Система и способ моделирования голоса конкретных людей

















Формула / Реферат
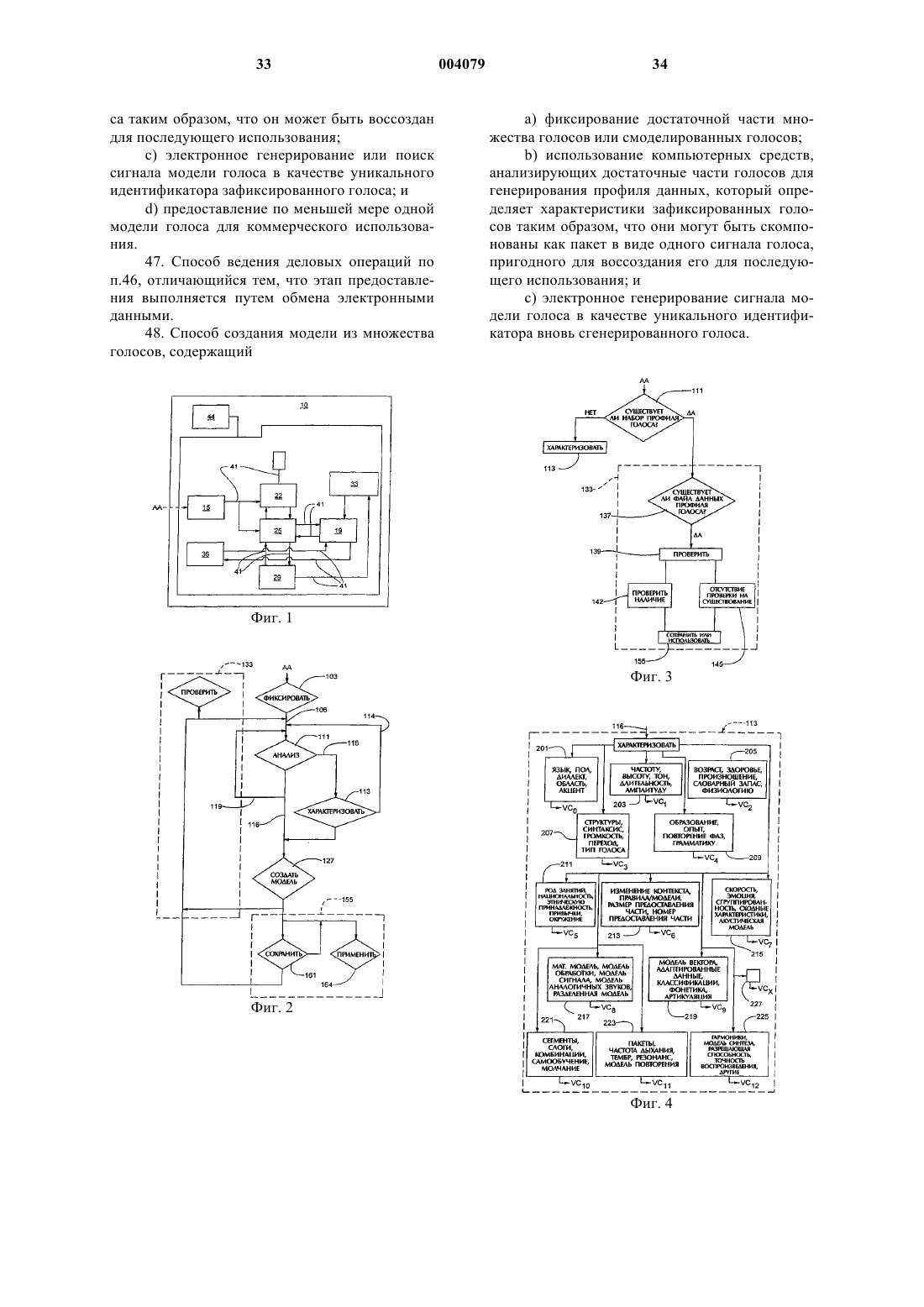
1. Система, предназначенная для фиксирования части конкретного голоса, достаточной для использования этой части в качестве модели, пригодной для последующего генерирования не сказанных ранее слов и фраз при дальнейшем использовании голоса, содержащая
a) средство для фиксирования достаточной части голоса в форме, пригодной для анализа в качестве характеристик голоса;
b) средство анализа, предназначенное для приема и анализа зафиксированного голоса и для характеризации элементов зафиксированного голоса в качестве данных характеристик так, что эти данные характеристик являются достаточными для уникальной характеристики и воссоздания зафиксированного голоса в форме ранее несказанных выражений указанным зафиксированным голосом;
c) средство хранения, предназначенное для приема данных характеристик из средства анализа для конкретного зафиксированного голоса; и
d) средство извлечения, предназначенное для извлечения данных анализа и данных характеристик для дальнейшего использования при генерировании звучания смысловых выражений, аналогичного звучанию зафиксированного голоса, но никогда ранее не сказанного им.
2. Система по п.1, отличающаяся тем, что средство, предназначенное для фиксирования голоса, содержит средство цифровой записи.
3. Система по п.1, отличающаяся тем, что средство для фиксирования голоса содержит карту флэш-памяти.
4. Система по п.1, отличающаяся тем, что средство фиксирования голоса содержит средство аналоговой записи.
5. Система по п.1, отличающаяся тем, что средство фиксирования голоса содержит средство ввода, предназначенное для приема живого голоса и для передачи этого живого голоса в средство анализа.
6. Система по п.1, отличающаяся тем, что средство анализа содержит средство записи цифровых данных.
7. Система по п.1, отличающаяся тем, что средство анализа содержит средство, предназначенное для идентификации конкретной структуры, синтаксиса, частоты, высоты и тонов речи в данных зафиксированного голоса.
8. Система по п.1, отличающаяся тем, что средство анализа содержит средство, предназначенное для идентификации конкретного словарного запаса, произношения или акцента, уникального зафиксированного голоса.
9. Система по п.1, отличающаяся тем, что средство анализа содержит средство, предназначенное для идентификации определенных свойств, уникальных для зафиксированного голоса, получаемых на основе конкретной анатомической структуры реального обладателя голоса.
10. Система по п.1, отличающаяся тем, что средство анализа содержит средство, предназначенное для определения словарного запаса реального обладателя зафиксированного голоса.
11. Система по п.10, отличающаяся тем, что средство анализа содержит средство, предназначенное для установки данных словарного запаса и данных характеристик для использования при формировании моделируемого в будущем голоса.
12. Система по п.1, отличающаяся тем, что средство анализа содержит устройство цифровой обработки, предназначенное для цифровой обработки данных, вводимых в форме голоса или цифрового представления записанного голоса.
13. Система по п.1, отличающаяся тем, что средство анализа содержит второе средство ввода, предназначенное для приема дополнительных данных, относящихся к физиологии реального обладателя голоса.
14. Система по п.13, отличающаяся тем, что средство второго ввода средства анализа содержит средство процессора цифрового сигнала, которое позволяет избирательно принимать звуковые или другие данные, содержащие информацию визуализации в отношении морфологии реального обладателя голоса.
15. Система по п.1, отличающаяся тем, что средство анализа содержит средство сравнения, предназначенное для сравнения набора данных входного голоса с записанными данными, содержащими данные возраста, данные языка, данные образования, данные пола, данные рода занятий, данные об акценте, данные о национальности, этнические данные, данные о типе голоса, данные о привычках и данные об окружении.
16. Система по п.1, отличающаяся тем, что средство анализа содержит третье средство ввода, предназначенное для приема данных, относящихся к реальному обладателю голоса, содержащих данные возраста, данные образования, данные пола, данные о роде занятий, данные об акценте, данные о национальности, этнические данные, данные о типе голоса, данные о привычках, данные о языке и данные об окружении.
17. Способ создания звуков, похожих на голос, которые идентичны по звучанию голосу данного конкретного человека, содержащий следующие этапы:
a) фиксирование достаточной части голоса конкретного человека для записи и использования;
b) запись достаточной части голоса конкретного человека;
c) анализ достаточной части голоса для идентификации существенных компонентов или характеристик зафиксированного голоса; и
d) использование идентифицированных существенных компонентов или характеристик для создания нового голоса, который при установлении данных из одной или большего количества средств базы данных и последующем прослушивании звучит идентично во всех отношениях голосу конкретного человека для слушателя, имеющего нормальные способности слухового различения.
18. Способ по п.17, отличающийся тем, что этап анализа содержит этапы идентификации компонентов в зафиксированной достаточной части голоса конкретного человека, относящихся по меньшей мере к одному из компонентов, включающих частоту, тон, высоту, громкость, акцент, пол, гармоническую структуру, акустическую мощность, фонетический или временной акцент, энергичность и периодичность.
19. Способ по п.18, отличающийся тем, что этап фиксирования достаточной части голоса конкретного человека, предназначенного для записи и использования, включает фиксирование звука, генерируемого гортанью, либо звука, генерируемого турбулентностью голоса конкретного человека.
20. Способ точного копирования голоса человека, содержащий следующие этапы:
a) идентификацию набора данных минимального размера, содержащего комбинацию слов, звуков или фраз, которые должны быть произнесены реальным обладателем голоса для копирования;
b) фиксирование при произношении комбинации слов, звуков или фраз реального обладателя голоса, который должен быть скопирован на носителе;
c) анализ зафиксированного произношения для идентификации характеристик голоса реального обладателя голоса, достаточных для обеспечения искусственного генерирования голоса с использованием идентифицированной характеристики, так, чтобы искусственно сгенерированный голос был, по существу, идентичным во всех отношениях для слушателя, имеющего нормальные способности слухового различения, когда такой слушатель слышит сгенерированный голос с использованием некоторых компонентов языка, не содержащихся в зафиксированном произношении действительного голоса реального его обладателя.
21. Изделие, содержащее
a) носитель записи, используемый в компьютере, имеющий средство программного кода, считываемого компьютером, которое установлено в нем для создания копии голоса человека, причем средство программного кода, считываемого компьютером, в указанном изделии содержит
b) средство программного кода, считываемого компьютером, предназначенное для выполнения компьютером анализа зафиксированной достаточной части голоса реального обладателя для идентификации данных характеристик голоса, достаточных для обеспечения искусственного генерирования голоса; и
c) средство программного кода, считываемого компьютером, предназначенное для использования данных характеристик идентифицированного голоса для искусственного генерирования голоса так, чтобы искусственно сгенерированный голос был, по существу, идентичен по звучанию и использованию для пользователя, когда слушатель слышит сгенерированный голос, в котором используются некоторые компоненты языка, не содержащиеся в зафиксированной речи действительного голоса реального его обладателя.
22. Изделие по п.21, отличающееся тем, что дополнительно содержит средство программного кода, считываемого компьютером, предназначенное для запшёш сгенерированного голоса для последующего использования.
23. Изделие по п.21, отличающееся тем, что дополнительно содержит средство программного кода, считываемого компьютером, предназначенное для использования данных характеристик голоса для создания профиля голоса реального его обладателя.
24. Изделие по п.21, дополнительно содержащее средство программного кода, считываемого компьютером, предназначенное для обеспечения доступа к средству базы данных, предназначенному для записи данных, содержащих данные о возрасте, данные об образовании, данные, относящиеся к полу, данные о роде занятий, данные об акценте, данные о языке, национальности, этнические данные, данные о типе голоса, данные о привычках, общие данные и данные об окружении.
25. Компьютерный программный продукт, предназначенный для использования с устройством акустического вывода, причем указанный компьютерный программный продукт содержит
a) средство программного кода, считываемого компьютером, воплощенное в нем для копирования голоса человека через выводное акустическое устройство, причем компьютерный программный продукт содержит
b) средство программного кода, считываемого компьютером, предназначенное для выполнения компьютером анализа зафиксированной достаточной части голоса реального обладателя для идентификации данных характеристик голоса, достаточных для обеспечения искусственного генерирования голоса; и
c) средство программного кода, считываемого компьютером, предназначенное для использования идентифицированных данных характеристик голоса для искусственного генерирования и вывода голоса через акустическое выводное устройство так, чтобы искусственно сгенерированный голос был, по существу, идентичен по звучанию и использованию для слушателя, когда слушатель слышит сгенерированный голос с использованием некоторых компонентов языка, не содержащихся в зафиксированной речи действительного голоса реального его обладателя.
