформировано одно или большее количество предложений, и оценка делается на основе системы баллов. Однако, если имеется префикс, последовательность может быть сформирована, приобщая новый ввод к префиксу и делая попытку сформировать и оценить одно или несколько прогнозов, основанных на этой последовательности. Если никакие кандидаты не могут быть сформированы или сформированные кандидаты не превышают некоторый пороговой оценки в баллах, может быть предложен способ для определения ввода, в противном случае кандидаты оцениваются,делаются прогнозы и предложение может быть сформулировано и представлено пользователю на основе этой оценки. Предложения могут также быть сформулированы на основе снятия неоднозначности первоначального ввода, прогнозируемого завершения или некоторого сочетания этих двух способов. Правила, которые использует базовая логика для обработки набора вводов (блок 720), могут быть применены для модели языка 260 и модели использования 280 для создания набора кандидатов или прогнозов и для оценки этих кандидатов или прогнозов для формирования набора предложений, одно из которых может быть выдано пользователю. В одном варианте для обработки ввода (блок 720) в базовой логике используется оценка баллов. Когда базовая логика получает ввод, и этот ввод не содержит префикса, одно или несколько предложений могут быть сформированы и оценены в соответствии с системой баллов. Однако, если присутствует префикс, можно сформировать последовательность, добавляя новый ввод к префиксу и делая попытку сформировать и оценить одного или нескольких кандидатов на основе этой последовательности. Если кандидаты не могут быть сформированы или если сформированные кандидаты не могут преодолеть некоторый порог по баллам, должен быть применен некий способ определения ввода, в противном случае кандидаты оцениваются, делается прогноз и предложения формулируются и представляются пользователю на основе этой оценки. Предложения могут быть также сформулированы на основе снятия неоднозначности первоначального ввода. В некоторых вариантах базовая логика 250 может формировать кандидата, основанного на вводе,определять прогноз от одного или нескольких кандидатов и формулировать предложение, которое будет представлено пользователю на основе сформированного набора кандидатов и прогнозов. В некоторых вариантах правила и алгоритмы, используемые базовой логикой 250, могут быть сгруппированы в три категории на основе правил предположения, правил однозначности и внутренних правил. Правила однозначности и правила предположения могут быть основным драйвером для базовой логики 250, тогда как внутренние правила могут обеспечивать функции управления позади базовой логики 250 и могут обеспечивать функциональную ответственность за использование правил однозначности и правил предположения, оценку набора этих двух наборов правил или оценку откликов этих наборов правила. Кроме того, внутренние правила могут быть ответственны за создание префикса или пред-9 011145 ложения, которое будет показано пользователю. Эти внутренние правила могут работать совместно с правилами однозначности и правилами предположения в зависимости от желательных функциональных возможностей и контекста, в котором используются эти правила. Эти правила могут описывать поведение системы в различных ситуациях и могут использоваться на основе пожелания пользователя или внутреннего статуса. Правила однозначности могут описывать поведение, когда ввод, полученный от пользователя или от модуля семантизации 240,неоднозначен или нет никакого адекватного кандидата. В некоторых вариантах эти правила однозначности основаны только на модели языка 260. Правила предположения могут описывать поведение, когда нужный кандидат может быть найден, и в вариантах могут быть использованы как модель языка 260, так и модель использования 280. В одном конкретном варианте основной логический модуль 250 получает сообщение CommandMessage или сообщение SymbolMessage от модуля семантизации 240. Базовая логика 250 отвечает на эти сообщения в соответствии с набором правил. Когда правила базовой логики 250 указывают на связь с пользователем, модуль семантизации 240 используется для доставки соответствующих сообщений, используемых для связи с пользователем. В этом варианте остальная часть правил базовой логики 250 организована при трех заголовках:(1) правила предположения, которые описывают поведение базовой логики 250, когда система имеет уместные предложения по вводу;(2) правила однозначности, которые описывают, как система ведет себя, когда ввод неоднозначен и система не может предположить никакого уместного предложения относительно ввода; и(3) внутренние