Многоязыковая служба наименования доменов
Номер патента: 2513
Опубликовано: 27.06.2002
Авторы: Тан Тин Ви, Тэй Едвард С., Суббиа Субраманьян, Лим Кван Сионг, Леонг Кок Ионг, Тан Джуай Кванг, Сенг Чинг Хонг, Трейси Де Сильва Дон Ирвин
















Формула / Реферат
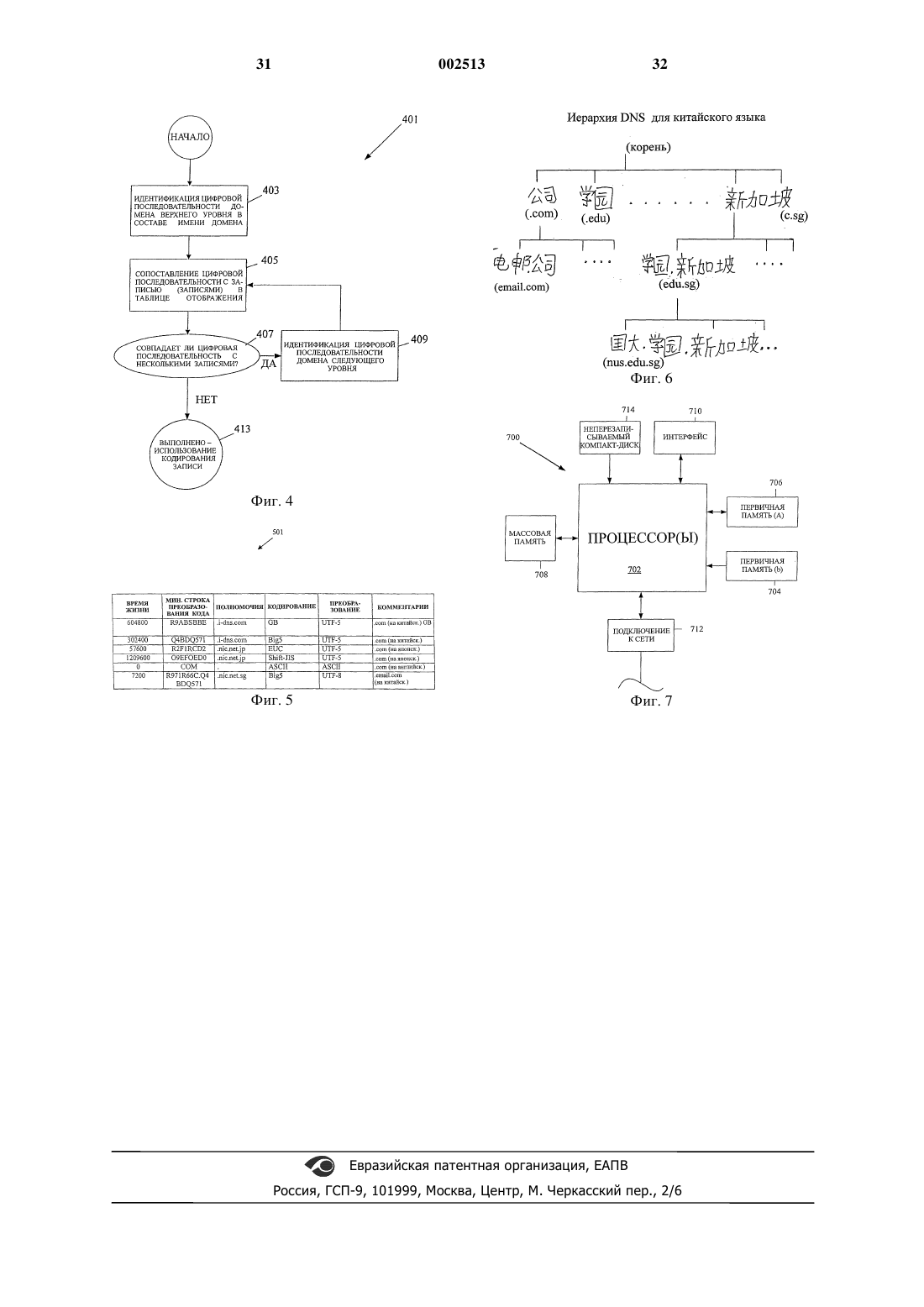
1. Способ, реализуемый на устройстве распознавания типа лингвистического кодирования имени домена в цифровом представлении, отличающийся тем, что содержит этапы
приема цифровой последовательности заданной части имени домена в цифровом представлении;
сопоставления указанной цифровой последовательности в составе имени домена с известной цифровой последовательностью в составе совокупности известных цифровых последовательностей, каждая из которых соответствует специфическому типу лингвистического кодирования, причем совокупность включает в свой состав известные цифровые последовательности, по меньшей мере, для двух различных типов лингвистического кодирования; и
идентификации типа кодирования, соответствующего известной цифровой последовательности, совпадающей с цифровой последовательностью в составе имени домена.
2. Способ по п.1, отличающийся тем, что содержит также этап приема запроса к DNS, содержащего имя домена в цифровом представлении.
3. Способ по п.1 или 2, отличающийся тем, что заданная часть имени домена в цифровом представлении является минимальной строкой преобразования кода в имени домена.
4. Способ по пп.1, 2 или 3, отличающийся тем, что содержит также этап преобразования формата цифровой последовательности имени домена в цифровом представлении, осуществляемый до этапа сопоставления этой цифровой последовательности.
5. Способ по любому из пп.1-4, отличающийся тем, что совокупность известных цифровых последовательностей представлена в виде таблицы, содержащей записи с атрибутами, включающими известные цифровые последовательности и типы кодирования.
6. Способ по п.5, отличающийся тем, что таблица включает в свой состав записи, имеющие, по меньшей мере, следующие типы кодирования: ASCII, BIG5, GB2312, Shift-JIS, EUC-JP, KSC5601 и расширенный ASCII.
7. Способ по п.5, отличающийся тем, что этап идентификации типа кодирования содержит этап идентификации типа кодирования записи, имеющей цифровую последовательность, совпадающую с известной цифровой последовательностью.
8. Способ по любому из пп.1-7, отличающийся тем, что, по меньшей мере, две известные цифровые последовательности совпадают с цифровой последовательностью в составе имени домена и тем, что содержит также этапы
приема цифровой последовательности второй части имени домена в цифровом представлении; и
сопоставления цифровой последовательности второй части с известной цифровой последовательностью в составе совокупности известных цифровых последовательностей.
9. Способ по п.2, отличающийся тем, что содержит также этапы
идентификации сервера DNS корневого уровня, ответственного за преобразование доменов корневого уровня с идентифицированным типом кодирования; и
передачи запроса к DNS в сервер DNS корневого уровня.
10. Способ по п.9, отличающийся тем, что содержит также этап преобразования цифровой последовательности имени домена из идентифицированного типа кодирования в тип кодирования DNS, совместимый с протоколом DNS, осуществляемый до этапа передачи запроса к DNS.
11. Способ по п.10, отличающийся тем, что тип кодирования DNS представляет собой ASCII или является универсальным типом лингвистического кодирования.
12. Способ по п.10, отличающийся тем, что этап преобразования цифровой последовательности имени домена содержит этапы
преобразования цифровой последовательности имени домена из идентифицированного типа кодирования в универсальный тип лингвистического кодирования; и
преобразования цифровой последовательности имени домена из универсального типа лингвистического кодирования в тип кодирования DNS, совместимый с протоколом DNS.
13. Компьютерный программный продукт, содержащий машиночитаемый носитель, на котором зарегистрированы команды программы для реализации способа распознавания типа лингвистического кодирования имени домена в цифровом представлении, отличающийся тем, что способ содержит этапы
приема цифровой последовательности заданной части имени домена в цифровом представлении;
сопоставления указанной цифровой последовательности в составе имени домена с известной цифровой последовательностью в составе совокупности известных цифровых последовательностей, каждая из которых соответствует специфическому типу лингвистического кодирования, и совокупности, включающей известные цифровые последовательности, по меньшей мере, для двух различных типов лингвистического кодирования; и
идентификации типа кодирования, соответствующего известной цифровой последовательности, совпадающей с цифровой последовательностью в составе имени домена.
14. Компьютерный программный продукт по п.13, отличающийся тем, что совокупность известных цифровых последовательностей представлена в виде таблицы, содержащей записи с атрибутами, включающими известные цифровые последовательности и типы кодирования.
15. Компьютерный программный продукт по п.13 или 14, отличающийся тем, что содержит также команды программы для реализации следующих этапов:
приема запроса к DNS, содержащего имя домена в цифровом представлении;
идентификации сервера DNS корневого уровня, ответственного за преобразование доменов корневого уровня с идентифицированным типом кодирования; и
передачи запроса к DNS в сервер DNS корневого уровня.
16. Компьютерный программный продукт по п.15, отличающийся тем, что содержит также команды программы для реализации следующего этапа:
преобразования цифровой последовательности имени домена из идентифицированного типа кодирования в тип кодирования DNS, совместимый с протоколом DNS, осуществляемого до этапа передачи запроса к DNS.