26. Компьютерный программный продукт, предназначенный для использования с устройством отображения, причем указанный компьютерный программный продукт содержит
a) средство программного кода, считываемого компьютером, установленное в нем, предназначенное для копирования голоса человека и проверки точности копируемого голоса с отображением на устройстве отображения, причем компьютерный программный продукт содержит
b) средство программного кода, считываемого компьютером, предназначенное для выполнения компьютером анализа зафиксированной достаточной части голоса реального его обладателя для идентификации данных характеристики голоса, достаточных для выполнения искусственного генерирования голоса; и
c) средство программного кода, считываемого компьютером, предназначенное для использования идентифицированных данных характеристики голоса для искусственного генерирования голоса и для сравнения характеристики сгенерированного голоса с голосом реального его обладателя на устройстве отображения так, чтобы искусственно сгенерированный голос был, по существу, идентичен по звучанию для слушателя, когда устройство отображения индицирует это и когда слушатель в действительности слышит сгенерированный голос с использованием некоторых компонентов языка, не содержащихся в зафиксированной речи действительного голоса реального его обладателя.
27. Компьютерный программный продукт, предназначенный для использования с акустическим выводным устройством, причем указанный компьютерный программный продукт содержит
a) средство программного кода, считываемого компьютером, установленное в нем, предназначенное для запуска копирования голоса человека через выходное акустическое устройство, причем компьютерный программный продукт содержит
b) средство программного кода, считываемого компьютером, предназначенное для приема и активации компьютером файла данных характеристик голоса, уникальных для конкретного голоса, достаточных для обеспечения искусственного генерирования голоса; и
c) средство программного кода, считываемого компьютером, предназначенное для использования идентифицированных данных характеристик голоса для искусственного генерирования выходного голоса через акустическое выводное устройство так, чтобы искусственно сгенерированный голос был, по существу, идентичен по звучанию для слушателя, когда слушатель слышит сгенерированный голос и зафиксированную речь действительного голоса реального его обладателя.
28. Компьютерный программный продукт, предназначенный для использования с электронным устройством, причем указанный компьютерный программный продукт содержит
a) средство программного кода, считываемого компьютером, установленное в нем для запуска копирования голоса человека, причем компьютерный программный продукт содержит
b) средство программного кода, считываемого компьютером, предназначенное для приема и активирования файла данных характеристик голоса, уникальных для конкретного голоса, достаточных для обеспечения искусственного генерирования голоса; и
c) средство программного кода, считываемого компьютером, предназначенное для использования идентифицированного файла данных характеристик голоса и звукового вывода средства генерирования звука для искусственного генерирования голоса так, чтобы искусственно сгенерированный голос был, по существу, идентичен по звучанию действительному голосу реального его обладателя.
29. Запоминающее устройство, предназначенное для записи данных, предназначенных для обеспечения доступа к программному приложению, выполняемое на подсистеме обработки данных, содержащее
a) структуру данных, записанную в указанном запоминающем устройстве, причем указанная структура данных включает информацию, размещенную в базе данных, используемую указанным программным приложением и включающую
b) по меньшей мере один файл данных достаточной части голоса, записанный в указанном запоминающем устройстве, причем каждый из указанных наборов файлов данных достаточной части голоса, содержит информацию, по существу, отличающуюся от любого другого набора файла данных достаточной части голоса;
c) множество файлов данных характеристик голоса, содержащих различную справочную информацию для множества характеристик голоса; и
d) множество наборов профилей голоса, каждый из которых содержит по меньшей мере один файл данных профиля голоса, содержащий данные, уникальные только для этого файла данных, в котором структура данных позволяет осуществлять доступ к файлам данных характеристик голоса и файлам данных профиля голоса для выполнения операции сравнения по меньшей мере с одним файлом достаточной части голоса.
30. Система обработки данных, выполняющая программное приложение и содержащая базу данных, используемую для указанного программного приложения, причем указанная система обработки данных содержит
a) средство ЦПУ, предназначенное для обработки указанного программного приложения; и
b) запоминающее средство, предназначенное для хранения структуры данных, предназначенных для осуществления доступа указанным программным приложением, причем указанная структура данных состоит из информации, находящейся в базе данных, используемой указанным программным приложением и включающей
по меньшей мере один файл данных достаточной части голоса, записанный в указанном запоминающем устройстве, причем каждый из набора файлов данных достаточной части голоса содержит информацию, по существу, отличающуюся от любого набора файла данных достаточной части голоса;
множество файлов данных характеристик голоса, содержащих различную справочную информацию для множества характеристик голоса;
множество наборов профиля голоса, каждый из которых содержит по меньшей мере один файл данных профиля голоса, содержащий данные, уникальные только для этого файла данных; и
c) в которой система обработки данных позволяет осуществлять доступ к файлам данных характеристик голоса и файлам данных профиля голоса для выполнения операции сравнения по меньшей мере с одним файлом данных достаточной части голоса.
31. Сигнал компьютерных данных, воплощенный в средстве передачи, содержащий
a) код источника кодирования для уникальной модели профиля голоса, используемый для кодирования дополнительного электронного звука для создания конкретного генерированного голоса; и
b) код кодирования источника в определенном месте положения и сконфигурированный таким образом, чтобы код источника кодирования мог быть съемным из носителя информации для использования в качестве ключа, для создания сгенерированного голоса.
32. Способ использования выбранного голоса в качестве персонального голосового помощника с электронным устройством, содержащий следующие этапы:
a) включение электронного средства для осуществления доступа к удаленной базе данных;
b) передачу части сигнала в удаленную базу данных, содержащую базу данных голоса, содержащую множество наборов профилей голоса, каждый из которых имеет по меньшей мере один файл данных профиля голоса, содержащий данные, уникальные только для этого файла данных и идентифицируемый уникальным идентификатором;
c) передачу части сигнала в удаленную базу данных для уникальной идентификации требуемого файла данных и затем для выполнения передачи содержания файла данных в определенное пользователем местоположение электронного устройства; и
d) выполнение использования выбранного и переданного файла данных в качестве модели голоса, в комбинации с соответствующим звуком, сгенерированным либо электронным устройством, либо другим средством, предназначенным для генерирования такого звука, так, чтобы, как требуется для пользователя, он мог принимать звук от электронного устройства в виде звука выбранного голоса, как определено идентифицированным голосом.
33. Способ по п.32, отличающийся тем, что файл данных включает характеристики данных выбранного голоса, скомпонованного в виде средства программного кода, считываемого компьютером, для использования данных, характеризирующих идентифицированный голос, для искусственного генерирования модели голоса.
34. Способ по п.32, отличающийся тем, что этап воплощения включает использование средства идентификации для того, чтобы позволить только идентифицированным пользователям осуществлять доступ и использовать технологии и данные моделирования голоса.
35. Способ по п.32, отличающийся тем, что этап воплощения содержит применение средств проверки с избирательным доступом для проверки того, что слышимый голос является либо реальным голосом, либо сгенерированной моделью.
36. Способ осуществления деловых операций, в котором используется система, предназначенная для фиксирования части конкретного голоса, достаточной для использования этой части в качестве модели, пригодной для последующего генерирования ранее невысказанных слов и фраз при дальнейшем использовании голоса, содержащий следующие этапы:
a) фиксирование достаточной части голоса в форме, используемой для анализа в качестве характеристик голоса;
b) ввод достаточной части в модуль анализа для получения характеризирующих элементов зафиксированного голоса в качестве данных характеристик так, чтобы данные характеристик были достаточными для уникальной характеристики и воссоздания зафиксированного голоса в виде невысказанных ранее слов и фраз указанным зафиксированным голосом;
c) прием данных характеристик из модуля анализа для конкретного зафиксированного голоса; и
d) запись данных характеристик для последующего использования при генерировании слов и фраз, звучащих как зафиксированные голосом, но никогда ранее им не высказанные.
37. Способ по п.36, отличающийся тем, что средство, предназначенное для фиксирования голоса, содержит средство цифрового ввода.
38. Способ по п.36, отличающийся тем, что достаточная часть голоса принимается в электронном виде.
39. Способ по п.36, отличающийся тем, что данные характеристик упакованы для формирования сигнала модели голоса, используемой для комбинирования с генерируемым звуком для создания смоделированного голоса, который звучит так же, как конкретный реальный голос.
40. Способ по п.36, отличающийся тем, что смоделированный голос управляется таким образом, чтобы обеспечить возможность приема команд голосового ввода в смоделированный голос для произношения новых слов с помощью смоделированного голоса, которые, однако, не были введены конкретным голосом.
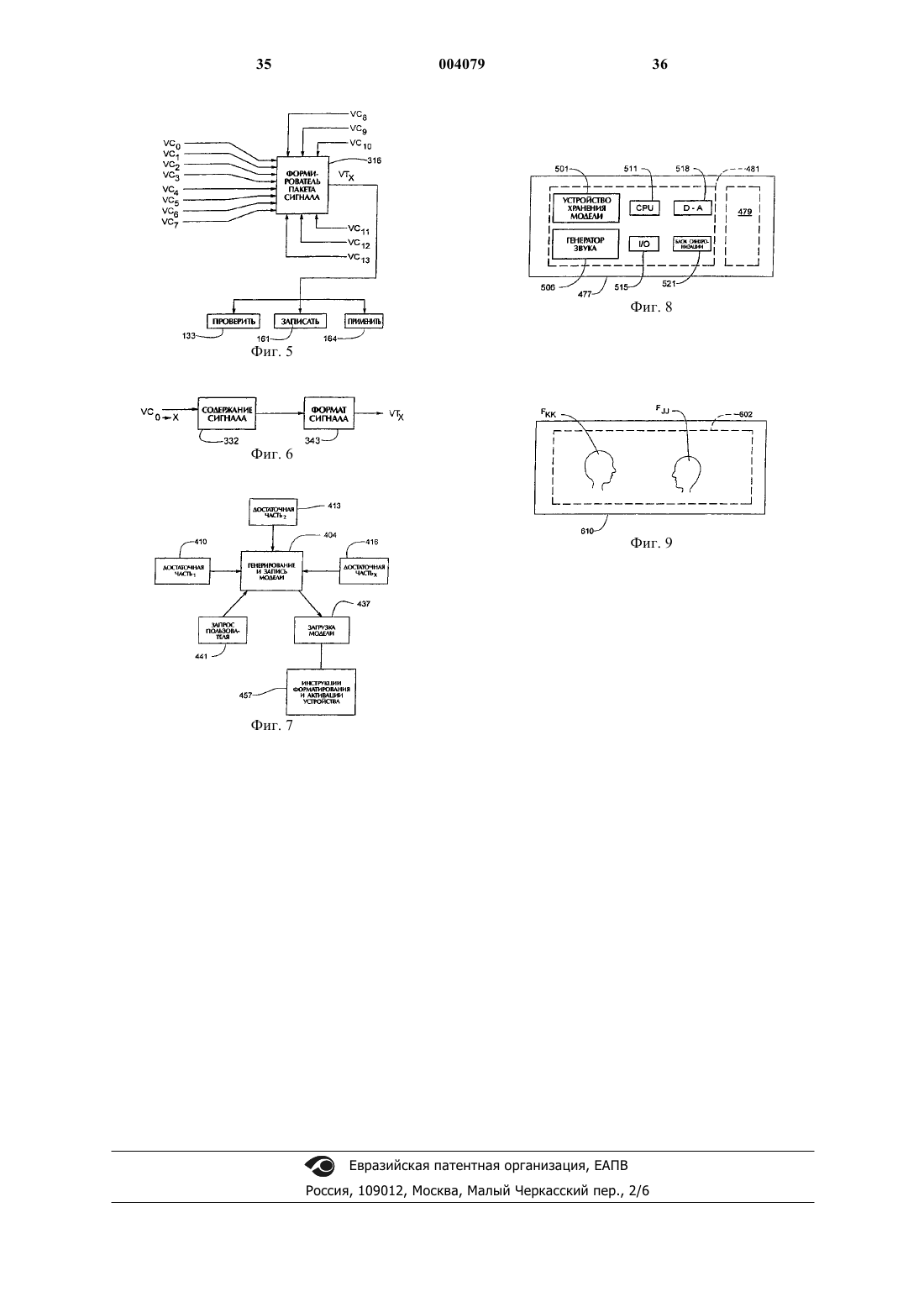
41. Автоматизированное устройство, предназначенное для фиксирования достаточной части конкретного голоса и для использования этой части в качестве модели, используемой для последующего использования смоделированного голоса, содержащее
a) модуль получения, предназначенный для получения достаточной части голоса в форме, используемой для анализа с получением характеристик голоса;
b) модуль анализа, предназначенный для приема и анализа зафиксированного голоса и для получения характеризирующих элементов зафиксированного голоса в качестве данных характеристик; и
c) модуль генератора модели, предназначенный для автоматического генерирования сигнала модели голоса в качестве уникального идентификатора приобретенного конкретного голоса, но так, чтобы указанный сигнал модели голоса содержал данные, отличающиеся от конкретных слов, высказанных голосом, из которого была сформирована позволяющая часть.