правила, которые содержат несколько функций, необходимых для оценки предположений, содержащихся в правилах однозначности. Каждое из этих правил подробно описано ниже. Когда базовая логика 250 получает сообщение EditText, она реагирует следующим образом: Этот алгоритм инициализирует состояние базовой логики 250 для нового ввода. Инициирование является простой операцией, если нет никакого префикса. Если есть префикс, алгоритм делает попытку поиска самой длинной частичной строки, чтобы завершить префикс, используя модель языка 260. Если модель языка 260 не содержит такую частичную строку, алгоритм переключается в режим однозначного входа.i. Правила предположения. Правила предположения применяют в состоянии EdititionStateGuessingState. Этот раздел правил имеет уникальную константу Примечание. Эти правила для сообщения SymbolMessage могут обеспечить обработку ввода поль- 11011145 зователя и могут выяснить, какую последовательность символов пользователь хочет ввести на основе всей полученной информации, начиная с последнего сообщения EditText, независимо от того, является ли ввод пользователя неоднозначным или нет. Сообщение CommandMessage В зависимости от идентификатора команды, содержащегося в сообщении, предпринимаются следующие действия: Примечание. Эти правила могут вернуть базовую логику 250 в состояние, в котором она находилась прежде, чем было получено последнее сообщение SymbolMessage. Примечание. Если пользователь выбрал в меню предложение Add (добавить), это правило переключает базовую логику 250 в однозначный режим, в другом случае это правило очищает контекст и учитывает последовательность символов, составленную, начиная с последнего сеанса редактирования Примечание. Пользователь может выбрать одно из предложений как ввод, если он хочет появиться в текстовом элементе TextElement.ii. Правила однозначности. В состоянии State=Unambiguous применяются правила, индексированные по правилам предположения.iii. Внутренние правила. Правила, описанные в этом разделе, применяются при оценке правил UnambiguousRules иAccumulate и Invariant могут быть определены в зависимости от способа исполнения, который будет ясен специалистам после прочтения этого описания. Примечание. Эти правила могут показывать пользователю все нужные предложения, оцененные в- 14011145 настоящее время для снятия однозначности/прогноза его ввода. Коррекция является операцией, зависящей от выполнения, и может относиться к вероятности прогнозов с вероятностями предложений снятия неоднозначности. Это гарантирует то, что ввод пользователя является в среднем минимальным. Функции ExtendProposition (расширить предложение) и FilterProposition (фильтровать предложение) представляют собой функции, которые могут зависеть от выполнения. Функция FilterProposition может корректировать порог классификации, который определяет предложения, предназначенные для показа пользователю. Более высокий порог понижает число нерелевантностей в предложениях, показываемых пользователю. Функция Store Word (сохранение слова) также зависит от выполнения и может удерживать место для набора символов и управлять количеством ресурсов, выделенных для структуры UsageModel и LanguageModel. Она может также управлять адаптацией моделей к поведению пользователя для повышения надежности прогнозов и снятию неоднозначности при будущем использовании. На фиг. 8 представлен один вариант способа, в котором базовая логика 250 может использовать модель языка 260. Модель языка 260 представляет собой дальнейшее углубление и усовершенствование модели, описанной в статье J.G. Cleary и J.H. Witten, озаглавленной Сжатие данных, используя адаптивное кодирование и частичное соответствие строк, опубликованной в VolumeCom-32,4, апрель 1984 г., IEEE Communications Journal, упоминаемый здесь в качестве ссылки. Базовая логика 250 может использовать модель языка 260, чтобы получить префикс или ввод (блок 720), формулировать набор прогнозов (блок 820) и ранжировать набор прогнозов (блок 830). Базовая логика 250 может получать префикс и ввод. Префикс может быть произвольно длинным набором символов, включая пустой набор, тогда как ввод может включать входящее сообщение типа, описанного в отношении модуля семантизации 240. Затем рассчитывается блок кандидатов (блок 820) на основе префикса и ввода. Если префикс пуст, кандидат может быть рассчитан только на основе ввода. Однако, если префикс не является пустым набором, базовая логика 250 может попытаться осуществить набор строки, связанной с префиксом, и формировать прогноз (блок 820) на основе префиксе. В некоторых вариантах базовая логика 250 может формулировать этих кандидатов (блок 820), используя модель языка 