17. Таблица отображения типа лингвистического кодирования на машиночитаемом носителе, устанавливающая соответствие специфических типов лингвистического кодирования специфическим цифровым последовательностям, отличающаяся тем, что включает в свой состав множество записей, содержащих
известную цифровую последовательность заданной части имени домена в цифровом представлении; и
тип лингвистического кодирования, соответствующий известной цифровой последовательности.
18. Таблица отображения по п.17, отличающаяся тем, что заданная часть имени домена в цифровом представлении является цифровой последовательностью домена верхнего уровня в имени домена.
19. Таблица отображения по п.17 или 18, отличающаяся тем, что записи таблицы отображения включают в свой состав, по меньшей мере, следующие типы лингвистического кодирования: ASCII, BIG5, GB2312, Shift-JIS, EUC-JP, KSC5601 и расширенный ASCII.
20. Таблица отображения по пп.17, 18 или 19, отличающаяся тем, что записи содержат также сервер DNS верхнего уровня, ответственный за преобразование доменов корневого уровня с типом лингвистического кодирования, представленным в записи.
21. Таблица отображения по любому из пп.17-20, отличающаяся тем, что записи содержат также поле преобразования, предназначенное для преобразования типа кодирования в тип кодирования, совместимый с DNS.
22. Таблица отображения по любому из пп.17-21, отличающаяся тем, что записи содержат также поле времени жизни.
23. Таблица отображения по п.22, отличающаяся тем, что тип кодирования DNS является ASCII или универсальным типом лингвистического кодирования.
24. Устройство, отличающееся тем, что содержит
один или несколько процессоров;
память, соединенную, по меньшей мере, с одним из процессоров; и
один или несколько сетевых интерфейсов, обеспечивающих возможность приема первого запроса к DNS, включающего имя домена в типе кодирования не-DNS, и передачи запроса к DNS с именем домена, имеющем тип кодирования DNS, совместимый с протоколом DNS, причем, по меньшей мере, один из процессоров разработан или конфигурирован для преобразования имени домена с типом кодирования не-DNS в имя этого домена с типом кодирования DNS.
25. Устройство по п.24, отличающееся тем, что один или несколько сетевых интерфейсов соединены с сетью так, что обеспечивают устройству возможность осуществлять прием запросов клиентов к DNS, причем запросы клиентов к DNS представляют собой шья домена с типом кодирования не-DNS.
26. Устройство по п.24 или 25, отличающееся тем, что один или несколько сетевых интерфейсов соединены с сетью так, что обеспечивают устройству возможность осуществлять передачу запроса к DNS в стандартный сервер DNS, причем запрос к DNS представляет собой имя домена с типом кодирования DNS.
27. Устройство по пп.24, 25 или 26, отличающееся тем, что содержит также таблицу отображения, постоянно находящуюся, по меньшей мере частично, в памяти, причем таблица отображения сопоставляет специфические типы лингвистического кодирования со специфическими цифровыми последовательностями, которые предполагается найти в именах доменов, закодированных в цифровой форме.
28. Устройство по любому из пп.24-27, отличающееся тем, что, по меньшей мере, один процессор конфигурирован или разработан для идентификации типа кодирования имени домена не-DNS, осуществляемой до преобразования этого имени домена из типа кодирования не-DNS в тип кодирования DNS.

Текст
1 Предпосылки создания изобретения Настоящее изобретение относится к службе именования доменов, используемой для преобразования сетевых имен доменов в соответствующие сетевые адреса. В частности, изобретение касается альтернативной или модифицированной службы именования доменов, принимающей имена доменов, представленные во многих различных форматах кодирования, а не только в ASCII.Internet прошла путь развития от чисто исследовательского и академического объекта к глобальной сети, представляющей собой в настоящее время многообразное сообщество с различными языками и культурами. Во всех областях Internet прогрессировала в направлении адресации локализованных потребностей своей аудитории. Сегодня обмен электронной почтой осуществляется на большинстве языков мира. Ввиду распространения программных приложений, допускающих многоязычие, содержимое "всемирной паутины" в настоящее время издано на многих различных языках. Возможным стало пересылать сообщения по электронной почте другому человеку на китайском языке или просматривать страницу "всемирной паутины" на японском языке.Internet сегодня полностью базируется на системе именования доменов для преобразования названий, читаемых человеком, в числовыеIP-адреса и наоборот. Система именования доменов (DNS) до сих пор основывается на подмножестве алфавита латиница-1, следовательно,до сих пор, в основном, на английском языке. С целью обеспечения универсальности в адресах электронной почты, Web-адресах и других форматах адресации в Internet в качестве глобального стандарта, гарантирующего взаимодействие,принят ASCII. Отсутствует какое бы то ни было положение, допускающее использование электронной почты или Web-адресов на родном языке не-ASCII. Это подразумевает необходимость некоторых элементарных знаний символов ASCII для любого пользователя Internet. Использование ASCII не создает проблем для технических или деловых пользователей,которые, вообще говоря, способны понимать английский язык как международный язык науки, технологии, бизнеса и политики, но является камнем преткновения для быстрого распространения Internet в странах, где широкое общение на английском языке отсутствует. В таких странах начинающий пользователь Internet должен принять базовый английский язык в качестве необходимого условия пересылки электронной почты на своем собственном родном языке, потому что адрес электронной почты не может поддерживать родной язык даже при том условии, что приложение электронной почты такой способностью обладает. Корпоративные интрасети должны использовать ASCII для именования доменов своих отделений и Web 002513 2 документов просто потому, что протоколы не поддерживают никакого отличного от ASCII кода в поле имени домена, несмотря на то, что имена файлов и пути к каталогам в родном регионе могут быть многоязычными. Кроме того, пользователи европейских языков должны аппроксимировать имена своих доменов к форме, например, без диакритических знаков. Компания, подобная Citron, желающая иметь корпоративную идентичность,должна аппроксимировать свое название к наиболее близкому эквиваленту ASCII и использовать www.citroen.fr, а г-н Fransois (Франсуа) из Франции должен постоянно испытывать чувство раздражения от таких преднамеренных опечаток в адресе его электронной почты, как"francois.email.fr" (в качестве вымышленного примера). В настоящее время представление идентификаторов пользователей в поле адреса электронной почты может осуществляться в многоязычных сценариях, поскольку операционные системы могут быть локализованы с целью обеспечения шрифтов в соответствующем регионе. Каталоги и имена файлов также могут быть представлены в многоязычных сценариях. Однако на часть имени домена в составе этих имен накладывается ограничение стандартомInternet RFC 1035, представляющим собой стандарт системы именования доменов. Одна из причин, оправдывающих возникновение этой ситуации, может заключаться в стремлении разработчиков программного обеспечения к использованию перекрывающихся кодов. Например, типы кодирования китайского языка BIG5 и GB2312 (то есть цифровые представления глифов или символов) перекрываются между собой, аналогичная ситуация наблюдается и в случае с японскими языками JIS и ShiftJIS и корейским языком KSC5601. В результате,в случае отсутствия дополнительного параметра, определяющего тип кодирования, утрачивается возможность легкого распознавания различий между типами кодирования BIG5 и JIS илиGB2312 и KSC5601 и клиент приложения не информируется о типе используемого кодирования. Поэтому для обеспечения уникальности имен доменов и уверенности в кодированииDNS ориентируется на ASCII. В соответствии с RFC 1035 допустимые имена доменов в настоящее время ограничиваются подмножеством алфавита латиница-1, соответствующего стандарту ISO-8859, в состав которого входят только символы алфавита A-Z(без учета регистра), числа 0-9 и символ переноса (-). Это ограничение обеспечивает эффективность поддержки имени домена на английском языке или языках с романизированной формой типа малайского или ромадзи в японском языке или римской транслитерации типа транслитерированного тамильского. Никакой другой сцена 3 рий не приемлем, не могут быть использованы даже символы расширенного ASCII. Уникод представляет собой символьную систему кодирования, в которой почти каждый символ наиболее важных языков однозначно отображается 16-битовой величиной. Так как уникод является основой системы однозначного кодирования без перекрытия символов, некоторые исследователи начали исследования по использованию уникода в качестве базиса пространства имен для будущей DNS, которое сможет охватить богатое разнообразие языков народов мира на сегодня. См. М. Drst, "Интернационализация имен доменов", проект Internet"draft-duerst-dns-i18n-02.txt", который может быть найден на домашней странице комитетаInternet), http://www.ietf.cnri.reston.va.us/ID.html,июль 1998 г. Этот документ включается здесь в качестве ссылки во всей своей полноте и для всех целей. Новое пространство имен должно обладать способностью к предложению многоязычных и многосценарных функциональных возможностей, упрощающих использованиеInternet для неанглоязычных абонентов. Принятие уникода в качестве набора стандартных символов для новой системы именования доменов позволит избежать перекрытия кодовых пространств для различных языковых сценариев и, таким образом, обеспечить сообществу Internet возможность использования имен доменов в их родных сценариях, например:www.genve-city.ch К сожалению, на пути модифицирования сервера DNS при осуществлении многоязычной системы именования доменов возникают некоторые трудности. Например, необходимость модифицирования всех будущих приложений клиента и всех будущих серверов DNS. А поскольку обеспечение работы системы требует модифицирования как клиента, так и сервера, то переход от старой системы к новой может