42. Устройство по п.41, отличающееся тем, что дополнительно содержит средство связи, предназначенное для связи со средством накопления для приема данных характеристик из базы данных.
43. Устройство по п.41, отличающееся тем, что дополнительно содержит средство связи, предназначенное для связи со средством накопления для хранения сгенерированной модели до поступления соответствующего запроса.
44. Интерактивный способ, предназначенный для создания моделей голоса и генерирования оплаты за такое генерирование, содержащий
a) фиксирование достаточной части конкретного голоса;
b) анализ достаточной части конкретного голоса для генерирования профиля данных, который определяет характеристики зафиксированного голоса так, чтобы можно было его воссоздать для последующего использования;
c) генерирование сигнала модели голоса в качестве уникального идентификатора приобретенного конкретного голоса; и
d) предоставление по меньшей мере одного сгенерированного профиля данных для коммерческого использования другим лицам.
45. Способ, выполняемый устройством, предназначенный для создания модели голоса и генерирования оплаты за такое генерирование, содержащий
a) фиксирование достаточной части конкретного голоса;
b) анализ достаточной части конкретного голоса для генерирования профиля данных, который определяет характеристики зафиксированного голоса таким образом, что он может быть воссоздан для последующего использования;
c) используя профиль данных, генерирование сигнала модели голоса в качестве уникального идентификатора, зафиксированного конкретного голоса; и
d) предоставление по меньшей мере одного сигнала модели голоса для коммерческого использования.
46. Способ ведения деловых операций, предназначенный для создания модели голоса, содержащий
a) фиксирование достаточной части конкретного голоса или смоделированного голоса;
b) использование компьютерных средств, анализирующих достаточную часть голоса для генерирования профиля данных, который определяет характеристики зафиксированного голоса таким образом, что он может быть воссоздан для последующего использования;
c) электронное генерирование или поиск сигнала модели голоса в качестве уникального идентификатора зафиксированного голоса; и
d) предоставление по меньшей мере одной модели голоса для коммерческого использования.
47. Способ ведения деловых операций по п.46, отличающийся тем, что этап предоставления выполняется путем обмена электронными данными.
48. Способ создания модели из множества голосов, содержащий
a) фиксирование достаточной части множества голосов или смоделированных голосов;
b) использование компьютерных средств, анализирующих достаточные части голосов для генерирования профиля данных, который определяет характеристики зафиксированных голосов таким образом, что юэш могут быть скомпонованы как пакет в виде одного сигнала голоса, пригодного для воссоздания его для последующего использования; и
c) электронное генерирование сигнала модели голоса в качестве уникального идентификатора вновь сгенерированного голоса.

Текст
1 Область техники Системы, способы и продукты, предназначенные для сохранения и адаптации звука, и в частности голоса людей. Предпосылки изобретения С древних времен млекопитающие и другие существа сообщались друг с другом в определенной форме с помощью голоса или аналогичных звуков. Действительно, такие звуки обычно вполне различимы ввиду различий в морфологии живых существ даже в пределах одного вида. Различия между живыми существами включают в значительной степени отличительные элементы структуры речи и тонов. К сожалению, возможность слышать речь другого человека, голос которого представляет особый интерес, утрачивается, когда этот человек умирает или теряет контакт со слушателем. В настоящее время разработаны только начальные формы фиксирования звука на носителях информации, с помощью которых могут быть сохранены голоса. Например, устройство записи на ленте или устройство цифровой записи используют для записи голоса человека и,таким образом, для сохранения его для будущего прослушивания и воспроизведения в том виде, как он был изначально записан, или для прослушивания частей исходной записи по желанию. Эти устройства и способы записи голоса также включают некоторый набор искусственно синтезированных голосов, созданных с помощью компьютера, которые могут использоваться для выполнения различных функций, включая, например, автоматические телефонные услуги и проверку, очень примитивный разговор между игрушками или оборудованием и пользователем, синтезированные голоса для фильмов,использование в индустрии развлечений и т.п. В некоторых приложениях такие искусственные голоса заранее программируют на узкий набор ответов в соответствии с конкретной вводимой информацией. Хотя такой искусственный голос в некоторых случаях позволяет получить более осмысленные ответы, чем при использовании простой записи реального голоса, звучание искусственного голоса, однако, остается простым по сравнению с возможностями реально звучащего голоса в соответствии с настоящим изобретением. Действительно, в некоторых вариантах воплощения настоящего изобретения присутствуют элементы, существенно отличающиеся от таких систем, или в них известная технология используется далеко за пределами того,что рассматривается или даже предполагается в известных открытиях или нововведениях. Во многих публикациях, выходящих во всем мире, описаны аспекты искусственной вокализации. Аналогично в некоторых ссылочных документах описаны системы и технологии,направленные на использование и создание звуков искусственного голоса. Однако ни в одном из этих ссылочных документов не описаны кон 004079 2 цепции, раскрытые в соответствии с настоящим изобретением. Краткое описание изобретения В настоящем изобретении предложены системы и способы, предназначенные для записи или фиксирования другим путем достаточного количества звучания голоса определенного человека для формирования модели структуры голоса. Эту модель затем используют в качестве инструмента для построения звучания нового разговора, озвученного точно тем же голосом,причем этот новый разговор, вероятно, никогда не был в действительности произнесен или никогда не был произнесен в точном контексте или с использованием точно таких фраз этим конкретным человеком, но в действительности звучит во всех аспектах идентично реальной речи данного человека. Достаточную часть рассчитывают таким образом, чтобы зафиксировать элементы реального голоса, необходимые для реконструкции этого реального голоса, при этом существует методика доверительной оценки, с помощью которой можно рассчитать ограничения реконструированного или воссозданного разговора, в случае, когда отсутствует достаточно большой отрезок речи, на основе которого можно начать моделирование. Новый голос или голоса могут использоваться совместно с базой данных с учетом определенной темы, исторических данных и с использованием модулей адаптивного или искусственного интеллекта для обеспечения возможности построения нового разговора с пользователем, так как если бы присутствовал реальный обладатель смоделированного голоса. Такая система и способ могут использоваться совместно с другими носителями информации, такими как программные файлы,сервисная программа, записанная в микросхеме,или носителями информации в других формах. Интерактивное использование такой системы и способа может быть организовано различным образом. Сам отдельный модуль может содержать полностью один из вариантов воплощения настоящего изобретения, например, в виде микросхемы или электронной схемы, которая сконфигурирована для фиксирования и предоставления возможности использовать голос, таким образом, как описано в настоящем описании. Модель используется, например, как инструмент для фиксирования и создания новых диалогов с людьми, непосредственный доступ к которым отсутствует, которые, возможно, умерли, или даже с лицами, которые дали разрешение на моделирование и использование своих голосов таким образом. Другой пример представляет собой использование в средствах массовой информации, например в фильмах или в фотографии или других средствах изображения,действительного голоса (голосов) реального обладателя для создания по запросу виртуального диалога с реальным обладателем. Различные другие варианты использования и примене 3 ния рассматриваются в пределах объема настоящего изобретения. Краткое описание чертежей Фиг. 1 изображает схему алгоритма в соответствии с одним из вариантов воплощения последовательности работы системы в соответствии с настоящим изобретением. Фиг. 2 - схему одного из вариантов воплощения подсистемы фиксирования голоса. Фиг. 3 - схему одного из вариантов воплощения подсистемы анализа голоса. Фиг. 4 - схему одного из вариантов воплощения подсистемы определения характеристик голоса. Фиг. 5 - схему одного из вариантов воплощения подсистемы моделирования голоса. Фиг. 6 - схему одного из вариантов воплощения подсистемы пакетирования сигнала модели голоса. Фиг. 7 - один из вариантов воплощения схемы системы в соответствии с настоящим изобретением, используемой с вариантами удаленной загрузки информации. Фиг. 8 - вид сверху примера одного из вариантов воплощения настоящего изобретения в виде мобильного, компактного компонента. Фиг. 9 - вид сверху примера одного из вариантов воплощения настоящего изобретения с использованием источника визуальной информации на носителе. Подробное описание изобретения Голос представляет собой звук, имеющий чрезвычайно высокое значение у млекопитающих. Ребенок узнает голос матери, который успокаивает его, даже до рождения, и звуки голоса дедушки уменьшают страх даже у взрослых людей. Другие голоса могут влиять на совершенно посторонних людей или могут вызывать воспоминания у влюбленных о давно минувших событиях и моментах. Здесь приведены всего несколько примеров великого дара - способности распознавания, которым обладает человек и другие виды млекопитающих, и их способности влиять на других (и на самих себя) с помощью самого уникального звука - голоса каждого живого существа. У людей, например, особенность голоса человека происходит от генетического вклада родителей, который выражается в форме,размере и положении различных компонентов тела человека, которые влияют на звучание голоса человека, когда он говорит или общается по-другому с помощью голоса или через ротовой и носовой проходы. Кроме того, существуют другие влияющие факторы. В связи с этим,понятно, что люди существенно различаются между собой, часто даже в пределах одной семьи. Действительно, даже голос одного и того же человека может звучать несколько поразному из-за временных влияний, таких как состояние здоровья, уровень стресса, эмоциональное состояние, усталость, температура окружающей человека среды или другие факторы. 4 Однако во всем мире считается общепринятым,что качество голоса человека представляeт собой чрезвычайно уникальную комбинацию, которую могут различать люди,слышавшие этот голос раньше. Способность людей к ассоциациям с помощью чувств является исключительной, в частности, когда такие чувства относятся к идентификации и ассоциации с голосом человека. Главные и незначительные события в жизни часто вспоминаются через много лет или десятилетий в соответствии с природой сделанных замечаний или запомнившегося тона. Такова устойчивая сила и эмоциональная энергия голоса. Хорошо известны способы фиксирования и воспроизведения голоса человека на различных носителях и машинах. Манипуляции с записанным голосом человека в течение многих десятилетий производились, в основном, преднамеренно и непреднамеренно, на ленте и на цифровых носителях. Однако такие манипуляции обычно были ограничены рамками того, что в действительности было выражено человеком,а не тем, что могло бы быть выражено этим человеком. Например, сегменты действительных высказываний человека воспроизводили, редактировали, смешивали и повторно воспроизводили, иногда даже с разными скоростями. Другие примеры использования голоса человека включают воспроизведение сегментов преднамеренно искаженного голоса, такого, который мог использоваться в мультфильмах или для других звуковых эффектов, используемых в анимации или некоторых видах музыки. Конечно, в анимации также использовали искусственный голос, не обязательно создаваемый на основе реального голоса. Один из примеров представляет собой "голос" оператора, сгенерированный компьютером, который используется в некоторых телефонных системах и системах связи. Один из способов синтеза голосов и звуков называется конкатенативным способом и представляет собой запись выборок формы колебаний реального разговора человека. В данном способе затем производят разбиение заранее записанного реального разговора человека на сегменты и выполняют генерирование речевых выражений путем соединения этих сегментов речи человека для построения слогов, слов или фраз. Размер этих сегментов изменяется. Другой способ синтеза разговора человека известен как параметрический. В этом способе используются математические модели для воссоздания требуемых звуков речи. Для каждого требуемого звука используется математическая модель или функция, предназначенная для генерирования этого звука. В собственно параметрическом способе, в общем, звуки, произносимые человеком, не используются в качестве элементов построения речи. И, наконец, в общем, существует несколько хорошо известных типов параметрических синтезаторов речи. Один из них известен как 5 артикуляторный синтезатор, который производит математическое моделирование физических аспектов легких, гортани, а также речевого и носового трактов человека. Другой тип параметрического синтезатора речи известен как формантный синтезатор, который производит математическое моделирование акустических аспектов речевого тракта человека. Другие системы включают средство, предназначенное для распознавания конкретного голоса после обучения используемой системы этому голосу. Примеры таких систем включают различные системы распознавания голоса, используемые в области фиксирования разговорного языка с последующим переводом его звучания в текст, такие как те, которые используются в системах автоматической записи под диктовку и в аналогичных системах. Другие системы, связанные с обработкой речи, относятся к области биометрии и использованию определенных слов речи в качестве кодов или шифров для обеспечения безопасности. Ни в одной из этих систем, способов, средств или других форм раскрытия не используются различные изобретения, описанные в настоящем описании,и в этих источниках даже не описана потребность в таких технических нововведениях. Уже давно возникла потребность в системе и способе, предназначенных для сохранения голосов других существ динамичным и адаптивным образом для использования в будущем и для пользы источника-обладателя голоса или других людей. Кроме того, существует