260, которая может использовать древовидную структуру, чтобы сохранить произвольно длинные частичные строки и соответствующие показатели. В одном варианте базовая логика 250 находит самую длинную строку в модели языка 260, которая связана с префиксом. В соответствующих вариантах базовая логика 250 может использовать модель языка 260, чтобы сформировать список кандидатов, причем этот список может быть последовательным списком или гнездовым списком в зависимости от выполнения. Основная логика может определять сумму баллов, связанную с кандидатом на основе баллов, связанных с каждым узлом дерева, осуществленного в модели языка 260. В свою очередь, это множество может быть основано на вероятностной модели. Специалистам в данной области вполне понятно, что имеется множество алгоритмов, которые могут быть использованы для подсчета баллов и прогнозов счета. Например, предположим, что пользователь желает ввести слово тест. Используя схему расположения, показанную на фиг. 6, пользователь может выбрать пару (t, z), и базовая логика 250 затем может вычислять вероятность t и вероятность z. Затем пользователь выберет пару (е, f). Базовая логика 250 может использовать модель языка, чтобы вычислить сумму баллов символов е и f, следуя за каждым из символов, связанных с набором предыдущих кандидатов (t, z), и умножить результат на количество вероятностей каждого символа в начальной паре символа (t, z). Этим способом может быть рассчитана вероятность каждой последовательности из двух символов. В одном конкретном варианте структура для сохранения модели языка 260 этого типа и соответствующей логики для обработки ввода и вычисления вероятностей может быть осуществлена следующим образом. Модель языка 260 может содержаться в структуре типа LanguageModel, представленной как: Структура узла (NodeStruct) в вариантах может быть структурой [Clearyl], модулем синтаксиса. Корень (root) может быть точкой ввода основной логики к модели языка 260. Следующие свойства и алгоритмы могут быть определены по структуре, которая поддерживает модель языка 260: Примечание. Это свойство справедливо, если N2 находится на том же самом уровне, что и N1 в дереве, и является ложным в других случаях. На фиг. 9 представлен один вариант способа, в котором базовая логика 250 основана на модели использования 280. Базовая логика 250 может применить модель использования 280, чтобы получить набор строк (блок 910), формулировать набор прогнозов (блок 920) и ранжировать набор прогнозов (блок 930). Базовая логика 250 может получать набор символов (блок 910), который может состоять из набора строк,и эти строки могут быть префиксом и вводом от пользователя. В некоторых вариантах эти символы могут быть получены или извлечены базовой логикой 250 из набора кандидатов, собранных или возвращенных, при этом основная логика использует модель языка 260. Этот набор строк затем может использоваться для формулирования набора прогнозов (блок 820) на основе строки из набора строк. Модель использования 280 может определить ряд возможных завершений строки, основанных на статистическом упорядочении возможных завершений. В одном варианте модель использования 280 может использовать древовидную структуру, чтобы представить слова, причем каждый узел дерева содержит знак. Каждый узел, который может определять конец слова, может быть демаркирован и выполнена оценка баллов, связанная с таким конечным узлом. Специалистам в данной области вполне понятно разнообразие систем подсчета, которые могут использоваться для определения оценки в баллах. Чтобы продолжать вышеупомянутый пример, предположим, что строка te получена моделью использования 280. На фиг. 10 представлено одно дерево, в котором модель использования 280 может быть применена для завершения строки. Строка te может использоваться как индекс в дереве, основанный на представлении слов 1000, которые начинаются с te, и это дерево 1000 может иметь листья 1010,1020, 1030, 1040, которые могут содержать признаки, предлагаемые для возможного завершения строкиte. Таким признаком может быть оценка в баллах, связанная с листьями 1010, 1020, 1030, 1040, или в некоторых вариантах булево значение. Эта оценка в баллах может быть основана на числе узлов одинаковой глубины, которая может завершать ту же строку. Оценка в баллах может также быть основана на том, сколько узлов в одной и той же строке не завершено для строки. Если оценка в баллах связана с узлом, этот узел может быть ранжирован (блок 830), и последовательность знаков, связанных с каждым узлам по пути через дерево 1000 к узлу с самым высоким (или самым низким) ранжированием, может быть возвращена. Обращаясь к фиг. 10, видим, что если узел 1020 