быть трудным. Кроме того, очень немногие доступные приложения клиента используют родной уникод. Вместо этого, большинство многоязычных приложений клиента осуществляет кодирование не в уникоде и имеет убежденных приверженцев такого способа. Ввиду этих и других проблем весьма желательным было бы иметь в распоряжении методику, обеспечивающую возможность использования в системе DNS множества типов лингвистического кодирования. Краткое изложение сущности изобретения Целью настоящего изобретения является создание системы и способов осуществления многоязычной системы именования доменов,обеспечивающей пользователям возможность использования имен доменов, закодированных не в уникоде и не в ASCII. Несмотря на то, что 4 способ может быть реализован в различных системах или комбинации систем, на настоящий момент времени система реализации будет именоваться сервером международной DNS (или сервером "iDNS"). В случае, если сервер iDNS сначала осуществляет прием запроса к DNS, то он определяет тип кодирования этого запроса. Определение типа кодирования может быть осуществлено в результате просмотра битовой строки в домене верхнего уровня, входящем в состав имени домена, и сопоставления этой строки со списков известных битовых строк для известных доменов верхнего уровня различных типов кодирования. Одна запись в списке может представлять собой битовую строку для ".com",например, на китайском языке BIG5. После идентификации типа кодирования имени домена сервер iDNS осуществляет преобразование типа кодирования имени домена в универсальный тип лингвистического кодирования (например, в уникод) и далее переводит представление из универсального типа лингвистического кодирования в представление в ASCII, соответствующее стандарту универсальной DNS. Затем переведенное имя домена передается в обычную систему именования доменов, которая распознает имя домена в формате ASCII и возвращает соответствующий IP-адрес. Одной из особенностей изобретения является создание способа распознавания типа лингвистического кодирования имени домена в цифровом представлении. Способ может быть охарактеризован следующей последовательностью: (а) прием цифровой последовательности заданной части (например, домена верхнего уровня) имени домена в цифровом представлении; (b) сопоставление цифровой последовательности в составе имени домена с известной цифровой последовательностью в составе совокупности известных цифровых последовательностей; и (с), идентификация типа кодирования,соответствующего известной цифровой последовательности, совпадающей с цифровой последовательностью в составе имени домена. Причем каждая из известных цифровых последовательностей, используемых в (b), соответствует специфическому типу лингвистического кодирования, а совокупность известных цифровых последовательностей включает в свой состав известные цифровые последовательности,по меньшей мере, для двух различных типов лингвистического кодирования. Часто бывает удобным представление этой совокупности в виде таблицы, содержащей записи с атрибутами, включающими известные цифровые последовательности и типы кодирования. В этом случае идентификация типа кодирования требует идентификации типа кодирования записи, имеющей совпадающую с известной цифровую последовательность. Примеры типов кодирования, представленных в таблице, вклю 5 чают в свой состав ASCII, BIG5, GB2312, ShiftJIS, EUC-JP, KSC5601 и расширенный ASCII. В случае совпадения, по меньшей мере,двух известных цифровых последовательностей с цифровой последовательностью в составе имени домена возникает необходимость в разрешении неоднозначности. Неоднозначность может быть разрешена в результате: (а) приема цифровой последовательности второй части имени домена в цифровом представлении; (b) многократного декодирования цифровой последовательности второй части с использованием схем декодирования различных типов лингвистического кодирования, каждый из которых соответствует, по меньшей мере, двум известным цифровым последовательностям; и (с) идентификации схемы декодирования, позволяющей получить наилучший результат. С другой стороны, разрешение неоднозначности может быть осуществлено в результате первого приема расширенной цифровой последовательности(включающей первую и вторую части имени домена) и последующего сопоставления этой расширенной последовательности с известными цифровыми последовательностями, которые могут соответствовать расширенной последовательности. В этом случае совокупность известных цифровых последовательностей должна включать в свой состав некоторые из расширенных последовательностей. В конкретном примере осуществления совокупность записей включает в свой состав цифровую последовательность (или представление цифровой последовательности), именуемую "минимальной строкой преобразования кода" (MCRS). Минимальная строка преобразования кода представляет собой цифровую последовательность для части имени домена и, как известно, служит отличием имени этого домена- в специфическом типе кодирования - от любой другой комбинации имени домена и типа кодирования в составе совокупности. MCRS может быть подстрокой домена верхнего уровня, верхней строкой домена верхнего уровня, переполнять домены второго и третьего уровней и т.д. до устранения неоднозначности и достижения совпадения. Как указано выше, способ, в частности,применяется при обработке запросов к DNS. Так, например, способ может также включать этапы: (i) приема запроса к DNS, содержащего имя домена в цифровом представлении; (ii) идентификации сервера DNS корневого уровня,ответственного за преобразование доменов корневого уровня идентифицированного типа кодирования; и (iii) передачи запроса к DNS в сервер DNS корневого уровня. До передачи запроса к DNS система должна преобразовать цифровую последовательность имени домена из идентифицированного типа кодирования в тип кодирования DNS, совместимый с протоколом DNS 6 в какой-нибудь другой универсальный тип кодирования в будущем). В предпочтительном примере осуществления это преобразование проводится в два этапа, включающих: (i) преобразование цифровой последовательности имени домена из идентифицированного типа кодирования в универсальный тип лингвистического кодирования; и (ii) преобразование цифровой последовательность имени домена из универсального типа лингвистического кодирования в тип кодирования DNS, совместимый с протоколом DNS. Предлагаемое изобретение, кроме того,обеспечивает таблицу отображения, которая сопоставляет специфические типы лингвистического кодирования со специфическими цифровыми последовательностями. Таблица отображения содержит множество записей, каждая из которых включает в свой состав следующие атрибуты: (а) известную цифровую последовательность заданной части имени домена в цифровом представлении; и (b) тип лингвистического кодирования, соответствующий известной цифровой последовательности. Заданная часть имени домена в цифровом представлении может быть цифровой последовательностью домена корневого уровня в составе имени домена. Записи могут также содержать сервер DNS верхнего уровня, ответственный за преобразование доменов верхнего уровня типа лингвистического кодирования в записи. Далее, таблица отображения может служить для определения типа преобразования, необходимого для преобразования имени домена из типа кодирования неDNS в совместимый с DNS (например, UTF-5). Изобретение также касается устройства,отличающегося тем, что содержит: (а) один или несколько процессоров; (b) память, соединенную, по меньшей мере, с одним из процессоров; и (с) один или несколько сетевых интерфейсов,обеспечивающих возможность приема первого запроса к DNS, включающего имя домена с типом кодирования не-DNS, и передачи запроса кDNS с именем домена, имеющим тип кодирования DNS, совместимый с протоколом DNS. По меньшей мере, один из процессоров разработан или конфигурирован для преобразования имени домена с типом кодирования не-DNS в имя этого домена с типом кодирования DNS. Один или несколько сетевых интерфейсов должны быть соединены с сетью так, чтобы обеспечить устройству возможность осуществлять прием запросов клиентов к DNS, представляющих собой имена доменов с типом кодирования не-DNS. Далее, один или несколько сетевых интерфейса должны быть соединены с сетью так, чтобы обеспечить устройству возможность осуществлять передачу запроса к DNS, представляющего собой имя домена с типом кодирования DNS, в стандартный сервер DNS. В предпочтительном варианте устройство также включает в свой состав таблицу отобра 7 жения (возможно, подобную одной из описанных выше), постоянно находящуюся, по меньшей мере, частично, в памяти. Далее, по меньшей мере, один процессор должен быть конфигурирован или разработан с целью идентификации типа кодирования имени домена не-DNS,осуществляемой до преобразования этого имени домена из типа кодирования не-DNS в тип кодирования DNS. Эти и другие особенности и преимущества настоящего изобретения будут описаны более подробно ниже со ссылками на чертежи. Краткое описание чертежей Фиг. 1 - схематическое изображение сетевой архитектуры, включающей сервер iDNS,установленный между сервером DNS и клиентом. Фиг. 2 - структурная схема процесса преобразования запроса к DNS, представляющего собой имя домена с типом кодирования не-DNS,в соответствии с одним примером осуществления настоящего изобретения. Фиг. 3 А - структурная схема процесса преобразования имени домена с типом кодирования не-DNS в соответствующее имя домена с типом кодирования DNS. Фиг. 3 В - логические компоненты системыiDNS. Фиг. 4 - структурная схема процесса определения типа кодирования имени домена. Фиг. 5 - логическая таблица отображения,используемая для идентификации типов кодирования имен доменов в соответствии с одним примером осуществления этого изобретения. Фиг. 6 - "древовидная" иерархическая структура системы именования доменов для китайского языка. Фиг. 7 - блок-схема универсальной компьютерной системы, которая может быть использована для реализации функций iDNS настоящего изобретения. Подробное описание предпочтительных примеров осуществления 1.DNS и уникод. Настоящее изобретение обеспечивает преобразование многоязычных многосценарных имен в формат, соответствующий DNS (например, DNS в толковании RFC 1035 от 1999 г.). Эти преобразованные имена могут быть