потребность в системах и способах для осуществления и использования такого фиксирования или профилирования голоса, которое представляет членораздельную, или артикулированную, или имеющую все подлинные характеристики, вокализацию или голос в соответствии с голосом реального человека, таким образом, который,возможно, никогда не был предусмотрен этим человеком. Системам и способам, предназначенным для выполнения этого, присущи некоторые дополнительные преимущества, которые позволяют легко использовать их всем людям,фактически любого уровня образования, культуры или говорящим на любых языках. Кроме того, существует потребность в новых способах,технологиях и моделях ведения деловых операций, а также в воплощении устройств и других средств для создания и осуществления доступа к определенным моделям голоса и затем для использования этих моделей голоса для персональных потребностей или по личному желанию при ведении деловых операций или для удовольствия. И вновь повторим, что, хотя были сделаны значительные достижения в области технологии голоса, ни в одной из этих выполненных в прошлом разработок не предусматриваются аспекты настоящего изобретения и они просто подчеркивают новую и до настоящего 6 времени непризнанную потребность в настоящем изобретении. На фиг. 1 представлена схема одного из вариантов воплощения системы 10, предназначенной для фиксирования достаточной части конкретного голоса, необходимой для использования этой части в качестве модели при дальнейшем использовании характеристик голоса. Система 10 может представлять собой часть портативного устройства, такого как портативное электронное устройство, или она может представлять собой часть вычислительного устройства такого размера, как портативный компьютер, компьютер типа ноутбук или настольный компьютер, или система 10 может просто представлять собой часть электронной схемы,установленной внутри другого устройства, либо электронный компонент или элемент, разработанный для временного или постоянного размещения в другом электронном элементе, схеме или системе, или использования с ними, либо система 10 может, полностью или частично,представлять собой считываемый компьютером код или просто логическую или функциональную схему в нейронной системе, либо система 10 может быть сформирована как какое-либо другое устройство или продукт, такой как распределенная система сетевого типа. В одном из вариантов воплощения система 10 содержит средство 15 ввода или фиксирования, предназначенное для фиксирования или приема части голоса для обработки и построения алгоритма голоса или средства 19 моделирования, которое может быть сформировано как поток данных,пакет данных, телекоммуникационный сигнал,средство программного кода, предназначенное для определения и воссоздания конкретного голоса или множества характеристик голоса,организованных для применения или моделирования в отношении другой организации звука или речи в виде кажущегося голоса реального обладателя. Другие средства формирования считываемого компьютером программного кода или другие средства, предназначенные для использования определенных данных идентифицированных характеристик голоса для искусственного генерирования голоса, также рассматриваются в пределах настоящего изобретения. Логика или правила алгоритма или средства 19 моделирования предпочтительно формируют с вводом минимального количества звучания голоса, однако, для каждого голоса может потребоваться использовать различное количество звучания голоса и других данных для формирования приемлемого набора данных. В одном из вариантов воплощения настоящего изобретения требуется производить фиксирование и использование части звучания голоса человека, например, на основе небольшой по размеру аналоговой или цифровой записи или при вводе в режиме реального времени голоса живого человека, голос которого моде 7 лируется. Действительно, может быть сформирована заранее определенная группа слов для оптимизации фиксирования данных наиболее соответствующих характеристик голоса человека для обеспечения точного повторения голоса. Для наиболее эффективного определения того,какая из форм предоставленной части звучания голоса наиболее соответствует данному человеку, предусмотрено средство анализа. При фиксировании и записи данных голоса при одном вводе данных или при вводе серии данных речевую информацию сохраняют, по меньшей мере,в одной части средства 22 хранения. Анализ данных голоса выполняют в средстве 25 процессора для идентификации характеристик, используемых при создании модели голоса конкретного человека. При этом предусматривается, что данные голоса могут направляться непосредственно в средство процессора и не обязательно должны первоначально поступать в средство 22 хранения. Далее приведен пример описания взаимодействия средства процессора, средства хранения и средства моделирования со ссылкой на фиг. 2-8. После анализа адекватных данных голоса в одном из вариантов воплощения производится запись модели голоса и эта запись вызывается средством 25 процессора. Например, после того, как было произведено фиксирование достаточной части звучания голоса АА, его анализ и моделирование (теперь обозначен как ААt), производится запись в средстве 22 хранения (которое может быть расположено рядом с другими компонентами или установлено на удалении или может использоваться в распределенном режиме в одном или нескольких местах расположения) до тех пор,пока не появится запрос на его использование. Один из примеров запроса на использование представляет собой запрос, посылаемый пользователем системы 10 через средство 29 репрезентативного ввода для использования моделиAAt голоса АА во вновь создаваемом разговоре,в котором вместо реального живого голоса АА используется сгенерированный голос. Это может произойти в связи или с использованием одной или нескольких различных баз данных,некоторые из которых представлены ситуационной базой 33 данных или персональной базой 36 данных. В свою очередь, выполняется вызов модели AAt голоса АА, которая используется в качестве формирующего механизма с некоторыми другими звуками для создания нового разговорного голоса АА 1, который звучит точно так же, как голос АА реального обладателя, и построен на первоначально введенных данных после их формирования. Хотя новый голос АА 1 во всех отношениях звучит так же, как голос АА реального обладателя, в действительности он представляет собой голос, искусственно созданный с помощью модели AAt, в которой сформирован соответствующий ключ голоса АА, аналогичный генетическому коду. Таким образом, 004079 8 достаточная часть действительного голоса позволяет произвести кодирование системы 10 с использованием модели, которая позволяет произвести воссоздание и неограниченное использование зафиксированного голоса, практически любым образом, необходимым пользователю. Это не просто синтез ранее произнесенных высказываний частей голоса АА, которые были электронным способом соединены вместе с помощью технологии конкатенации или формантной техники, а, скорее, представляет собой совершенно новый голос, который был разработан, произведен и собран или сконструирован с использованием характеристик данных голоса АА (то есть модели или профиля голоса) и, возможно, других характеристик, относящихся к реальному обладателю голоса АА. Конечно, при этом признается, что такая технология повлечет за собой весьма значительные последствия и потребуются меры предосторожности для обеспечения надлежащего использования этой технологии моделирования голоса. Действительно, такая технология может потребовать дополнительного использования средств санкционирования с тем, чтобы только санкционированные пользователи могли иметь разрешение на доступ и использование технологии и данных моделирования голоса. Кроме того, дополнительно может потребоваться создать средство, предназначенное для проверки, является ли слышимый голос реальным или смоделированным, для обеспечения защиты от обманного или неразрешенного использования такого синтезированного голоса. Может потребоваться создать юридические механизмы для учета этой области технологии в дополнение к лицензированию, контрактам и другим механизмам, существующим в настоящее время в большинстве стран. На фиг. 1 средство 41 связи представляет пути потока энергии или данных, которые могут представлять собой физические проводники,световодные каналы или другие электронные,биологические или другие активируемые каналы между элементами системы. В одном из вариантов воплощения средство 44 питания показано, как находящееся в системе 10, но если необходимо, оно также может быть установлено на расстоянии. В другом варианте воплощения системы 10 алгоритм, сигнал, средство кода или модель,которая создается, в целом или частично, может возвращаться для записи или уточнения в средство 22 хранения, средство 19 моделирования либо в другой компонент или архитектуру системы. Такая возможность позволяет и обеспечивает улучшение или адаптацию модели определенного голоса в соответствии с инструкциями разработчика или другого пользователя. Это может быть выполнено, например, если множество наборов данных голоса одного и того же человека могут вводиться в течение некоторого 9 времени, или происходит возрастное изменение,развитие или другие изменения в физиологии или характере реального обладателя голоса. Действительно, возможно осуществлять обучение смоделированного голоса для восстановления контекста предыдущих сеансов и для включения таких знаний в будущие операции. В этих случаях может быть полезным выбирать режим усовершенствования для воспроизведения модели АА 1t голоса (АА 1) и для усовершенствования голоса или модели со сравнением и с обновлением, с использованием средства 22 анализа или средства 29 ввода. Еще один пример включает поиск человека с голосом ВВ, который содержит одну или большее количество характеристик голоса, аналогичных голосу АА,который является голосом реального обладателя для модели АА 1t. В этом случае может быть полезным вводить одну или большее количество аналогичных характеристик из голоса ВВ в виде ограниченных либо общих входные данных для улучшения голоса АА 1 или модели АА 1t. Поэтому становится также возможным сохранять голос ВВ и создавать голос ВВ 1 и модель ВВ 1t голоса, каждый из которых может использоваться в будущем. Другой пример включает создание базы данных различным образом улучшенных голосов для одного реального обладателя голоса, которая используется по потребности в качестве соответствующего варианта системы или пользователем в соответствии с создавшейся ситуацией. Еще в одном примере может быть предложена услуга поиска соответствия голоса и обеспечения соответствующих инструментов улучшения, таких как естественно или искусственно сгенерированные колебания или другие акустические или сигнальные элементы для улучшения модели голоса в соответствии с желанием пользователя. Перед описанием других вариантов воплощения системы 10 или аналогичных систем и способов полезно проанализировать возможные варианты применения данной технологии. В общем, количество вариантов использования так велико, что трудно все их перечислить. Однако следует учитывать, что любое использование звуков, похожих на голос, которые генерируются с помощью данных, введенных в модель, и данных, получаемых в результате работы этой модели, или инструмента кодирования для создания звука, похожего на голос, рассматривается как находящееся в пределах объема настоящего изобретения, в частности, когда такой инструмент кодирования используется с другими средствами генерирования звука, если соответственно они используются для воссоздания звука голоса, который фактически является идентичным голосу действительного реального обладателя. Использование сгенерированного голоса в совершенно новых предложениях или других структурах языка также рассматривается как находящееся в пределах объема настоящего 10 изобретения. Способность создать машину,компонент или другое средство считываемого компьютером кода как часть формирования или передачи сигнала процесса моделирования голоса, или продукта, дополнительно обеспечивает использование настоящей технологии. Средство, предназначенное для связи или использования такой технологии моделирования голоса или генерирования голоса для перемещения данных в потоке или других форм данных, позволяет сформировать виртуальный диалог, который может быть адаптивным и разумным, а также просто информационным или реагирующим, и такой диалог или разговор производится голосами, выбираемыми пользователем. Кроме того, предусматривается, что описанная здесь технология может использоваться с визуальными изображениями, а также со слышимыми звуками. Кроме того, предполагается, что модель голоса, описанная здесь, может быть создана с использованием данных, которые не включают действительно доступную часть голоса реального обладателя, но что доступная часть голоса реального обладателя может использоваться,возможно, с другими данными для подтверждения точности дублирования голоса реального обладателя. Таким образом, становится возможным либо использовать достаточную часть голоса для моделирования голоса или просто для подтверждения точности смоделированного другим способом голоса. Смоделированный или скопированный голос может использоваться для взаимодействия с пользователями компьютеров или других машин и систем или для передачи им указаний. Пользователь может выбрать такой смоделированный голос либо из своей собственной библиотеки смоделированных голосов, из другого источника смоделированных голосов, или может просто создать новый голос. Например, смоделированный голос АА 1 может быть выбран пользователем для передачи указаний по голосовой почте или для считывания текстов или другого интерфейса связи, в то время как смоделированный голос СС может быть выбран для использования в интерактивной развлекательной программе. Неисправности или проблемы, возникающие в машине пользователя, или сигналы предупреждения пользователю устройства могут быть идентифицированы или разрешены пользователем при работе со смоделированным голосом DD. Здесь приведены простые примеры того, как такая технология позволяет создать улучшенный интерфейс пользователя и ассоциацию пользователя с функциями,задачами, режимами или другими свойствами путем использования технологии моделирования голоса. Выбор и использование модели, а также создание и использование генерированного голоса могут быть выполнены в машине или в устройстве пользователя, частично в машине или в устройстве пользователя или за пре 11 делами машины или устройства пользователя. Могут также возникнуть случаи только временного использования одного или большего количества устройств, например, в номере гостиницы, при посещении какого-либо офиса или в других местах либо при временном использовании устройства, которое, тем не менее, обеспечивает