имеет самую высокую сумму баллов, то последовательность тестированных знаков может быть возвращена. В других вариантах каждая последовательность знаков, связанных с листьями в путях через- 16011145 поддерево может быть возвращена вместе с суммой баллов соответствующего листа. Точно так же синонимы прогнозов могут быть возвращены вместе с их соответствующей оценкой баллов. Например, если на фиг. 10 узел 1020 имеет самую высокую оценку баллов, последовательность тестированных знаков может быть возвращена. Кроме того, могут быть возвращены один или несколько синонимов. Эти синонимы могут быть определены на основе их соответствующих оценок баллов и могут быть возвращены вместе или без соответствующей оценки в баллах. Синонимы, связанные с конкретным прогнозом, могут храниться в листе дерева, соответствующем прогнозу. Чтобы продолжать этот пример, лист 1020, соответствующий тестированному прогнозу, может сохранять различные синонимы тестированного слова, включая тестер, тест, тесла и т.д. Эти синонимы слова тестированный могут быть возвращены вместе с последовательностью символов, соответствующих прогнозу тестировано. В одном конкретном варианте структура для сохранения модели использования 280 этого типа и соответствующей логики для обработки ввода и вычисления оценки в баллах или вероятностей может быть представлена следующим образом. Примечание. GetUNodeFromPath возвращается в UsageModel (модель использования), связанную с последовательностью, выданной как аргумент, если она существует, в противном случае возвращается константа UnknownPath (неизвестный тракт). Примечание. GetSuggestion получает слова и их синонимы с заданным префиксом. Каждое слово и синоним связаны с оценкой баллов, означающей их частоту использования в модели использования 280. Как показано на фиг. 7, базовая логика затем может формировать выход (блок 730), основанный на обработке ввода, как обсуждено выше. Этот выход может быть последовательностью знаков или последовательностью знаков с набором опций меню. Этот выход (блок 730) затем может быть представлен пользователю для дальнейшего взаимодействия. В одном варианте базовая логика 250 может взаимодействовать с модулем семантизации 240, чтобы представить сформулированный выход (блок 730) как предложение пользователю. Отметим, что не все описанные таблицы, поля или стадии необходимы для работы устройства, поскольку эти таблицы, поля или стадии могут не понадобиться, и что дополнительные таблицы, поля или стадии могут быть добавлены к вышеописанным. Кроме того, порядок, в котором они описаны, не обязательно должен соответствовать порядку их фактического действия. После прочтения настоящего описания специалистам в данной области легко определить, какие таблицы, поля или стадии наиболее отвечают достижению конкретных целей. Настоящее изобретение описано на конкретных примерах. Однако любой специалист понимает, что могут быть сделаны различные модификации и изменения, не выходя из объема изобретения, охваченного приведенной ниже формулой изобретения. Соответственно, описание и чертежи должны рассматриваться как иллюстративный, а не ограничивающий материал и все такие изменения и модификации включены в объем изобретения. Полезные особенности, преимущества и решения проблем описаны выше применительно к конкретным вариантам. Однако эти полезные особенности, преимущества и решения проблем и любые компоненты, которые могут быть более совершенными, не должны рассматриваться как критические, требуемые или существенные особенности или компоненты всех или отдельных пунктов патентования формулы изобретения. ФОРМУЛА ИЗОБРЕТЕНИЯ 1. Способ интерфейса для ввода данных, содержащий обнаружение ввода относительно интерфейса, в котором обнаружение ввода содержит обнаружение нажатия в первой зоне ряда зон, в которой по меньшей мере один ряд зон не является примыкающим по меньшей мере к одному другому ряду зон и по меньшей мере один из ряда зон отличается по форме по меньшей мере от одного другого ряда зон; обнаружение освобождения во второй зоне ряда зон и обнаружение движения между нажатием и освобождением, в котором обнаружение движения дополнительно включает обнаружение входа или выхода одного или нескольких рядов зон между нажатием в первой зоне и освобождением во второй зоне,при поддержании контакта с интерфейсом между нажатием в первой зоне и освобождением во второй зоне; и установление связи семантического значения с вводом, основанным на ряде семантических значений, связанных с первой зоной, в котором семантическое значение выбрано из ряда семантических значений, связанных с первой зоной, основанной на второй зоне. 2. Способ по п.1, в котором связь