далее переданы в качестве запросов к DNS на сервер обычной DNS. Типичный процесс преобразования локализованного имени домена в свой числовой IP-адрес представлен ниже со ссылками на фиг. 1. Однако перед описанием фиг. 1 будут рассмотрены некоторые базовые принципы и термины. Программы редко обращаются к хосткомпьютерам и другим ресурсам с помощью своих двоичных сетевых адресов. Вместо двоичных чисел они используют строки ASCII типаwww.pobox.org.sg. Однако сеть сама по себе только интерпретирует двоичные адреса, и по 002513 8 этому для преобразования строк ASCII в сетевые адреса требуется некий механизм. Такой механизм обеспечивается системой именования доменов. По существу, DNS представляет собой иерархическую схему присвоения имен на основе доменов и систему распределенной базы данных для реализации этой схемы именования. Прежде всего схема используется для отображения имен хост-компьютеров и адресатов электронной почты в IP-адресах, но возможны и другие цели. Как указано выше, определение DNS приведено в RFC 1034 и RFC 1035. Если очень кратко, то путь использованияDNS состоит в следующем. Для отображения имени в IP-адресе прикладная программа обращается к библиотечной процедуре под названием "преобразователь", передавая через нее это имя в качестве параметра. Преобразователь пересылает пакет протоколов дейтаграмм пользователя (UDP) на сервер локальной DNS, который далее просматривает имя и возвращает IPадрес преобразователю, который, в свою очередь, возвращает его вызывающей программе. Снабженная IP-адресом, программа может установить соединение TCP (использующее протокол управления передачей данных) с адресатом или переслать ему пакеты UDP. В общем представлении сеть Internet разделена на множество "доменов" верхнего уровня, так как каждый домен охватывает множество хост-компьютеров. Каждый домен разбит на поддомены, которые, в свою очередь, также разбиты на домены более низкого уровня, и так далее. Все эти домены могут быть представлены деревом. Листья дерева являются доменами,которые не имеют никаких поддоменов (но, конечно, содержат машины). Домен в виде листа может содержать единичный хост-компьютер или представлять собой компанию, которая содержит тысячи хост-компьютеров. Существует две разновидности доменов верхнего урoвня - организационные и географические. Организационные домены имеют имена соm (коммерческие организации), edu (образовательные учреждения), gov (федеральное правительство США), int (определенные международные организации), mil (вооруженные силы США), net (сетевые поставщики услуг) и org(некоммерческие организации). Географические домены представляют собой одну запись для каждой страны, как определено в стандарте ISO 3166. Каждый домен содержит в своем имени путь наверх в направлении безымянного корня. Компоненты имени разделены промежутками(обозначенными "точками"). В принципе, домены могут быть установлены на дереве двумя различными способами. Например, домен с именем cs.ucb.edu может также являться членом домена us, то есть географическим доменом с именем cs.ucb.ct.us. Однако на практике почти все организации в 9 США принадлежат к организационным доменам, а имена доменов почти всех организаций в иностранных по отношению к США государствах имеют в своем составе название своей страны. Не существует никакого запрета на регистрацию имени под двумя доменами верхнего уровня, но назначение такого имени вызывает путаницу и не многие организации используют такой способ именования. Каждый домен осуществляет управление назначением доменов более низкого уровня. Например, Япония имеет домены ac.jp и co.jp,которые отражают edu и соm. Для создания нового домена требуется разрешение домена, в состав которого этот новый домен будет включен. Например, для регистрации группы специалистов по системам искусственного интеллекта, созданной при университете города Беркли в штате Калифорния, под именемai.cs.ucb.edu, требуется разрешение от администратора cs.ucb.edu. Точно так же в случае создания нового университета, скажем, университета на озере Тахоэ, для назначения имениulth.edu. потребуется разрешение администратора домена edu. Таким образом удается избежать возникновения конфликтов имен и обеспечивается возможность слежения каждого домена за всеми своими поддоменами. При создании и регистрации новый домен получает возможность создания своего собственного поддомена,например cs.ulth.edu, не требующего получения разрешения от какого-либо вышестоящего объекта на дереве. В теории, по меньшей мере, один сервер имен может содержать полную базу данныхDNS и отвечать на все запросы к DNS. Однако на практике это вызвало бы перегрузку сервера и обусловило бы его полную бесполезность. Кроме того, реализация подобной возможности привела бы к нарушению целостности сетиInternet. С целью предотвращения возникновения проблемы, связанной с наличием только одного источника информации, пространство имен DNS разделено на неперекрывающиеся"зоны". Каждая зона содержит некоторую часть дерева и кроме того содержит серверы имен,хранящие надежную информацию об этой зоне. Как правило, зона имеет один первичный сервер имен, который получает свою информацию из файла на своем диске, и один или несколько вторичных серверов имен, которые получают свою информацию от первичного сервера имен. Когда преобразователь получает запрос на имя домена, то он передает запрос на один из локальных серверов имен. Если разыскиваемый домен подпадает под юрисдикцию сервера имен, как, например, ai.cs.ucb.edu под cs.ucb.edu,преобразователь возвращает надежные записи ресурса. Надежная запись представляет собой запись, основанную на полномочиях управления записью, и, таким образом, является всегда правильной. Заданный сервер имен может, кроме 10 того, содержать "кэшированные записи", которые могут быть устаревшими. Если интересующий домен находится на удалении и любая информация о требуемом домене является недоступной локально, сервер имен пересылает сообщение о запросе в сервер имен верхнего уровня для требуемого домена. Например, локальный сервер имен, осуществляющий поиск IP-адреса для ai.cs.ucb.edu, может переслать пакет UDP на сервер eduserver.net для edu, заданного в своей базе данных. Маловероятно, что этот сервер знает адресcs.ucb.edu, но поскольку он должен знать все свои собственные дочерние адреса, то пересылает запрос в сервер имен для ucb.edu. В свою очередь, этот сервер пересылает запрос кcs.ucb.edu, который должен иметь надежные записи ресурса. Так как каждый запрос пересылается от клиента на сервер, то требуемая надежная запись прокладывает себе путь назад в исходный сервер имен, запрашивающий IPадрес для ai.cs.ucb.edu. Как только запись возвращается в исходный сервер имен, то в случае необходимости последующего использования она вводится в кэш-память. Однако эта информация не является надежной, так как изменения, сделанные вcs.usb.edu, не будут переданы во все устройства кэш-памяти в мире, который может знать об этих изменениях. По этой причине запись в кэш-память должна подвергаться частому удалению или изменению. Это может быть реализовано с помощью поля "времени жизни",включенного в каждую запись. Указанный выше пример способа преобразования имени домена относится к рекурсивным запросам. Существуют и другие методики. Для получения более подробной информации о DNS см. книгу Andrew S.Tanenbaum, "Сети ЭВМ",3-я ред., Prentice Hall, Upper Saddle River, NJ(1996), из которой было заимствовано многое из приведенного выше материала. См., кроме того,U.D. Black, "ТСР/IР и другие сетевые протоколы", 3-я ред., McGraw-Hill, San Francisco, CA(1998). Обе эти ссылки приводятся здесь в качестве ссылок для всех целей. Как отмечено выше, протокол DNS в настоящее время базируется на подмножествеASCII и, таким образом, ограничен латинским алфавитом. Цифровое представление для других множеств символов мира обеспечивают многочисленные другие типы кодирования. Примеры включают в свой состав BIG5 и СВ-2312 для иероглифических сценариев китайского языка(традиционного и упрощенного соответственно). Shift-JIS и EUC-JP для иероглифических сценариев японского языка, KSC-5601 для иероглифических сценариев корейского языка и символы расширенного ASCII для символов,например, французского и немецкого языков. 11 Помимо этих специфически языковых типов кодирования существует стандарт на уникод ("универсальный тип лингвистического кодирования"), который обеспечивает возможность кодирования всех символов, используемых в письменных языках мира. Стандарт использует 16-битовое кодирование, обеспечивающее получение кодовых точек для более чем 65000 символов. Сценарии уникода включают в свой состав следующие алфавиты: латинский,греческий, кириллицу, армянский, еврейский,арабский, деванагари, бенгальский, гурмуки,гуджарата, орийский, тамильский, телугу, канадский, малаяламский, тиаский, лаосский, грузинский, тибетский, а также японскую кану,полную систему современного корейского хангула и объединенное множество китайскояпонско-корейских (CJK) идеограмм. В ближайшее время эти сценарии должны будут дополнены многими другими сценариями и символами, включая алфавиты: эфиопский, канадский, силлабический, чероки, сингальский, сирийский, бирманский, кхмерский, а также дополнительные редкие идеограммы и шрифт Брайля (для слепых). Каждому элементу кода, определяемому стандартом на уникод, присвоено единичное 16 битовое число. Каждое из этих 16-битовых чисел носит название кодовой величины и при упоминании в тексте приводится в шестнадцатеричной форме после префикса "U". Например,кодовая величина U+0041 является шестнадцатиричным числом 0041 (равным десятичному числу 65) и представляет собой в стандарте на уникод символ "А". Кроме того, каждому символу присвоено уникальное имя, обеспечивающее однозначное определение этого символа. Например, кодовой величине U+0041 присвоено имя символа "прописная буква А латинского алфавита", а кодовой величине U+OA1B -имя символа "слог ЧА алфавита гурмуки". Эти имена уникода идентичны именам стандарта ISO/IEC 10646 для тех же самых символов. Стандарт на уникод группирует символы друг с другом с помощью сценариев в кодовые блоки. Сценарий представляет собой любую систему связанных символов. По возможности стандарт сохраняет порядок символов в исходном множестве. При