вышеуказанные свойства в приведенных выше различных вариантах. Например, турист может захотеть иметь при себе или обеспечить доступ к определенным голосам, которые сопровождали бы его во время путешествия на самолете или в номере гостиницы. Настоящее изобретение может использоваться в помещениях больниц, или в приютах, или в других местах. Такие варианты использования становятся возможными в одном или большем количестве вариантов воплощения, приведенных здесь. Интересно, что настоящая система также может использоваться некоторыми лицами с их собственном голосом в качестве наследия для других. Многие другие варианты использования находятся в пределах объема приведенного здесь описания. Другие варианты использования настоящего изобретения, описанные здесь, включают образование, например ознакомление детей и других лиц с историческими событиями с использованием смоделированных по выбору голосов. Например, если родитель желает, чтобы его ребенок узнал о взаимоотношениях рас в Соединенных Штатах Америки в 1960-е годы,используя один из голосов умерших бабушек или дедушек ребенка, то смоделированный голос выбранного дедушки или бабушки (если он имеется) мог бы быть разработан, изготовлен и предоставлен для использования. Система 10 могла бы обеспечить доступ в одну или большее количество баз данных для сбора информации и знаний о соответствующем предмете и предоставить эту информацию в одну или большее количество баз данных в системе 10, таких как ситуационная база 33 данных, предназначенная для использования по мере необходимости. Смоделированный голос ЕЕ 1 бабушки или дедушки мог бы использоваться для доступа к требуемой информации, и требуемый запрос мог бы удовлетворяться с помощью смоделированного голоса ЕЕ 1, и обсуждение по требуемой теме начиналось бы, когда это необходимо. Такое обсуждение может быть сохранено для последующего использования в системе 10 или в удаленном месте, если необходимо, либо обсуждение может производиться интерактивно между "дедушкой или бабушкой", то есть смоделированным голосом, и ребенком. Такое свойство становится возможным путем использования модуля распознавания голоса, который должен иметь еще до начала обсуждения информацию об идентичности голоса ребенка, и для включения адекватного словаря и нейтрального уровня знаний по различным комбинациям 12 вопросов, которые, вероятно, поступят от ребенка. Кроме того, может быть создан мост от модуля ввода и распознавания голоса к части смоделированного голоса системы для обеспечения способности живого реагирования смоделированного голоса. Таким образом, предусматриваются различные инструменты распознавания голоса, сконфигурированные в соответствии с новым вариантом использования, описанным в настоящем описании. Конечно, такая конфигурация также требует применения средств для быстрого поиска, необходимых для ответов на вопросы и для формулирования ответа, соответствующего уровню слушающего ребенка. Очевидно, этот пример иллюстрирует особый потенциал настоящей технологии, в частности, когда она комбинируется с соответствующими данными, мощностью и быстродействием системы. В качестве альтернативы, при использовании дополнительного модуля распознавания голоса становится возможным использовать только ограниченные свойства, позволяющие слушателю смоделированного голоса направлять генерируемый голос для остановки или продолжения работы, или для обеспечения некоторых других свойств с помощью определенных команд. Это представляет собой форму ограниченного диалогового режима, соответствующего некоторым, но не всем типам использования. Даже если пользователь не выберет использование дополнительных свойств и вместо этого просто включит рассказ или обсуждение с голосом отсутствующих бабушки или дедушки, эффект и использование этого будет огромным для этого или других типов использования. В случае, когда пользователь желает только использовать смоделированный голос, соответствующий образованию и жизненному опыту реального обладателя этого голоса, то это возможно выполнить с помощью ввода различных фильтров или модификаторов. Например, смоделированный голос может снова представлять собой выбранный выше голос дедушки или бабушки, (смоделированный голос ЕЕ 1) , и фильтр ДАННЫХ ДАТ используется с датой, выбранной "ДО ДЕКАБРЯ 1963 ГОДА", для обсуждения взаимоотношений рас в Соединенных Штатах Америки в 1960-е годы. В результате этого,будет создано обсуждение, которое не будет включать информацию, которая произошла после указанной даты. В этом примере "дедушка" или "бабушка" не может обсуждать Акт о праве голоса 1965 года или беспорядки в городах в конце 1960-х годов в этой стране. Аналогично,становится возможным откорректировать различные аспекты данных или самого смоделированного голоса, например, используя тип характеристик данных, представленный на фиг. 4. При этом, однако, следует понимать, что другие регулировки являются возможными и рассмат 13 риваются в пределах объема настоящего изобретения, приведенного здесь, и что вышеприведенные примеры просто представляют возможности технологии в соответствии с настоящим изобретением. В другом варианте воплощения системы и способов, описанных здесь, пользователь может использовать смоделированный голос любимого человека или другого человека для чтения пользователю. В этом примере становится возможным обеспечить чтение книг для людей любого возраста голосом отсутствующего или умершего члена семьи или другого человека, известного пользователю. При комбинировании с огромным набором должным образом сконфигурированных носителей и средств кода, считываемого компьютером, для осуществления связи между данными, такое новшество само по себе обеспечит чрезвычайную пользу для пользователей. Этот тип использования имеет широкие варианты применения за пределами конкретного примера, приведенного выше. Действительно, еще более широкое использование этой технологии,таким образом, состоит в предоставлении доступа к базе данных разрешенных и смоделированных голосов, доступ к которым может осуществляться и которые могут использоваться другими лицами за плату или при условии другой формы компенсации. В применении к музыке, такая технология также имеет глубокие последствия, в частности, если человек может получить доступ к смоделированным голосам,существовавшим в прошлом, и представить популярных певцов - голоса многих из них все еще доступны для моделирования. Очевидно,такая технология позволяет создать новую сферу производства, сдачи в наем, покупки или других вариантов использования моделей голосов и связанных с этим средств, технологий и способов ведения деловых операций с использованием такой технологии. Настоящее изобретение также может найти применение при медицинском лечении определенных незначительных или значительных психологических заболеваний, при котором правильное использование терапии смоделированного голоса может иметь в достаточной степени смягчающий или даже терапевтический эффект. Еще один возможный вариант использования этой технологии состоит в создании вновь разработанного голоса для использования его так, чтобы он был основан или имел предшественника в виде одного или большего количества смоделированных голосов существующего реального обладателя. Монопольное использование вновь созданного голоса может контролироваться с использованием различных средств или законодательных актов, таких как лицензирование или отчисление авторских гонораров и т.п. Конечно, такие голоса могут сохраняться как частная собственность для ограниченного использования самим разработчиком. 14 Можно представить природу созданных таким образом библиотек. Такие голоса будут представлять творческие звуки разработчика, но каждый голос в действительности будет иметь компонент напряжения реального голоса млекопитающего, как основу использования инструмента или кода моделирования, аналогично образцу ткани для анализа ДНК, но применимого к определенному голосу. Этот тип комбинации представляет мощные новые возможности для связи и взаимоотношений на основе голоса и других звуков, создаваемых млекопитающими. Системы в соответствии с настоящим изобретением могут быть портативными или иметь другие размеры. Системы могут быть внедрены в другие системы или могут представлять собой отдельные системы при работе. Системы и способы, описанные здесь, могут представлять собой часть или все элементы в распределенной,сетевой или другой удаленной системе взаимодействия. В системах и способах, описанных в настоящем описании, могут использоваться загружаемые данные или данные с удаленным доступом и они могут использоваться для управления различными другими системами или способами или процессами. Варианты воплощения настоящего изобретения включают процедуры открытого интерфейса, предназначенные для запросов и воплощения способов и операций, описанных здесь, но которые могут выполняться полностью или частично другими операционными системами или системными приложениями. Процесс моделирования и использования смоделированных голосов может выполняться и использоваться либо в отношении млекопитающих, либо искусственных машин или процессов. Например, робот или другой помощник с искусственным интеллектом может создать или использовать один или большее количество смоделированных голосов такого типа. Такой помощник может также использоваться для автоматического поиска голосов в соответствии с определенными общими или ограниченными критериями и может затем генерировать смоделированные голоса в виртуальных или физических фабриках голосов. Таким образом, могут быть эффективно созданы большие базы данных смоделированных голосов. При таком или аналогичном систематическом использовании может оказаться предпочтительным создавать и использовать данные или другие типы маркировки и технологий идентификации в отношении одной или большего количества частей реальных голосов, используемых для создания смоделированного голоса. Ниже приведены примеры вариантов применения с использованием описанной здесь технологии. Они не предназначены для ограничения, но скорее представлены как возможные варианты использования в дополнение к вари 15 антам воплощения, описанным или предполагаемым в настоящем описании. Пример 1. Процесс моделирования с использованием элементов вариантов воплощения, описанных здесь, позволяет сформировать сигнал кодирования голоса, содержащего логическую структуру характеристик специфического голоса,достаточных для точного копирования звучания этого голоса. Пример 2. Устройство компьютерного указания и обновления, представления статуса или помощника с использованием одного или большего количества выбранных голосов с использованием описанной здесь технологии. Пример 3. Домашнее устройство контроля за энергией, оповещающее устройство или помощник с использованием одного или нескольких голосов на основе описанной здесь технологии. Пример 4. Помощник в номере гостиницы или помощник в автомобиле, предназначенный для подачи пользователю указаний в соответствии с необходимостью, таких как, например, звонокбудильник в гостинице с выбранным пользователем голосом. Аналогично водитель автомобиля может получать информацию, передаваемую голосом или голосами, выбранными пользователем. Пример 5. Использование одного или большего количества выбранных голосов на основе описанной здесь технологии в персональном цифровом помощнике, в портативном устройстве на базе персонального компьютера или в другом электронном устройстве или компоненте в любое время для фиксирования голоса, помощника,обработчика извещений и т.д. Пример 6. Создание или управление одним или большим количеством выбранных голосов или моделей голосов с помощью логики компьютера/электронной микросхемы, инструкций или средств кода для ведения деловых операций и способов технологии, а также описанных здесь вариантов производства. Пример 7. Использование технологии моделирования голоса в комбинации с другими визуальными носителями, такими как фотографии, цифровое видео или голографические изображения. Пример 8. Использование описанной здесь технологии с профильной картой, основанной на памяти типа флэш, для включения в любое устройство,которое может записывать, воспроизводить или воссоздавать голос. Пример 9. Использование технологии, описанной здесь, с персональным устройством, которое 16 сканирует и обновляет загружаемую информацию для пользователя в виде требуемого голоса или голосов по выбору. Например, это может использоваться для организации действий, которые могут выполняться роботом, таким как информационный робот, предназначенный для осуществления фонового поиска и связи через интерфейс, в то время как пользователь не доступен, и затем для сообщения пользователю статуса с помощью одного или большего количества заданных голосов, с использованием описанной здесь технологии. Пример 10. Использование технологии, описанной здесь, в комбинации с одним или большим количеством компонентов автомобиля или другой транспортной системы. Пример 11. Использование технологии, описанной здесь, с одним или большим количеством компонентов самолета во время полета. Пример 12. Использование технологии, описанной здесь, в качестве устройства напоминания о правилах безопасности при использовании с одним или большим количеством компонентов приспособлений или оборудования на рабочем месте, такого как монитор осанки оператора персонального компьютера, электрического оборудования, опасного оборудования и т.д. Пример 13. Использование технологии, описанной здесь, как дополнение к другим системам автоматического голосового управления, таким как устройства для диктовки, устройства для указаний, устройства-компаньоны или устройства считывания текстов. Пример 14. При использовании описанной здесь технологии используются механизмы социального посредничества или управления, такие как инструмент против приступов гнева на дороге или других форм раздражения и разочарования,включаемые водителем, или включающиеся автоматически, или с помощью других средств. Пример 15. Использование технологии, описанной здесь, в качестве инструмента обучения дома, в школе или на рабочем месте. Пример 16. Использование технологии, описанной здесь, для вдохновенного чтения. Пример 17. Использование технологии, описанной здесь, в качестве инструмента, действующего как машина для записи семейной хронологии. Пример 18. Использование технологии, описанной здесь, в качестве технологии товарного знакаMusicMatch для обеспечения соответствующими голосами певцов с самыми лучшими или требуемыми голосами. 