семантического значения с вводом включает группирование каждого из ряда зон в один из рядов зон выбора, в котором каждый ряд зон выбора связан с соответствующим рядом семантических значений, связанных с первой зоной; и- 18011145 определение, с каким из рядов зон выбора связана вторая зона. 3. Способ по п.2, в котором каждый ряд семантических значений отображен на интерфейсе в связи с первой зоной, в котором каждый ряд семантических значений отображен на соответствующем месте первой зоны и каждый из ряд зон выбора связан одним из соответствующих мест. 4. Способ по п.1, в котором ряд зон содержит ряд межклавишных зон и ряд клавишных зон, в котором никакие две клавишные зоны не являются смежными и каждая клавишная зона является смежной по меньшей мере с одной межклавишной зоной ряда зон. 5. Способ по п.4, в котором ряд зон выполнен в виде набора рядов. 6. Способ по п.5, в котором набор рядов формирует по меньшей мере одну концентрическую кривую. 7. Способ по п.6, в котором каждый ряд имеет клавишную зону на каждом конце и имеет межклавишную зону рядом с каждой клавишной зоной в ряду. 8. Способ по п.7, в котором каждая межклавишная зона перекрывает по меньшей мере две соседние клавишные зоны, к которым она примыкает. 9. Способ по п.8, в котором каждая часть каждой межклавишной зоны связана по меньшей мере с одной из двух соседних клавишных зон, к которым она примыкает. 10. Способ по п.9, в котором указанная связь основана на движении. 11. Способ по п.1, дополнительно включающий формирование дискретного сообщения, содержащего первую зону, соответствующую начальному нажатию, и вторую зону, соответствующую освобождению. 12. Способ по п.11, в котором связь семантического значения основана на дискретном сообщении. 13. Система интерфейса для ввода данных, содержащая датчик, имеющий ряд зон, в котором по меньшей мере один из рядов зон не примыкает по меньшей мере к одному из другого ряда зон и по меньшей мере один из рядов зон отличается по форме по меньшей мере от одного другого ряда зон, при этом датчик выполнен с возможностью обнаружения ввода относительно интерфейса, в котором обнаружение ввода включает обнаружение нажатия в первой зоне ряда зон, обнаружение освобождения во второй зоне ряда зон и обнаружение движения между нажатием и освобождением, причем обнаружение движения дополнительно включает обнаружение входа или выхода из одного или большего количества рядов зон между нажатием в первой зоне и освобождением во второй зоне, при этом поддерживается контакт с интерфейсом между нажатием в первой зоне и освобождением во второй зоне; и логический модуль, служащий для связи семантического значения с вводом, на основе ряда семантических значений, связанных с первой зоной, в котором семантическое значение выбрано из ряда семантических значений, связанных с первой зоной, основанной на второй зоне. 14. Система по п.13, в которой связь семантического значения с вводом включает группирование каждого ряда зон в один из ряда зон выбора, в котором каждый ряд зон выбора связан с соответствующим рядом семантических значений, связанных с первой зоной; и определение, с каким рядом зон выбора связана вторая зона. 15. Система по п.14, в которой каждый ряд семантических значений отображен на интерфейсе в связи с первой зоной, в которой каждый ряд семантических значений отображен на соответствующем месте первой зоны и каждый ряд зон выбора соответствует одному из соответствующих мест. 16. Система по п.13, в которой ряд зон содержит ряд межклавишных зон и ряд клавишных зон, в которой никакие две клавишные зоны не являются смежными и каждая клавишная зона является смежной по меньшей мере с одной межклавишной зоной. 17. Система по п.16, в которой ряд зон выполнен в ряде набора рядов. 18. Система по п.17, в которой набор рядов формирует по меньшей мере одну концентрическую кривую. 19. Система по п.18, в которой каждый ряд имеет клавишную зону на каждом конце и имеет межклавишную зону рядом с каждой клавишной зоной в ряду. 20. Система по п.19, в которой каждая клавишная зона перекрывает по меньшей мере две соседние клавишные зоны, к которым она примыкает. 21. Система по п.20, в которой каждая часть каждой межклавишной зоны связана по меньшей мере с одной из двух соседних клавишных зон, к которым она примыкает. 22. Система по п.21, в которой указанная связь основана на движении. 23. Система по п.13, в которой логический модуль служит для формирования дискретного сообщения, содержащего первую зону, соответствующую начальному нажатию, и вторую зону, соответствующую освобождению. 24. Система по п.23, в которой логический модуль служит для связи семантического значения с дискретным сообщением.