традиционном размещении символов сценария в определенном порядке,например в алфавитном порядке, стандарт на уникод упорядочивает их в кодовом пространстве с использованием того же самого порядка при каждом удобном случае. Кодовые блоки в значительной степени отличаются по размеру. Например, кодовый блок кириллицы не превышает 256 кодовых величин, в то время как кодовый блок CJK имеет диапазон в тысячи кодовых величин. Элементы кода сгруппированы логически по всему диапазону кодовых величин, называе 002513 12 мому "кодовым пространством". Система кодирования начинается стандартными символамиASCII с кодовой величины U+0000 и продолжается греческим алфавитом, кириллицей, еврейским, арабским, индийским и другими сценариями, далее сопровождаемыми символами и пунктуацией. Кодовое пространство продолжается хираганой, катаканой и бопомофо. Объединенные идеограммы ханы сопровождаются полной системой современного хангула. Диапазон замещения кодовых обозначений зарезервирован для будущего расширения кодового пространства форматом преобразования UTF-16. На своем конечном участке кодовое пространство представляет собой диапазон кодовых величин,зарезервированных для частного использования,сопровождаемый диапазоном символов совместимости. Символы совместимости являются вариантами символов, закодированных исключительно для обеспечения перехода к более ранним стандартам кодирования и старым разработкам, использовавшим эти стандарты. Стандарты кодирования символов определяют не только идентичность каждого символа и его числовой величины или разряда кода, но и представление этой величины в битах. Стандарт на уникод подтверждает, по меньшей мере, три формы, соответствующие форматам преобразования ISO 10646, UTF-7, UTF-8 и UTF-16. Соответствующие ISO/IEC 10646 форматы преобразования UTF-7, UTF-8 и UTF-16 являются, по существу, способами превращения символов кодирования в фактические биты, которые используются в реальности. UTF-16 допускает 16-битовые символы и позволяет использовать определенный диапазон символов в качестве механизма расширения с целью обращения к дополнительному миллиону символов,использующих 16-битовые пары. Стандарт на уникод по версии 2.0, разработанной AddisonWesley Longman (1996) (с модификациями и добавлениями, введенными через "Стандарт на уникод по версии 2.1), заимствовал этот формат преобразования в определении, приведенном вISO/IEC 10646. Эта ссылка приводится здесь в качестве ссылки во всей своей полноте и для всех целей. Второй формат преобразования известен как UTF-8. Это - способ преобразования всех символов уникода в символы кодирования байтов переменной длины. Преимущества этого способа заключаются в окончании символов уникода, соответствующих знакомому множеству ASCII, на те же самые значения байтов, как и в ASCII, и возможности использования этих символов уникода, преобразованных в UTF-8,со многими существующими программными средствами без дополнительных перезаписей программ. Консорциум уникода, кроме того,подтверждает использование UTF-8 в качестве способа реализации стандарта на уникод. Любой символ уникода, выраженный в 16-битовой 13 форме UTF-16, может быть преобразован в форму UTF-8 и поддерживаться без потери информации. Стандарт на уникод определяет однозначные требования для соответствия, основанные на принципах и архитектуре системы кодирования, которую этот стандарт реализует. Соответствующая разработка имеет следующие характеристики, приводимые в качестве необходимого условия: символы представляют собой 16-битовые единицы; символы должны быть интерпретированы в семантике уникода; отмененные коды не используются; и неизвестные символы не подлежат разрушению. Реализация стандарта на уникод совместима с использованием UTF-8 в процессе обработки каждого символа уникода (последовательности байтов) в формате UTF-8 как соответствующей 16-битовой единицы и иной интерпретации символов, соответствующих спецификации уникода. Требования полного соответствия доступны в рамках стандарта на уникод версии 2.0, разработанной Addison Wesley Longman(1996) и предварительно включенной в качестве ссылки UTF-7, предназначенной для обеспечения 7-битовых символов, которые используются для 7-битовых носителей и средств передачи данных. Электронная почта в толковании, приведенном в RFC 822, например, является 7 битовой системой. UTF-16 предназначен для 16 битовых носителей и средств передачи данных,а UTF-8 - для 8-битовых. Большинство средств передачи данных в Internet являются 8 битовыми, но имеются унаследованные системы, использующие 7-битовые данные (например, DNS, электронная почта с упрощенным протоколом пересылки и т.д.). 2. Терминология. Некоторые из рассматриваемых здесь терминов обычно не используются в данной области техники. Другие термины имеют множество значений. Поэтому целью приводимых ниже определений является обеспечение помощи в понимании описания изобретения. Причем в пределах помещенной ниже формулы изобретение не обязательно ограничивается рамками этих определений. Тип лингвистического кодирования - любой тип кодирования символов или глифов (например, ASCII или BIG5), известного в настоящее время или использованного в будущем. Универсальный тип лингвистического кодирования - любой тип лингвистического кодирования, известного в настоящее время или разработанного в будущем, охватывающий более чем одно множество символов или глифов в пределах своей системы кодирования. Уникод - один из примеров. BIG5, iso-8859-11 и GB-2312 - другие примеры. 14 В цифровом представлении - способ представления символов в результате кодирования(например, в битовом потоке, шестнадцатиричном формате и т.д.). Цифровая последовательность - специфическая последовательность единиц и нулей, шестнадцатиричных символов или других непосредственных составляющих в цифровом представлении."Часть" имени домена в цифровом представлении - любая область или все имя домена полностью, например домен верхнего уровня,домен второго уровня, домен верхнего и второго уровней вместе.- цифровая последовательность, представляющая интерес вследствие известности своего соответствия некоторой широко используемой комбинации символов (или другому атрибуту имени домена), закодированной в специфическом типе кодирования (например, цифровая последовательность BIG5 для ".соm")."Совокупность" известных цифровых последовательностей - любое сочетание или соединение множества известных цифровых последовательностей, как правило, хотя и не обязательно, хранимых вместе в логическом формате в виде таблицы (например, "таблицы отображения", описываемой здесь). Тип кодирования DNS - тип кодирования,поддерживаемый протоколом DNS сети илиASCII, определенное в RFC 1035. Тип кодирования не-DNS - тип кодирования, не поддерживаемый рассматриваемым протоколом DNS, например BIG5, рассматриваемый в RFC 1035. 3. Реализация iDNS. Обратимся теперь к фиг. 1. Некоторые важные компоненты сети 10, используемой в примере осуществления этого изобретения,включают в свой состав клиента 12, соответствующий узел 14, с которым клиент 12 желает установить связь, сервер iDNS 16 и сервер обычной DNS 18. Сервер iDNS 16 может осуществлять прием сигналов на порте DNS (в настоящее время адресованном в порт имен доменов 53) для многоязычных запросов на имена доменов вместо сервера стандартной DNS, который может включать в свой состав домен с именем университета Беркли в сети Internet("BIND" и выполняемую им версию "с присвоенным именем"), представляющий собой широко используемый сервер DNS, написанный Паулем Викси (http://www.isc.org/). Для уяснения роли этих компонентов предположим, что клиент 12 используется студенткой-китаянкой, желающей осуществить запрос о занятости в гонконгской фирме, управляющей соответствующим узлом 14. Предварительно студентка связывается с фирмой и узнает имя домена этой фирмы. Имя домена представ 15 лено иероглифами родного китайского языка. Клиент 12 имеет клавиатуру с возможностью печати китайских иероглифов, конфигурированную с помощью программного обеспечения,способного распознавать закодированные китайские иероглифы и точно отображать их на экране компьютера. Далее студентка готовит сообщение в гонконгскую фирму, прилагает свое резюме и печатает имя домена на китайском языке в качестве адресата. Когда она подает команду клиенту 12 на пересылку сообщения на соответствующий узел 14, система, показанная на фиг. 1, выполняет следующие операции. Сначала имя домена соответствующего узла представляется на родном языке в сервер iDNS 16 через запрос к DNS. Сервер iDNS 16 распознает, что имя домена представлено в формате, который не может быть обработан сервером обычной DNS, и поэтому переводит имя домена на китайском языке в формат, который может использоваться сервером обычной DNS (обычно ограниченное множество символов ASCII). Сервер iDNS 16 переупаковывает запрос DNS с переведенным именем домена соответствующего узла и передает этот запрос на сервер обычной DNS 18. Сервер DNS 18 далее использует протокол стандартной DNS с целью получения сетевого адреса для имени домена, указанного в запроса к DNS. Полученный сетевой адрес представляет собой сетевой адрес соответствующего узла 14. Затем сервер DNS 18 упаковывает сетевой адрес, соответствующий протоколу обычной DNS,и пересылает адрес назад на сервер iDNS 16. Сервер iDNS 16, в свою очередь, передает необходимый сетевой адрес назад клиенту 12, на котором размещено сообщение студентки. Сообщение оформляется в виде пакетов, каждый из которых имеет целевой сетевой адрес соответствующего узла 14. Клиент 12 далее пересылает пакеты сообщений по Internet на узел 14. Более полному пониманию этой процедуры может способствовать рассмотрение операций, изображенных на фиг. 2 в виде структурной схемы процесса взаимодействия клиента и серверов. Как показано на этой фигуре, клиент 12 представлен вертикальной линией с левой стороны, сервер DNS 16 изображен вертикальной линией в центре, а сервер DNS 18 - вертикальной линией с правой стороны. Вначале, на этапе 203, приложение, выполняемое на клиенте 12, генерирует сообщение, предназначенное для сетевого адресата. Имя домена для этого адресата вводится в формате кодирования текста, не совместимом сDNS. Поэтому, текст кодируется с использованием типа лингвистического кодирования,обеспечивающего представление