17 Пример 19. Использование технологии, описанной здесь, в качестве технологии товарного знакаVoiceSelect для обеспечения соответствующих кинофильмов или видеозаписей предпочтительными голосами для моделирования развлекательных сценариев, в которых ранее использовался реальный исполнитель, или воссозданных впоследствии при совместном использовании технологии моделирования голоса. Пример 20. Использование технологии, описанной здесь, в качестве устройства "альтер эго" (второе я), которое выполнено в портативном виде,позволяет использовать режим (режимы) работы товарных знаков "SelectVoice" или"VoiceX" и содержит базу данных изображений лиц, которым соответствуют голоса, а также анонимных моделей, которые могут быть выбраны аналогично примеру 7. Пример 21. Использование технологии, описанной здесь, для создания профиля профилированного или смоделированного голоса. Пример 22. Использование технологии, описанной здесь, в качестве устройства чтения для детей или в качестве ночного помощника дома для управления интерактивной системой безопасности. На фиг. 2 изображена схема алгоритма одного из вариантов воплощения подсистемы фиксирования голоса, которая может содержать средство кода, считываемого компьютером, или способа, предназначенного для выполнения фиксирования, анализа и использования голоса АА, предназначенного для моделирования. На фиг. 3 изображен один из вариантов воплощения подсистемы анализа голоса, которая может содержать средство логики, или способа, предназначенного для эффективного определения маршрутизации характеристики данных голоса. В этих вариантах воплощения голос АА фиксируют в модуле приобретения или на этапе 103, и затем он проходит по логическим этапам и путям передачи данных, таким как путь 106, через процесс моделирования. Фиксирование данных может быть выполнено либо цифровыми, либо аналоговыми способами и компонентами. Сигнал, который затем представляет зафиксированный голос АА, проходит через средство 111 или способ анализа для определения, соответствует ли существующий профиль голоса или модель голосу АА. Это может выполняться, например,путем сравнения одной или множества характеристик (таких как показаны в подсистеме 113 характеристики голоса на фиг. 4), как определено модулем 103 приобретения или средством 111 анализа, и затем путем сравнения одной или большего количества его характеристик с известными профилями или моделями голоса,разрешенными для доступа, на этапе 111 анали 004079 18 за. Представительная обратная связь и петля 114 исходного анализа обеспечивают выполнение этих этапов, так что обработка проходит по пути 116. Такое сравнение может включать подачу запросов в базу данных профиля голоса или в другой носитель записи, локальный или удаленный. Этап анализа в модуле 111 анализа и работа подсистемы 113 характеристики голоса могут повторяться в соответствии с алгоритмическими, статистическими или другим технологиями для подтверждения, относится ли, соответствует ли анализируемый голос или нет существующему профилю голоса или файлу данных. На фиг. 4 приведена подробная структура подсистемы 113 характеристики голоса. Далее вновь рассмотрим фиг. 2, на которой показано, что если для сигнала, соответствующего голосу АА, не находится соответствие или он не является идентичным существующему набору профилей голоса, то сигнал проходит в подсистему характеристики голоса для его полной характеристики. Однако если существующий файл данных профиля голоса соответствует сигналу профиля голоса АА, то может не потребоваться создание новой модели в модуле/на этапе 127. В этой ситуации сигнал может анализироваться и/или характеризоваться для возможного генерирования обновленного профиля или модели, которые сами по себе могут затем не записываться или не использоваться. Такая ситуация может произойти, например, когда доступны дополнительные данные характеристики (такие как обеспечивающая часть, наличие или отсутствие стресса или других факторов), которые ранее не были доступны. В соответствии с этим конкретный файл данных голоса может содержать множество моделей. На фиг. 2 и 3 представлен процесс проверки достоверности, содержащий логические этапы и компоненты системы, в общем, показанные как подсистема 133 проверки достоверности. Следует подчеркнуть, что эти фигуры представляют размещение компонентов в подсистеме, в общем, схематично. Кроме того, как показано на фиг. 3, после определения того, что файл данных профиля голоса существует (этап 137), в случае необходимости, может осуществляться логическая проверка достоверности на этапе 139. Если требуется обновление существующей модели, оно производится на этапе 142. В качестве альтернативы на логическом этапе 145 отмечают, что не требуется производить обновление существующей модели. После этапов 143 или 145 на этапе 155 записывается или используется обновленный или предыдущий профиль или модель голоса. Модуль/этап 127 создания модели на фиг. 2 содержит использование подсистемы характеристики голоса для создания уникального идентификатора, предпочтительно цифрового идентификатора, для того конкретного голоса, для которого создается модель или профиль. Эти 19 данные аналогичны генетическому коду, кодам последовательности генов или штрих-кодам и аналогичны идентификаторам в особенности уникальных объектов, существ или явлений. В соответствии с этим заявители называют такой профиль или модель голоса "Voice Template"Voice Sequence Coding" (Коды или кодирование голосовой последовательности). Термины"профиль, профили или профилирование" и производные от них термины могут заменять вышеприведенные товарные знаки или другие термины, используемые в качестве названий и ссылок для этой новой технологии. После завершения создания модели модель голоса может быть записана (показано как модуль записи или этап 161 или использовано в модуле или этапе 164). Фиг. 4 изображает схематическое представление подсистемы характеристики голоса. В настоящем описании приведен, по меньшей мере, один вариант воплощения данных и средства характеристики, предназначенных для определения и характеристики выраженных данных для определения голоса с использованием моделирования или профилирования голоса, как раскрыто в настоящем описании. Как показано, при формулировке данных характеристик доступны различные типы данных для сравнения. Эти данные характеристик затем будут использоваться для создания модели или профиля голоса в соответствии с критериями кодировки. Хотя данные, приведенные на фиг. 4, выглядят как скомпонованные в отдельных модулях, может оказаться предпочтительным использовать процесс открытого компаратора, в котором может быть обеспечен доступ к любым данным для сравнения в любых различных последовательностях или взвешенных приоритетах. Независимо от этого, как показано на чертеже, данные могут содержать следующие категории языка,пол, диалект, регион или акцент (показаны как выходной сигнал VC0 "Характеристики голоса" в модуле или на этапе 201); частота, высота,тон, длительность или амплитуда (показаны как выходной сигнал VC1 в модуле или на этапе 203); возраст, здоровье, произношение, словарный запас или физиология (показаны как выходной сигнал VC2 в модуле или на этапе 205); структура, синтаксис, громкость, модуляция или тип голоса (показаны как выходной сигнал VС 3 в модуле или на этапе 207); образование, опыт,фаза, повторение или грамматика (показаны как выходной сигнал VC4 в модуле или на этапе 209); род занятий, национальность, этническая принадлежность, привычки или окружающая обстановка (показаны как выходной сигнал VC5 в модуле или на этапе 211); контекст, колебания, правила/модели, использование типа части,размер или количество (показаны как выходной 20 сигнал VC6 в модуле или на этапе 213); скорость, эмоции, сгруппированность, аналогии или акустическая модель (показаны как выходной сигнал VC7 в модуле или на этапе 215); математическая модель, модель обработки, модель сигнала, модель схожести звуков или модель совместного использования (показаны как выходной сигнал VC8 в модуле или на этапе 217); модель вектора, адаптивные данные, классификации, фонетика или артикуляция (показаны как выходной сигнал VC9 в модуле или на этапе 219); сегменты, слоги, комбинации, самообучение или молчание (показаны как выходной сигнал VC10 в модуле или на этапе 221); пакеты,частота дыхания, тембр, резонанс или модель повторных проявлений (показаны как VC11 в модуле или на этапе 223); гармоники, модели синтеза, разрешающая способность, точность или другие характеристики (показаны как выходной сигнал VC12 в модуле или на этапе 225); или различные другие техники для уникальной идентификации части (фрагмента или полностью) голоса. Например, они дополнительно могут включать цифровую или аналоговую идентификацию голоса, модуляцию, синтез входных данных или других данных, сформированных или используемых для этой цели, и все это показано как выходной сигнал VCx в модуле или на этапе 227. Следует учитывать, что один или большее количество типов данных из любого одного или большего количества модулей или этапов может позволить получить значение для модели голоса. Кроме того, для целей настоящего изобретения величина VCx охватывает любую известную технологию классификации в ходе интерпретации, независимо от того, указана ли она в данном описании, при условии, что она используется в определении в последующем уникального профиля или модели голоса для конкретного голоса и используется в соответствии с новыми разработками, описанными здесь. Кроме того,следует учитывать, что данные, скомбинированные в файлах характеристик голоса, и выходные сигналы VC0, VC1, VC2, VС 3, VС 4, VC5,VC6, VC7, VC8, VC9, VC10, VC11, VC12 и VCx могут получать различные приоритеты и могут комбинироваться различным образом для точного и эффективного анализа и характеристики голоса, причем VCx представляет дополнительные технологии, приведенные здесь в качестве ссылки. На фиг. 5 и 6 приведены примеры устройства пакетирования сигнала, пригодного для приема данных характеристик различных голосов, таких как цифровые или кодированные данные, представляющие информацию, которая рассматривается как соответствующая и формирующая для моделируемого голоса. Устройство 316 пакетирования сигнала комбинирует выход модуля содержания сигнала или этапа 332 и значения/количественной оценки по одному или 21 большему количеству сигналов VC0-VCx, а также форматы сигнала или кода в модуле или на этапе 343, как соответствующие для правильной передачи и использования различными потенциальными интерфейсами пользователя, устройствами или средствами передачи для создания выходной модели кода голоса, или сигналаVTx. Следует учитывать, что возможно применение различных способов для создания уникального идентификатора, предназначенного для разделения различных характеристик голоса, и что такие различные возможности могут использоваться в настоящем изобретении в широком контексте и объеме настоящего изобретения для получения, в некоторой степени, независимой в отношении некоторых компонентов методологии. На фиг. 7 представлена организация и способ электронного запроса и передачи между генерированием модели голоса или устройством 404 записи и удаленным пользователем. В этом представлении достаточные части могут быть отправлены в удаленное устройство 404 генерирования или записи модели голоса от любого количества различных пользователей 410, 413,416. Устройство 404 затем генерирует или производит поиск файла данных модели голоса и создает или производит поиск сигнала модели голоса. Сигнал модели затем передают или загружают для пользователя или для назначенного им лица, как показано на этапе 437. В момент загрузки или позже по запросу 441 пользователя сигнал модели форматируют для соответствующего использования устройством назначения, включая инструкции протокола активирования, как показано на этапе/в модуле 457. На фиг. 8 схематично представлено устройство мобильного носителя, такого как карта,диск или микросхема, в котором размещены все необходимые компоненты, в зависимости от режима использования и потребностей, необходимых для использования технологии моделирования голоса. Например, на основе 7 и 8 может быть изготовлена карта 477 для двери в гостинице, используемая при регистрации туриста в гостинице. Однако в дополнение к нормальному программированию кода безопасности на месте и использованию электронных компонентов 479, установленных в карте, можно получить дополнительные свойства, содержащие аспекты настоящего изобретения. Схематичное представление дополнительных свойств, получаемых с помощью такой карты, включает средство 481, предназначенное для приема и использования модели голоса для выбранного голоса или голоса туриста для различных целей при остановке туриста в гостинице. Как показано,такие свойства могут включать элемент 501 приема и накопления модели, генератор или схему 506 генератора звука, блок 511 центрального процессора, схему 515 ввода/вывода (I/O),элементы 518 цифроаналогового/аналогово 004079 22 цифрового преобразования (D-A) и блок 521 синхронизации. Повторим, что могут использоваться различные другие элементы, такие как средство сжатия или распаковки голоса, которые известны в области производства сотовых телефонов, или другие компоненты, позволяющие придать карте требуемую функцию. Пользователь может наслаждаться диалогом или использовать интерфейс с неодушевленными устройствами, установленными в гостинице, которые звучат голосом (голосами), выбранным туристом. Несомненно, профиль туриста позволяет даже сохранять такую информацию по голосовым предпочтениям, как соответствующую, и это можно использовать для повышения начислений для оплаты или для улучшения условий проживания при использовании настоящего изобретения. Предусматривается, что настоящее изобретение может использоваться для различных вариантов применения и в различных изделиях, и пример, приведенный на фиг. 8 и 9, не следует рассматривать как ограничивающий. На фиг. 9 приведено изображение фотографии 602, которая сконфигурирована для интерактивного использования технологии моделирования голоса, причем голос JJ присваивается фигуре FJJ и голос KK присваивается фигуреFKK. В рамке 610 установлено средство или другая структура, например средство считываемого компьютером кода или просто трехмерный материал, предназначенное для создания интерфейса с предметами или объектами, изображенными на фотографии (или на других носителях) с соответствующими моделями голоса для воссоздания диалога, который, вероятно, происходил или мог бы происходить по желанию пользователя. Следует понимать, что существуют различные средства и способы для фиксирования,анализа и синтеза компонентов реального и искусственного голосов. Например, в следующих патентах Соединенных Штатов Америки и в цитируемых в них или приведенных ссылках раскрыто несколько средств, предназначенных для фиксирования, синтеза, перевода, распознавания, характеристики или другого типа анализа голосов, и они приведены здесь полностью в качестве ссылки для раскрытия такой информации: 4,493,050; 4,710,959; 5,930,755; 5,307,444; 5,890,117; 5,030,101; 4,257,304; 5,794,193; 5,774,837; 5,634,085; 5,704,007; 5,280,527; 