МПК / Метки
МПК: G06F 3/023
Метки: система, данных, ввода, интерфейса, способ
Код ссылки
<a href="https://eas.patents.su/26-11145-sposob-i-sistema-vvoda-dannyh-dlya-interfejjsa.html" rel="bookmark" title="База патентов Евразийского Союза">Способ и система ввода данных для интерфейса</a>
Устройство и система для усовершенствованного ввода данных в миниатюрное устройство ввода данных

Номер патента: 9109
Опубликовано: 26.10.2007
Автор: Гассабиан Бенджамин Фируз
МПК: G09G 5/00, H04B 1/38, G09G 5/08...
Метки: усовершенствованного, миниатюрное, данных, система, устройство, ввода
Формула / Реферат:
1. Система ввода данных для введения символов при помощи средств ввода данных типа клавиатуры, в которой предопределенное количество символов составляет по меньшей мере две группы символов, причем первая группа символов содержит, в основном, часто используемые символы, такие как, по меньшей мере, буквенно-цифровые символы языка, а вторая группа символов содержит, в основном, менее часто используемые символы, при этом указанные символы присвоены...
Способ обработки данных, устойчивый к извлечению данных с помощью анализа непреднамеренных сигналов побочного ввода-вывода

Номер патента: 3874
Опубликовано: 30.10.2003
Автор: Вон Виллих Манфред
Метки: анализа, сигналов, устойчивый, способ, данных, обработки, непреднамеренных, ввода-вывода, извлечению, побочного, помощью
Формула / Реферат:
1. Способ обработки данных для снижения риска неуполномоченного доступа к данным, характеризующийся следующими шагами: (a) ввод начального секретного набора данных в процессор, включая возможное последующее повторение этого шага; (b) обеспечение процессора источником непредсказуемых данных; (c) обеспечение процессора способом выбора отображений от первоначальных данных до отображенных данных, используя непредсказуемые данные (b), в котором...
Координатно-указательное устройство ввода данных в компьютер, управляемое с помощью большого пальца

Номер патента: 2610
Опубликовано: 27.06.2002
Автор: Шипмэн Дейл Г.
МПК: G09G 5/08
Метки: большого, устройство, координатно-указательное, управляемое, ввода, пальца, данных, компьютер, помощью
Формула / Реферат:
1. Координатно-указательное устройство ввода данных в компьютер, предназначенное для генерации сигналов управления позицией, сигналов ввода и положения переключателя, для передачи информации в компьютер, чувствительный к плавным перемещениям устройства по плоской поверхности, в котором переключатель приводится в действие пользователем, включающее (a) корпус с традиционно плоской нижней поверхностью для плавного контакта с плоской поверхностью,...
Система и способ использования администратора данных рабочей области для доступа, обработки и синхронизации сетевых данных

Номер патента: 2411
Опубликовано: 25.04.2002
Автор: Мендез Дэниел Дж.
МПК: G06F 17/30
Метки: сетевых, использования, данных, рабочей, доступа, способ, обработки, синхронизации, области, администратора, система
Формула / Реферат:
1. Способ синхронизации данных с удаленной станцией, базирующийся на использовании компьютера, заключающийся в том, что загружают данные из удаленной станции, запрашивают администратора данных рабочей области о разрешении обработки данных и создают тем самым обработанные данные и синхронизируют обработанные данные с данными, хранящимися в удаленной станции. 2. Способ по п.1, отличающийся тем, что дополнительно осуществляют запрос администратора...
Система, способ и устройство для загрузки текстовых данных в базу данных

Номер патента: 10400
Опубликовано: 29.08.2008
Авторы: Сингх Амар, Гупта Атул
МПК: G06F 17/30
Метки: текстовых, данных, загрузки, устройство, система, способ, базу
Формула / Реферат:
1. Устройство для загрузки данных из набора данных электронной таблицы, имеющей данные в форме одной или более записей, в базу данных, заключающее в себе: a) управляющий файл, содержащий набор правил для описания соответствия между атрибутами упомянутого набора данных электронной таблицы и атрибутами упомянутой базы данных, причем каждое правило содержит условие; b) загрузчик электронной таблицы, имеющий в качестве входных данных набор данных...
Следующий патент: Способ прямого непрерывного изготовления полых тел из полимерного расплава
Случайный патент: Беспроводная сейсмическая система для поисково-разведочных работ