символов текста в цифровой форме. Как указывалось выше,ASCII представляет собой всего лишь один тип лингвистического кодирования. В предпочтительных примерах осуществления изобретение 16 оперирует с широким диапазоном типов кодирования. В состав примеров некоторых из широко используемых типов кодирования входятGB2312, BIG5, Shift-JIS, EUC-JP, KSC560, расширенный ASCII и другие. После того как приложение клиента создает сообщение на этапе 203, операционная система клиента создает запрос к DNS на преобразование имени домена на этапе 205. Запрос кDNS может иметь большое сходство с запросом к обычной DNS. Однако имя домена, представленное в запросе, будет иметь формат кодирования не-DNS. На этапе 207 операционная система клиента передает его запрос к DNS на сервер iDNS 16. Следует обратить внимание на то,что операционная система клиента может быть конфигурирована для пересылки запросов кDNS в сервер iDNS 16. Другими словами, заданный по умолчанию сервер DNS клиента 12 представляет собой сервер iDNS 16. Сервер iDNS 16 декодирует закодированное имя домена из запроса к DNS и генерирует преобразованный запрос к DNS, представляющий имя домена в формате кодирования, совместимом с DNS (в настоящее время сокращенное множество ASCII, определенное в RFC 1035). См. этап 209. Сервер iDNS 16 далее передает свой запрос к DNS в сервер обычной DNS 18. См. этап 211. Сервер имен затем использует протокол обычной DNS для получения IPадреса имени домена, используемого в связи с клиентом. См. этап 213. Далее, на этапе 215,сервер имен пересылает в сервер iDNS требуемый IP-адрес. Сервер iDNS 16 затем передаетIP-адрес назад клиенту 12 на этапе 217. Наконец, снабженный теперь IP-адресом клиент 12 пересылает свою связь назначенному адресату. См. этап 219. Как отмечено выше, имя домена в некоторой точке должно быть преобразовано из типа кодирования не-DNS в тип кодирования, совместимый с DNS. В рассмотренных выше примерах эта операция выполняется уполномоченным сервером iDNS. Использование сервераiDNS не является обязательным условием, однако в качестве необходимой функциональной возможности преобразование может быть выполнено на клиенте или сервере обычной DNS. В альтернативных примерах осуществления функции, выполняемые уполномоченным сервером iDNS, в целом (или частично) реализуются на клиенте и/или на сервере DNS. В одном примере осуществления операции, включая распознавание типа кодирования, перевод имени домена с типом кодирования не-DNS в имя домена с типом кодирования DNS и идентификацию заданного по умолчанию сервера имен(этапы 305-311 на фиг. 3 А, представляющей собой структурную схему, обсуждаемую ниже),реализуются на приложении Internet (например,на Web-броузере, допускающем многоязычие). В этом примере осуществления операции распо 17 знавания и преобразования кода автоматически выполняются до планирования запроса на преобразование к DNS, пересылаемого на серверDNS. В некоторых примерах осуществления приложение может обеспечивать ручную реализацию определенного лингвистического кодирования, которое устраняет потребность в распознавании кода. В другом альтернативном примере осуществления этапы 305-311 могут быть выполнены на сервере iDNS. Другие примеры осуществления включают свертывание всех или некоторой части операций уполномоченного iDNS на сервер DNS. Например, код для некоторых функций iDNS может быть свернут в код BIND в качестве компилируемого модуля. На фиг. 2 преобразование имени домена из одного типа лингвистического кодирования во второй тип лингвистического кодирования (совместимый с DNS) выполняется на этапе 209. Как показано на фиг. 3 А, в соответствии с предпочтительным примером осуществления этого изобретения это преобразование может быть реализовано через процесс 301. Процесс начинается с этапа 303, на котором система идентифицирует тип кодирования имени домена в запросе к DNS. Это необходимо в случае возможных конфликтов системы со множеством различных типов кодирования. После осуществления идентификации типа кодирования система затем определяет на этапе 305 совместимость типа кодирования имени домена с DNS. В настоящее время это требует подтверждения или неподтверждения системы кодирования имени домена с использованием сокращенного множества ASCII. В случае подтверждения дальнейшее преобразование становится ненужным и управление процессом переходит на этап 311,описываемый ниже. Интерес представляет случай кодирования имени домена в формате не-DNS. При этом управление процессом переходит на этап 307, на котором система переводит имя домена в универсальный тип кодирования. В предпочтительном примере осуществления этот универсальный тип кодирования представляет собой уникод. В этом случае символы, идентифицированные в родном типе кодирования, идентифицируются в стандарте на уникод и преобразуются в цифровую последовательность уникода для этих символов. Вновь переведенное имя домена далее преобразуется из универсального типа кодирования в тип кодирования, совместимый с DNS. См. этап 309. Так, этот конечный тип кодирования может представлять собой сокращенное множество ASCII. Следует обратить внимание на то, что перевод из формата, не совместимого с DNS, в формат, совместимый с DNS, проводится в два этапа с использованием промежуточного универсального типа кодирования. Эта двухэтапная процедура детализируется ниже. 18 Понятно, однако, что преобразование имени домена, не совместимого с DNS, в имя домена,совместимое с DNS, может быть осуществлено напрямую, за один этап. Такая операция может быть выполнена в системе, имеющей множество алгоритмов преобразований, каждый из которых предназначен для преобразования конкретного типа кодирования в ASCII (или в некоторый другой будущий тип кодирования, совместимый с DNS). В одном из примеров эти алгоритмы могут быть смоделированы по типу "алгоритма Дюрста", указанного выше. Известны или с использованием стандартной методики могут быть разработаны и многие другие подходящие алгоритмы. Теперь снабженной именем домена, совместимым с DNS, системе требуется определить только сервер имен обычной DNS, на который она должна переслать имя домена. В соответствии с протоколом стандартной DNS запрос к DNS мог бы быть направлен на сервер имен верхнего уровня. Как будет описано более подробно ниже, удобным представляется наличие различных корневых серверов имен, обрабатывающих различные лингвистические домены. Например, правительство Китая может поддерживать корневой сервер имен для имен доменов на китайском языке, правительствo Японии или японская корпорация может поддерживать корневой сервер имен для имен доменов на японском языке, правительство Индии - корневой сервер имен для имен доменов на хинди и т.д. В любом случае на этапе 311, как показано на фиг. 3 А, система должна идентифицировать соответствующий сервер имен. После выполнения этой операции процесс преобразования завершается, и запрос к DNS может быть передан в систему DNS для обработки в соответствии с соглашением. Предпочтительным вариантом является выполнение процесса, изображенного на фиг. 3 А,исключительно на сервере iDNS. Однако часть процесса может быть выполнена на клиенте или на сервере обычной DNS. Например, этапы 303 и 305 могут быть выполнены на клиенте, а этап 309 - на сервере обычной DNS. Предпочтительное разделение труда для функции iDNS (этап 327) представлено на фиг. 3 В. Как показано на этой фигуре, сервер отображения iDNS 321 выполняет операции 305-311. С этой целью он включает в свой состав таблицу отображения (пример которой описан ниже со ссылками на фиг. 5) и может обеспечить преобразование всех типов лингвистического кодирования в уникод (или другой подходящий универсальный тип кодирования). В этом примере осуществления клиент 325 выполняет операцию 303, а сервер обычной DNS 323 реализует протокол преобразования стандартной DNS. В одном из примеров реализации сервер отображения iDNS 321 работает на машинеi2.i-dns.com) на назначенном порте (например, с номером 2000). Этот сервер принимает целую часть имени домена в цифровом представлении в любом типе лингвистического кодирования и возвращает целую часть имени домена в цифровом представлении в уникоде, преобразованном в тип кодирования DNS (UTF-5). Следует обратить внимание на то, что таблица отображения и код программы преобразования могут быть достаточно большими и приводить тем самым к увеличению размера сервера DNS 323 в несколько раз (при их реализации на этом сервере). В случае отделения операций 305-311 от протокола DNS и раздельном их выполнении величина кода, требующегося для распределения iDNS, уменьшается. Как указано при обсуждении фиг. 3 А, в случае необходимости обработки множества типов кодирования система должна обладать способностью отличать один тип кодирования от другого. Этот процесс отображен блоком 303 и представлен в деталях на фиг. 4. Как показано на фиг. 4, процесс идентификации типа кодирования 401 начинается с этапа 403, на котором система идентифицирует цифровую последовательность домена верхнего уровня в составе имени домена. На март 1999 г. в состав доменов верхнего уровня системы входили .com, .edu, .gov, .mil, .org, .int, .net и различные географические домены с двухбуквенным обозначением названий стран (например,.fr, .xg, .kr и т.д.). После идентификации цифровой последовательности домена верхнего уровня система затем сопоставляет эту последовательность со специфическим типом кодирования. В предпочтительном примере осуществления эта операция включает в свой состав сопоставление последовательности с записями в таблице отображения на этапе 405. Типичная таблица отображения будет описана более подробно ниже. Пока просто следует уяснить, что таблица (или другая логическая структура) включает в свой состав список цифровых последовательностей для различных доменов верхнего уровня с различными типами лингвистического кодирования, обрабатываемых системой. Каждая отдельная запись,кроме того, включает в свой состав соответствующий идентификатор типа кодирования. Система сопоставляет рассматриваемую цифровую последовательность путем ее простого сравнения с последовательностями в различных записях таблицы отображения (используя процедуру просмотра стандартной базы данных, например двоичный поиск, хеш-таблицу, В-дерево и т.