5,465,290; 5,428,707; 5,231,670; 4,914,703; 4,803,729; 5,850,627; 5,765,132; 5,715,367; 4,829,578; 4,903,305; 4,805,218; 5,915,236; 5,920,836; 5,909,666; 5,920,837; 4,907,279; 5,859,913; 5,978,765; 5,475,796; 5,483,579; 4,122,742; 5,278,943; 4,833,718; 4,757,737; 4,754,485; 4,975,957; 4,912,768; 4,907,279; 4,888,806; 4,682,292; 4,415,767; 4,181,821; 3,982,070; и 4,884,972. Ни в одном из этих документов не раскрыт вклад в соответствии с настоящим изобретением, заявленный или дру 23 гим образом описанный здесь. Напротив, в вышеуказанных патентах описаны инструменты,которые могут использоваться, но не являются необходимыми, при воплощении одного или большего количества вариантов воплощения настоящего изобретения. Таким образом, следует понимать, что различные системы, продукты,средства, способы, процессы, форматы данных,накопители данных и среды передачи, содержание данных и другие аспекты рассматриваются в настоящем изобретении для получения новых и неочевидных свойств, преимущества, продуктов и вариантов применения технологии, описанной здесь. В связи с этим вышеприведенные описания следует рассматривать как пример, а не ограничения, соответственно так, что формула изобретения позволяет расширить объем,которому должна соответствовать эта передовая технология, без ограничений по мере развития и получения новых возможностей технологий воплощения. ФОРМУЛА ИЗОБРЕТЕНИЯ 1. Система, предназначенная для фиксирования части конкретного голоса, достаточной для использования этой части в качестве модели, пригодной для последующего генерирования не сказанных ранее слов и фраз при дальнейшем использовании голоса, содержащая а) средство для фиксирования достаточной части голоса в форме, пригодной для анализа в качестве характеристик голоса;b) средство анализа, предназначенное для приема и анализа зафиксированного голоса и для характеризации элементов зафиксированного голоса в качестве данных характеристик так,что эти данные характеристик являются достаточными для уникальной характеристики и воссоздания зафиксированного голоса в форме ранее несказанных выражений указанным зафиксированным голосом; с) средство хранения, предназначенное для приема данных характеристик из средства анализа для конкретного зафиксированного голоса; иd) средство извлечения, предназначенное для извлечения данных анализа и данных характеристик для дальнейшего использования при генерировании звучания смысловых выражений,аналогичного звучанию зафиксированного голоса, но никогда ранее не сказанного им. 2. Система по п.1, отличающаяся тем, что средство, предназначенное для фиксирования голоса, содержит средство цифровой записи. 3. Система по п.1, отличающаяся тем, что средство для фиксирования голоса содержит карту флэш-памяти. 4. Система по п.1, отличающаяся тем, что средство фиксирования голоса содержит средство аналоговой записи. 24 5. Система по п.1, отличающаяся тем, что средство фиксирования голоса содержит средство ввода, предназначенное для приема живого голоса и для передачи этого живого голоса в средство анализа. 6. Система по п.1, отличающаяся тем, что средство анализа содержит средство записи цифровых данных. 7. Система по п.1, отличающаяся тем, что средство анализа содержит средство, предназначенное для идентификации конкретной структуры, синтаксиса, частоты, высоты и тонов речи в данных зафиксированного голоса. 8. Система по п.1, отличающаяся тем, что средство анализа содержит средство, предназначенное для идентификации конкретного словарного запаса, произношения или акцента,уникального зафиксированного голоса. 9. Система по п.1, отличающаяся тем, что средство анализа содержит средство, предназначенное для идентификации определенных свойств, уникальных для зафиксированного голоса, получаемых на основе конкретной анатомической структуры реального обладателя голоса. 10. Система по п.1, отличающаяся тем, что средство анализа содержит средство, предназначенное для определения словарного запаса реального обладателя зафиксированного голоса. 11. Система по п.10, отличающаяся тем,что средство анализа содержит средство, предназначенное для установки данных словарного запаса и данных характеристик для использования при формировании моделируемого в будущем голоса. 12. Система по п.1, отличающаяся тем, что средство анализа содержит устройство цифровой обработки, предназначенное для цифровой обработки данных, вводимых в форме голоса или цифрового представления записанного голоса. 13. Система по п.1, отличающаяся тем, что средство анализа содержит второе средство ввода, предназначенное для приема дополнительных данных, относящихся к физиологии реального обладателя голоса. 14. Система по п.13, отличающаяся тем,что средство второго ввода средства анализа содержит средство процессора цифрового сигнала, которое позволяет избирательно принимать звуковые или другие данные, содержащие информацию визуализации в отношении морфологии реального обладателя голоса. 15. Система по п.1, отличающаяся тем, что средство анализа содержит средство сравнения,предназначенное для сравнения набора данных входного голоса с записанными данными, содержащими данные возраста, данные языка,данные образования, данные пола, данные рода занятий, данные об акценте, данные о национальности, этнические данные, данные о типе 25 голоса, данные о привычках и данные об окружении. 16. Система по п.1, отличающаяся тем, что средство анализа содержит третье средство ввода, предназначенное для приема данных, относящихся к реальному обладателю голоса, содержащих данные возраста, данные образования, данные пола, данные о роде занятий, данные об акценте, данные о национальности, этнические данные, данные о типе голоса, данные о привычках, данные о языке и данные об окружении. 17. Способ создания звуков, похожих на голос, которые идентичны по звучанию голосу данного конкретного человека, содержащий следующие этапы: а) фиксирование достаточной части голоса конкретного человека для записи и использования;b) запись достаточной части голоса конкретного человека; с) анализ достаточной части голоса для идентификации существенных компонентов или характеристик зафиксированного голоса; иd) использование идентифицированных существенных компонентов или характеристик для создания нового голоса, который при установлении данных из одной или большего количества средств базы данных и последующем прослушивании звучит идентично во всех отношениях голосу конкретного человека для слушателя, имеющего нормальные способности слухового различения. 18. Способ по п.17, отличающийся тем, что этап анализа содержит этапы идентификации компонентов в зафиксированной достаточной части голоса конкретного человека, относящихся по меньшей мере к одному из компонентов,включающих частоту, тон, высоту, громкость,акцент, пол, гармоническую структуру, акустическую мощность, фонетический или временной акцент, энергичность и периодичность. 19. Способ по п.18, отличающийся тем, что этап фиксирования достаточной части голоса конкретного человека, предназначенного для записи и использования, включает фиксирование звука, генерируемого гортанью, либо звука,генерируемого турбулентностью голоса конкретного человека. 20. Способ точного копирования голоса человека, содержащий следующие этапы: а) идентификацию набора данных минимального размера, содержащего комбинацию слов, звуков или фраз, которые должны быть произнесены реальным обладателем голоса для копирования;b) фиксирование при произношении комбинации слов, звуков или фраз реального обладателя голоса, который должен быть скопирован на носителе; с) анализ зафиксированного произношения для идентификации характеристик голоса ре 004079 26 ального обладателя голоса, достаточных для обеспечения искусственного генерирования голоса с использованием идентифицированной характеристики, так, чтобы искусственно сгенерированный голос был, по существу, идентичным во всех отношениях для слушателя, имеющего нормальные способности слухового различения, когда такой слушатель слышит сгенерированный голос с использованием некоторых компонентов языка, не содержащихся в зафиксированном произношении действительного голоса реального его обладателя. 21. Изделие, содержащее а) носитель записи, используемый в компьютере, имеющий средство программного кода, считываемого компьютером, которое установлено в нем для создания копии голоса человека, причем средство программного кода, считываемого компьютером, в указанном изделии содержитb) средство программного кода, считываемого компьютером, предназначенное для выполнения компьютером анализа зафиксированной достаточной части голоса реального обладателя для идентификации данных характеристик голоса, достаточных для обеспечения искусственного генерирования голоса; и с) средство программного кода, считываемого компьютером, предназначенное для использования данных характеристик идентифицированного голоса для искусственного генерирования голоса так, чтобы искусственно сгенерированный голос был, по существу, идентичен по звучанию и использованию для пользователя, когда слушатель слышит сгенерированный голос, в котором используются некоторые компоненты языка, не содержащиеся в зафиксированной речи действительного голоса реального его обладателя. 22. Изделие по п.21, отличающееся тем,что дополнительно содержит средство программного кода, считываемого компьютером,предназначенное для записи сгенерированного голоса для последующего использования. 23. Изделие по п.21, отличающееся тем,что дополнительно содержит средство программного кода, считываемого компьютером,предназначенное для использования данных характеристик голоса для создания профиля голоса реального его обладателя. 24. Изделие по п.21, дополнительно содержащее средство программного кода, считываемого компьютером, предназначенное для обеспечения доступа к средству базы данных,предназначенному для записи данных, содержащих данные о возрасте, данные об образовании, данные, относящиеся к полу, данные о роде занятий, данные об акценте, данные о языке,национальности, этнические данные, данные о типе голоса, данные о привычках, общие данные и данные об окружении. 27 25. Компьютерный программный продукт,предназначенный для использования с устройством акустического вывода, причем указанный компьютерный программный продукт содержит а) средство программного кода, считываемого компьютером, воплощенное в нем для копирования голоса человека через выводное акустическое устройство, причем компьютерный программный продукт содержитb) средство программного кода, считываемого компьютером, предназначенное для выполнения компьютером анализа зафиксированной достаточной части голоса реального обладателя для идентификации данных характеристик голоса, достаточных для обеспечения искусственного генерирования голоса; и с) средство программного кода, считываемого компьютером, предназначенное для использования идентифицированных данных характеристик голоса для искусственного генерирования и вывода голоса через акустическое выводное устройство так, чтобы искусственно сгенерированный голос был, по существу, идентичен по звучанию и использованию для слушателя, когда слушатель слышит сгенерированный голос с использованием некоторых компонентов языка, не содержащихся в зафиксированной речи действительного голоса реального его обладателя. 26. Компьютерный программный продукт,предназначенный для использования с устройством отображения, причем указанный компьютерный программный продукт содержит а) средство программного кода, считываемого компьютером, установленное в нем, предназначенное для копирования голоса человека и проверки точности копируемого голоса с отображением на устройстве отображения, причем компьютерный программный продукт содержитb) средство программного кода, считываемого компьютером, предназначенное для выполнения компьютером анализа зафиксированной достаточной части голоса реального его обладателя для идентификации данных характеристики голоса, достаточных для выполнения искусственного генерирования голоса; иc) средство программного кода, считываемого компьютером, предназначенное для использования идентифицированных данных характеристики голоса для искусственного генерирования голоса и для сравнения характеристики сгенерированного голоса с голосом реального его обладателя на устройстве отображения так, чтобы искусственно сгенерированный голос был, по существу, идентичен по звучанию для слушателя, когда устройство отображения индицирует это и когда слушатель в действительности слышит сгенерированный голос с использованием некоторых компонентов языка, не содержащихся в зафиксированной речи действительного голоса реального его обладателя. 28 27. Компьютерный программный продукт,предназначенный для использования с акустическим выводным устройством, причем указанный компьютерный программный продукт содержит а) средство программного кода, считываемого компьютером, установленное в нем, предназначенное для запуска копирования голоса человека через выходное акустическое устройство, причем компьютерный программный продукт содержитb) средство программного кода, считываемого компьютером, предназначенное для приема и активации компьютером файла данных характеристик голоса, уникальных для конкретного голоса, достаточных для обеспечения искусственного генерирования голоса; и с) средство программного кода, считываемого компьютером, предназначенное для использования идентифицированных данных характеристик голоса для искусственного генерирования выходного голоса через акустическое выводное устройство так, чтобы искусственно сгенерированный голос был, по существу, идентичен по звучанию для слушателя, когда слушатель слышит сгенерированный голос и зафиксированную речь действительного голоса реального его обладателя. 28. Компьютерный программный продукт,предназначенный для использования с электронным устройством, причем указанный компьютерный программный продукт содержит а) средство программного кода, считываемого компьютером, установленное в нем для запуска копирования голоса человека, причем компьютерный программный продукт содержитb) средство программного кода, считываемого компьютером, предназначенное для приема и активирования файла данных характеристик голоса, уникальных для конкретного голоса, достаточных для обеспечения искусственного генерирования голоса; и с) средство программного кода, считываемого компьютером, предназначенное для использования идентифицированного файла данных характеристик голоса и звукового вывода средства генерирования звука для искусственного генерирования голоса так, чтобы искусственно сгенерированный голос был, по существу,идентичен по звучанию действительному голосу реального его обладателя. 