д.). Как правило, это обеспечивает однозначное соответствие. Однако в случае, если ответственность за назначение доменов верхнего уровня несет множество объектов (каждый из которых,например, является ответственным за свой язык), то существует возможность идентичности цифровых последовательностей для двух 20 доменов верхнего уровня в различных форматах кодирования. С целью адресации этой возможности система определяет на этапе 407 совпадение или отсутствие совпадения множества записей с рассматриваемой цифровой последовательностью. В случае отсутствия такого совпадения процесс завершается на этапе 413, поскольку система принимает решение использовать кодирование, идентифицированное в единичной совпадающей записи. С другой стороны, в случае совпадения двух или нескольких записей возникает необходимость в разрешении неоднозначности. При этом система вначале идентифицирует цифровую последовательность домена низшего уровня (например, поддомена типа домена второго уровня). См. этап 409. Другими словами, рассматриваемое имя домена будет иметь цифровую последовательность, соответствующую доменам более низкого уровня. Полученную расширенную цифровую последовательность повторно сопоставляют с цифровыми последовательностями в таблице отображения(405). Следует обратить внимание на то, что некоторые записи таблицы могут включать в свой состав цифровые последовательности для объединения доменов верхнего и более низкого уровней (для преобразования потенциальной неоднозначности в последовательностях доменов верхнего уровня). После нахождения совпадения на этапе 405, как описано выше, процесс продолжается через этап 407. В альтернативном примере осуществления в таблице отображения поддерживаются только цифровые последовательности для доменов верхнего уровня. Не предусматривается никаких расширенных последовательностей для разрешения неоднозначностей. В этом случае при утвердительном ответе на вопрос, задаваемый на этапе 407 (случай совпадения множества записей), система идентифицирует каждое из потенциальных совпадений (возможных типов кодирования). Далее рассматриваемая последовательность декодируется с использованием каждого из потенциальных типов кодирования. Например, цифровая последовательность корневого домена могла совпасть для .net в одном из типов кодирования на японском языке и .соm в одном из типов кодирования на китайском языке. Одна из декодированных строк должна быть интерпретирована на языке возможного типа кодирования. Другая (другие) должна представлять собой "мусор". Таким образом,система выбирает возможный тип кодирования,обеспечивающий лучшую систему декодирования вторичного домена. Далее, на этапе 413 процесс заканчивается, причем система использует выбранный тип кодирования. Как указано на этапе 405 при обсуждении фиг. 4, сервер iDNS может сопоставлять цифровую последовательность для домена верхнего 21 уровня в запросе на имя домена с известными цифровыми последовательностями для множества типов кодирования. Таблица отображения может содержать известные цифровые последовательности. На фиг. 5 представлена таблица отображения 501, соответствующая одному из примеров осуществления этого изобретения. Каждая запись в таблице 501 определяет минимальную строку преобразования кода (например, домен верхнего уровня) для специфического типа кодирования (например, .соm для BIG5). Как показано на фиг. 5, таблица отображения 501 состоит из шести отдельных полей. Первое из них - время жизни, определяющее длительность периода времени до устаревания записи в кэш-памяти. Затем следует поле минимальной строки преобразования кода, идентифицирующей цифровую последовательность части имени домена (например, цифровое кодирование для .соm в BIG5). Следует обратить внимание на то, что минимальная строка преобразования кода, как правило, представляется в виде восьмибитовой двоичной строки. Для упрощения ввода и поддержки минимальных строк преобразования кода в таблице 501 преобразование может осуществляться применительно к двоичным строкам, обеспечивающим возможность достижения представленной формы. Несмотря на то, что минимальная строка преобразования кода может во многих случаях представлять собой домен верхнего уровня, это условие не является обязательным. С целью однозначного преобразования типа лингвистического кодирования, заданного в строке вследствие неоднозначности, для некоторых типов кодирования может потребоваться включение домена второго или более высокого уровня. Аналогично этому, для однозначного определения типа кодирования не всегда необходимо использование целого домена верхнего уровня. Это ускоряет поиск совпадения."Полномочия", определенные в таблице,представляют собой полномочия, данные объекту, по всем именам доменов, определенным в записи. Эти полномочия позволяют осуществлять регистрацию поддоменов под своими полномочиями. Например, если объекту "i-dns" даны полномочия по всему .соm на BIG5, то он может иметь полномочия именовать все поддомены с использованием .соm на BIG5. Это гарантирует назначение исключительно уникальных имен доменов. Кроме того, полномочия обозначают объект, имеющий власть над сервером (или серверами) имен с "надежными" записями, которые обеспечивают IP-адреса для имен доменов в части полномочий пространства DNS. Поле "кодирования" в таблице 501 определяет тип кодирования имени домена, совпадающий с записью. Поле "преобразования" определяет конечный тип кодирования имени домена. На 002513 22 пример, UTF-5 - алгоритм Дюрста в применении к уникоду (описываемому ниже). Наконец, поле "комментариев" содержит строку текста, идентифицирующую часть имени домена, соответствующую минимальной строке преобразования кода. Фиг. 6 иллюстрирует типичное дерево имен доменов для преобразования имен доменов на китайском языке. СерверiDNS, распознающий тип кодирования на китайском языке, конфигурируют заданными по умолчанию серверами имен для преобразования имени домена. Как показано на фиг. 6, под корнем находится множество доменов верхнего уровня (например, .com, .edu, .sg и т.д.). Под доменом верхнего уровня .sg имеется множество доменов второго уровня на китайском языке,например edu.sg, а под этим доменом - множество доменов, включая nus.edu.sg и так далее. Точно так же под доменом верхнего уровня.соm имеется множество поддоменов второго уровня на китайском языке, напримерemail.com. Как отмечено при обсуждении примера осуществления, иллюстрируемого фиг. 3 А, система iDNS преобразовывает универсальный тип кодирования (например, уникод) имени домена в тип кодирования DNS. В одном из предпочтительных примеров осуществления эта операция выполняется с помощью алгоритма преобразования, определенного Мартином Дюрстом в соответствии с проектом Internet "Интернационализация имен доменов", предварительно включенным в виде ссылки. Алгоритм преобразует информационный объект переменной длины в форму, содержащую исключительно алфавиты ASCII одного регистра, соответствующиеRFC, и числа. Предлагаемая ниже таблица представляет собой таблицу преобразования, используемую в проекте Internet. Величина полубайта Шестнадцати Двоичного Начальный Первые два столбца таблицы следует интерпретировать в качестве двоичных (или шестнадцатиричных) величин, а последние два столбца - в качестве символов ASCII, соответст 23 вующих RFC 1035. "Начальный" и "последующий" означает соответственно начальный полубайт (половину байта) информационного объекта и остаток информационного объекта. Если длина информационного объекта составляет 2 байта (как в случае UCS-2), то этот специфический информационный объект будет иметь величину в 4 полубайта. Как указано в рассмотренном выше обсуждении, для преобразования многоязычного имени домена приложение клиента предъявляет многоязычный запрос, не соответствующийRFC, на рассмотрение уполномоченному серверу iDNS. Используя этот алгоритм преобразования, уполномоченный сервер далее преобразует запрос в формат, соответствующий RFC, и предъявляет полученный запрос на рассмотрение серверу DNS. В результате в сервере DNS появится запись для запроса, соответствующего RFC, который отображается в виде правильного IP-адреса,например: в виде 12.34.56.78 Далее сервер DNS возвращает этот IPадрес в соответствии с RFC 1035 на уполномоченный сервер iDNS. Этот уполномоченный сервер передает сообщение, содержащее правильно преобразованный IP-адрес, клиенту. Следует обратить внимание на то, что преобразованное имя домена (в ASCII) обычно должно быть зарегистрировано с полномочиями, несущими ответственность за управление и назначение имен доменов обычной DNS. Примеры осуществления настоящего изобретения касаются устройства для выполнения описанных выше операций iDNS. Это устройство может быть специально созданным (разработанным) для требуемых целей или универсальным компьютером, избирательно активизированным или реконфигурированным компьютерной программой, хранимой в компьютере. Процессы, представленные здесь, неотъемлемо не связаны с каким бы то ни было специфическим компьютером или другим устройством. В частности, могут быть использованы различные универсальные машины в сочетании с программами, написанными в соответствии с возможностями их обучения, или более удобным для выполнения требуемых этапов способа может стать создание более специализированного устройства. Требуемая структура для ряда этих машин выявляется из описания, приведенного выше. В дополнение, примеры осуществления настоящего изобретения далее касаются машиночитаемых средств, которые включают в свой состав команды программы для выполнения различных операций, выполняемых на компьютере. Средства могут быть также комбинированы с командами программ, файлами данных,структурами данных, таблицами и т.п. Средства 24 и команды программы могут быть специально разработаны и созданы в целях реализации настоящего изобретения или хорошо известны и доступны специалистам в области программного обеспечения. Примеры машиночитаемых средств включают в свой состав магнитные средства типа жестких и гибких дисков и магнитной ленты; оптические средства типа дисковCD-ROM; магнитооптические средства типа флоптических дисков; и аппаратные устройства,специально конфигурированные с целью хранения и выполнения команд программ, например постоянные запоминающие устройства (ПЗУ) и устройства оперативной памяти (ЗУПВ). Средства могут представлять собой также среды для передачи данных типа оптических или металлических проводов, волноводов и т.