29. Запоминающее устройство, предназначенное для записи данных, предназначенных для обеспечения доступа к программному приложению, выполняемое на подсистеме обработки данных, содержащее а) структуру данных, записанную в указанном запоминающем устройстве, причем указанная структура данных включает информацию, размещенную в базе данных, используемую указанным программным приложением и включающуюb) по меньшей мере один файл данных достаточной части голоса, записанный в указанном запоминающем устройстве, причем каждый из указанных наборов файлов данных достаточной части голоса, содержит информацию, по существу, отличающуюся от любого другого набора файла данных достаточной части голоса; с) множество файлов данных характеристик голоса, содержащих различную справочную информацию для множества характеристик голоса; иd) множество наборов профилей голоса,каждый из которых содержит по меньшей мере один файл данных профиля голоса, содержащий данные, уникальные только для этого файла данных, в котором структура данных позволяет осуществлять доступ к файлам данных характеристик голоса и файлам данных профиля голоса для выполнения операции сравнения по меньшей мере с одним файлом достаточной части голоса. 30. Система обработки данных, выполняющая программное приложение и содержащая базу данных, используемую для указанного программного приложения, причем указанная система обработки данных содержит а) средство ЦПУ, предназначенное для обработки указанного программного приложения; иb) запоминающее средство, предназначенное для хранения структуры данных, предназначенных для осуществления доступа указанным программным приложением, причем указанная структура данных состоит из информации, находящейся в базе данных, используемой указанным программным приложением и включающей по меньшей мере один файл данных достаточной части голоса, записанный в указанном запоминающем устройстве, причем каждый из набора файлов данных достаточной части голоса содержит информацию, по существу, отличающуюся от любого набора файла данных достаточной части голоса; множество файлов данных характеристик голоса, содержащих различную справочную информацию для множества характеристик голоса; множество наборов профиля голоса, каждый из которых содержит по меньшей мере один файл данных профиля голоса, содержащий данные, уникальные только для этого файла данных; и с) в которой система обработки данных позволяет осуществлять доступ к файлам данных характеристик голоса и файлам данных профиля голоса для выполнения операции сравнения по меньшей мере с одним файлом данных достаточной части голоса. 31. Сигнал компьютерных данных, воплощенный в средстве передачи, содержащий 30 а) код источника кодирования для уникальной модели профиля голоса, используемый для кодирования дополнительного электронного звука для создания конкретного генерированного голоса; иb) код кодирования источника в определенном месте положения и сконфигурированный таким образом, чтобы код источника кодирования мог быть съемным из носителя информации для использования в качестве ключа, для создания сгенерированного голоса. 32. Способ использования выбранного голоса в качестве персонального голосового помощника с электронным устройством, содержащий следующие этапы: а) включение электронного средства для осуществления доступа к удаленной базе данных;b) передачу части сигнала в удаленную базу данных, содержащую базу данных голоса,содержащую множество наборов профилей голоса, каждый из которых имеет, по меньшей мере, один файл данных профиля голоса, содержащий данные, уникальные только для этого файла данных и идентифицируемый уникальным идентификатором; с) передачу части сигнала в удаленную базу данных для уникальной идентификации требуемого файла данных и затем для выполнения передачи содержания файла данных в определенное пользователем местоположение электронного устройства; иd) выполнение использования выбранного и переданного файла данных в качестве модели голоса, в комбинации с соответствующим звуком, сгенерированным либо электронным устройством, либо другим средством, предназначенным для генерирования такого звука, так,чтобы, как требуется для пользователя, он мог принимать звук от электронного устройства в виде звука выбранного голоса, как определено идентифицированным голосом. 33. Способ по п.32, отличающийся тем, что файл данных включает характеристики данных выбранного голоса, скомпонованного в виде средства программного кода, считываемого компьютером, для использования данных, характеризирующих идентифицированный голос,для искусственного генерирования модели голоса. 34. Способ по п.32, отличающийся тем, что этап воплощения включает использование средства идентификации для того, чтобы позволить только идентифицированным пользователям осуществлять доступ и использовать технологии и данные моделирования голоса. 35. Способ по п.32, отличающийся тем, что этап воплощения содержит применение средств проверки с избирательным доступом для проверки того, что слышимый голос является либо реальным голосом, либо сгенерированной моделью. 31 36. Способ осуществления деловых операций, в котором используется система, предназначенная для фиксирования части конкретного голоса, достаточной для использования этой части в качестве модели, пригодной для последующего генерирования ранее невысказанных слов и фраз при дальнейшем использовании голоса, содержащий следующие этапы: а) фиксирование достаточной части голоса в форме, используемой для анализа в качестве характеристик голоса;b) ввод достаточной части в модуль анализа для получения характеризирующих элементов зафиксированного голоса в качестве данных характеристик так, чтобы данные характеристик были достаточными для уникальной характеристики и воссоздания зафиксированного голоса в виде невысказанных ранее слов и фраз указанным зафиксированным голосом; с) прием данных характеристик из модуля анализа для конкретного зафиксированного голоса; иd) запись данных характеристик для последующего использования при генерировании слов и фраз, звучащих как зафиксированные голосом, но никогда ранее им не высказанные. 37. Способ по п.36, отличающийся тем, что средство, предназначенное для фиксирования голоса, содержит средство цифрового ввода. 38. Способ по п.36, отличающийся тем, что достаточная часть голоса принимается в электронном виде. 39. Способ по п.36, отличающийся тем, что данные характеристик упакованы для формирования сигнала модели голоса, используемой для комбинирования с генерируемым звуком для создания смоделированного голоса, который звучит так же, как конкретный реальный голос. 40. Способ по п.36, отличающийся тем, что смоделированный голос управляется таким образом, чтобы обеспечить возможность приема команд голосового ввода в смоделированный голос для произношения новых слов с помощью смоделированного голоса, которые, однако, не были введены конкретным голосом. 41. Автоматизированное устройство, предназначенное для фиксирования достаточной части конкретного голоса и для использования этой части в качестве модели, используемой для последующего использования смоделированного голоса, содержащее а) модуль получения, предназначенный для получения достаточной части голоса в форме, используемой для анализа с получением характеристик голоса;b) модуль анализа, предназначенный для приема и анализа зафиксированного голоса и для получения характеризирующих элементов зафиксированного голоса в качестве данных характеристик; и с) модуль генератора модели, предназначенный для автоматического генерирования 32 сигнала модели голоса в качестве уникального идентификатора приобретенного конкретного голоса, но так, чтобы указанный сигнал модели голоса содержал данные, отличающиеся от конкретных слов, высказанных голосом, из которого была сформирована позволяющая часть. 42. Устройство по п.41, отличающееся тем,что дополнительно содержит средство связи,предназначенное для связи со средством накопления для приема данных характеристик из базы данных. 43. Устройство по п.41, отличающееся тем,что дополнительно содержит средство связи,предназначенное для связи со средством накопления для хранения сгенерированной модели до поступления соответствующего запроса. 44. Интерактивный способ, предназначенный для создания моделей голоса и генерирования оплаты за такое генерирование, содержащий а) фиксирование достаточной части конкретного голоса;b) анализ достаточной части конкретного голоса для генерирования профиля данных, который определяет характеристики зафиксированного голоса так, чтобы можно было его воссоздать для последующего использования; с) генерирование сигнала модели голоса в качестве уникального идентификатора приобретенного конкретного голоса; иd) предоставление по меньшей мере одного сгенерированного профиля данных для коммерческого использования другим лицам. 45. Способ, выполняемый устройством,предназначенный для создания модели голоса и генерирования оплаты за такое генерирование,содержащий а) фиксирование достаточной части конкретного голоса;b) анализ достаточной части конкретного голоса для генерирования профиля данных, который определяет характеристики зафиксированного голоса таким образом, что он может быть воссоздан для последующего использования; с) используя профиль данных, генерирование сигнала модели голоса в качестве уникального идентификатора, зафиксированного конкретного голоса; иd) предоставление по меньшей мере одного сигнала модели голоса для коммерческого использования. 46. Способ ведения деловых операций,предназначенный для создания модели голоса,содержащий а) фиксирование достаточной части конкретного голоса или смоделированного голоса;b) использование компьютерных средств,анализирующих достаточную часть голоса для генерирования профиля данных, который определяет характеристики зафиксированного голо 33 са таким образом, что он может быть воссоздан для последующего использования; с) электронное генерирование или поиск сигнала модели голоса в качестве уникального идентификатора зафиксированного голоса; иd) предоставление по меньшей мере одной модели голоса для коммерческого использования. 47. Способ ведения деловых операций по п.46, отличающийся тем, что этап предоставления выполняется путем обмена электронными данными. 48. Способ создания модели из множества голосов, содержащий 34 а) фиксирование достаточной части множества голосов или смоделированных голосов;b) использование компьютерных средств,анализирующих достаточные части голосов для генерирования профиля данных, который определяет характеристики зафиксированных голосов таким образом, что они могут быть скомпонованы как пакет в виде одного сигнала голоса,пригодного для воссоздания его для последующего использования; и с) электронное генерирование сигнала модели голоса в качестве уникального идентификатора вновь сгенерированного голоса.
МПК / Метки
МПК: G10L 21/00
Метки: людей, конкретных, способ, голоса, система, моделирования
Код ссылки
<a href="https://eas.patents.su/19-4079-sistema-i-sposob-modelirovaniya-golosa-konkretnyh-lyudejj.html" rel="bookmark" title="База патентов Евразийского Союза">Система и способ моделирования голоса конкретных людей</a>
Способ и система моделирования углеводородсодержащего пласта

Номер патента: 3418
Опубликовано: 24.04.2003
Авторы: Хух Чун, Телецке Гари Ф., Ниварти Срирам С.
МПК: G06F 9/455, E21B 43/22
Метки: способ, система, моделирования, пласта, углеводородсодержащего
Формула / Реферат:
1. Способ моделирования одной или нескольких характеристик многокомпонентного, углеводородсодержащего пласта, при котором текучую среду, содержащую, по меньшей мере, один компонент, закачивают в пласт, по меньшей мере, через одну скважину для вытеснения содержащихся в пласте углеводородов, содержащий следующие стадии: (а) представление пласта, по меньшей мере, в одном направлении в виде множества элементов сетки; (б) деление, по меньшей мере,...
Способ моделирования характеристики физической системы

Номер патента: 3214
Опубликовано: 27.02.2003
Автор: Уоттс Джеймс В.III
МПК: G06N 7/08
Метки: характеристики, способ, моделирования, физической, системы
Формула / Реферат:
1. Способ моделирования, по меньшей мере, одной характеристики физической системы, включающий следующие шаги: (a) дискретизация физической системы на множество объемных ячеек, расположенных смежно друг с другом так, чтобы иметь границу между каждой парой смежных ячеек, (b) присвоение начальной оценки переменных состояния для каждой ячейки, (c) построение для каждой ячейки линейных уравнений, которые соотносят её переменные состояния с...
Спускной желоб для перемещения людей, животных и предметов.

Номер патента: 119
Опубликовано: 27.08.1998
Автор: Хельгедагсруд Пер Арне
Метки: спускной, животных, желоб, перемещения, людей, предметов
Формула / Реферат:
1. Спускной желоб (1) для перемещения людей, животных и предметов, содержащий днище (6) и два боковых борта (5, 19, 20), расположенных с каждой стороны днища (6) под углом к днищу (6), и приспособленный для прикрепления расположенным наиболее высоко верхним концом (9) к месту (21) выхода, а расположенным наиболее низко нижним концом (10) для прикрепления с возможностью отсоединения к приемнику (22), причем спускной желоб (1) состоит из...
Композиция для подавления симптомов абстиненции и тяги к алкоголю у алкоголиков и профилактики злоупотребления алкоголем у здоровых людей

Номер патента: 2177
Опубликовано: 28.02.2002
Авторы: Фаззи Альдо, Кавацца Клаудио
МПК: A61K 31/205, A23L 1/302
Метки: алкоголем, абстиненции, здоровых, алкоголю, подавления, алкоголиков, тяги, композиция, людей, профилактики, симптомов, злоупотребления
Формула / Реферат:
1. Перорально или парентерально вводимая композиция, содержащая смесь L-карнитина, ацетил-L-карнитина и пропионил-L-карнитина или их фармакологически приемлемых солей. 2. Композиция по п.1 в качестве лекарственного средства для подавления симптомов абстиненции и тяги к алкоголю у алкоголиков. 3. Композиция по п.1 в качестве пищевой добавки или пищевых продуктов для профилактики злоупотребления алкоголем у практически здоровых людей. 4....
Система и способ установления личности

Номер патента: 1050
Опубликовано: 28.08.2000
Автор: Хаувенер Роберт К.
МПК: H04L 9/32, G07F 7/12, G06K 19/067...
Метки: способ, система, установления, личности
Формула / Реферат:
1. Система установления личности, содержащая терминал пункта установления личности, имеющий средство для получения информации, предоставленной лицом, личность которого подлежит установлению в пункте установления личности, и средство для отображения цифровых фотографий, по меньшей мере, один удаленный узел базы данных, содержащий множество цифровых фотографий лиц, личность которых подлежит установлению, средство для осуществления связи между...
Предыдущий патент: Способ и система передачи базе данных цепочки сообщений
Следующий патент: Способ кислотного предварительного гидролиза биомассы
Случайный патент: Применение (е)-5-(4-хлорбензилиден)-2, 2-диметил-1-(1н-1,2,4-триазол-1- илметил)циклопентанола для борьбы со ржавчиной на растениях сои