д., включая несущую, передающую сигналы, определяющие команды программ, структуры данных, и т.д. Примеры команд программ включают в свой состав как машинный код, например вырабатываемый компилятором, так и файлы, содержащие код более высокого уровня, который может быть выполнен компьютером с помощью интерпретатора. Фиг. 7 иллюстрирует типичную компьютерную систему в соответствии с примером осуществления настоящего изобретения. Компьютерная система 700 включает в свой состав некоторое число процессоров 702 (называемых также центральными процессорами или ЦП),которые соединены с запоминающими устройствами - с первичной памятью 706 (как правило,оперативной памятью или "ЗУПВ") и первичной памятью 704 (как правило, постоянным запоминающим устройством или "ПЗУ"). Как известно,в данной области техники первичная память 704 обеспечивает передачу данных и команд в одном направлении в ЦП, а первичная память 706 используется обычно для передачи данных и команд в двух направлениях. Оба эти устройства первичной памяти могут содержать любой подходящий тип машиночитаемого средства из числа указанных выше. С ЦП 702 с обеспечением двунаправленной передачи соединено и устройство памяти большой емкости 708, которое обеспечивает дополнительную емкость хранения данных и может включать в свой состав любое из машиночитаемых средств, описанных выше. Устройство памяти большой емкости 708 может быть использовано для хранения, например, программ и данных и, как правило, представляет собой вторичный носитель данных типа жесткого диска, обладающего более низким быстродействием, чем первичная память. Следует высоко оценить возможность включения информации, сохраненной в устройстве памяти большой емкости 708, в качестве части первичной памяти 706 как виртуальной памяти, осуществляемого стандартным способом в соответствующих случаях. Конкретное устройство памяти большой емкости типа CD-ROM 714 может 25 также осуществлять передачу данных в одном направлении в ЦП. ЦП 702, кроме того, соединен с интерфейсом 710, который включает в свой состав одно или несколько устройств ввода-вывода типа видеомониторов, трекболов, мышей, клавиатур,микрофонов, сенсорных дисплеев, устройств считывания с карты преобразователя, устройств считывания с магнитной или бумажной ленты,графических планшетов, перьевых координатно-указательных устройств, устройств распознавания речи или рукописных документов или другие известные устройства ввода данных, например другие компьютеры. Наконец, ЦП 702 может быть выборочно соединен с компьютером или сетью передачи данных с использованием сетевого подключения, как в общем показано на этапе 712. С таким сетевым подключением можно ожидать возможности приема центральным процессором информации от сети или вывода информации в сеть в ходе выполнения описанных выше этапов реализации способа. Описанные выше устройства и материалы являются известными специалистам в области компьютерных аппаратных и программных средств. Аппаратные элементы, описанные выше,могут быть подвергнуты конфигурированию(обычно временному), обеспечивающему возможность образования одного или нескольких программных модулей для выполнения операций по реализации рассматриваемого изобретения. Например, команды для распознавания типа кодирования, преобразования этого типа кодирования и идентификации заданного по умолчанию сервера имен могут храниться в устройстве памяти большой емкости 708 или 714 и выполняться центральным процессором 708 во взаимодействии с первичной памятью 706. В целях достижения ясности в понимании существа предлагаемого изобретения выше было приведено его подробное описание. Очевидно, что в рассмотренное изобретение могут быть внесены определенные изменения и дополнения, не выходящие за пределы объема, определяемого прилагаемой формулой. ФОРМУЛА ИЗОБРЕТЕНИЯ 1. Способ, реализуемый на устройстве распознавания типа лингвистического кодирования имени домена в цифровом представлении, отличающийся тем, что содержит этапы приема цифровой последовательности заданной части имени домена в цифровом представлении; сопоставления указанной цифровой последовательности в составе имени домена с известной цифровой последовательностью в составе совокупности известных цифровых последовательностей, каждая из которых соответствует 26 специфическому типу лингвистического кодирования, причем совокупность включает в свой состав известные цифровые последовательности, по меньшей мере, для двух различных типов лингвистического кодирования; и идентификации типа кодирования, соответствующего известной цифровой последовательности, совпадающей с цифровой последовательностью в составе имени домена. 2. Способ по п.1, отличающийся тем, что содержит также этап приема запроса к DNS,содержащего имя домена в цифровом представлении. 3. Способ по п.1 или 2, отличающийся тем,что заданная часть имени домена в цифровом представлении является минимальной строкой преобразования кода в имени домена. 4. Способ по пп.1, 2 или 3, отличающийся тем, что содержит также этап преобразования формата цифровой последовательности имени домена в цифровом представлении, осуществляемый до этапа сопоставления этой цифровой последовательности. 5. Способ по любому из пп.1-4, отличающийся тем, что совокупность известных цифровых последовательностей представлена в виде таблицы, содержащей записи с атрибутами,включающими известные цифровые последовательности и типы кодирования. 6. Способ по п.5, отличающийся тем, что таблица включает в свой состав записи, имеющие, по меньшей мере, следующие типы кодирования: ASCII, BIG5, GB2312, Shift-JIS, EUCJP, KSC5601 и расширенный ASCII. 7. Способ по п.5, отличающийся тем, что этап идентификации типа кодирования содержит этап идентификации типа кодирования записи, имеющей цифровую последовательность,совпадающую с известной цифровой последовательностью. 8. Способ по любому из пп.1-7, отличающийся тем, что, по меньшей мере, две известные цифровые последовательности совпадают с цифровой последовательностью в составе имени домена и тем, что содержит также этапы приема цифровой последовательности второй части имени домена в цифровом представлении; и сопоставления цифровой последовательности второй части с известной цифровой последовательностью в составе совокупности известных цифровых последовательностей. 9. Способ по п.2, отличающийся тем, что содержит также этапы идентификации сервера DNS корневого уровня, ответственного за преобразование доменов корневого уровня с идентифицированным типом кодирования; и передачи запроса к DNS в сервер DNS корневого уровня. 10. Способ по п.9, отличающийся тем, что содержит также этап преобразования цифровой 27 последовательности имени домена из идентифицированного типа кодирования в тип кодирования DNS, совместимый с протоколом DNS,осуществляемый до этапа передачи запроса кDNS. 11. Способ по п.10, отличающийся тем, что тип кодирования DNS представляет собой ASCII или является универсальным типом лингвистического кодирования. 12. Способ по п.10, отличающийся тем, что этап преобразования цифровой последовательности имени домена содержит этапы преобразования цифровой последовательности имени домена из идентифицированного типа кодирования в универсальный тип лингвистического кодирования; и преобразования цифровой последовательности имени домена из универсального типа лингвистического кодирования в тип кодирования DNS, совместимый с протоколом DNS. 13. Компьютерный программный продукт,содержащий машиночитаемый носитель, на котором зарегистрированы команды программы для реализации способа распознавания типа лингвистического кодирования имени домена в цифровом представлении, отличающийся тем,что способ содержит этапы приема цифровой последовательности заданной части имени домена в цифровом представлении; сопоставления указанной цифровой последовательности в составе имени домена с известной цифровой последовательностью в составе совокупности известных цифровых последовательностей, каждая из которых соответствует специфическому типу лингвистического кодирования, и совокупности, включающей известные цифровые последовательности, по меньшей мере, для двух различных типов лингвистического кодирования; и идентификации типа кодирования, соответствующего известной цифровой последовательности, совпадающей с цифровой последовательностью в составе имени домена. 14. Компьютерный программный продукт по п.13, отличающийся тем, что совокупность известных цифровых последовательностей представлена в виде таблицы, содержащей записи с атрибутами, включающими известные цифровые последовательности и типы кодирования. 15. Компьютерный программный продукт по п.13 или 14, отличающийся тем, что содержит также команды программы для реализации следующих этапов: приема запроса к DNS, содержащего имя домена в цифровом представлении; идентификации сервера DNS корневого уровня, ответственного за преобразование доменов корневого уровня с идентифицированным типом кодирования; и 28 передачи запроса к DNS в сервер DNS корневого уровня. 16. Компьютерный программный продукт по п.15, отличающийся тем, что содержит также команды программы для реализации следующего этапа: преобразования цифровой последовательности имени домена из идентифицированного типа кодирования в тип кодирования DNS, совместимый с протоколом DNS, осуществляемого до этапа передачи запроса к DNS. 17. Таблица отображения типа лингвистического кодирования на машиночитаемом носителе, устанавливающая соответствие специфических типов лингвистического кодирования специфическим цифровым последовательностям, отличающаяся тем, что включает в свой состав множество записей, содержащих известную цифровую последовательность заданной части имени домена в цифровом представлении; и тип лингвистического кодирования, соответствующий известной цифровой последовательности. 18. Таблица отображения по п.17, отличающаяся тем, что заданная часть имени домена в цифровом представлении является цифровой последовательностью домена верхнего уровня в имени домена. 19. Таблица отображения по п.17 или 18,отличающаяся тем, что записи таблицы отображения включают в свой состав, по меньшей мере, следующие типы лингвистического кодирования: ASCII, BIG5, GB2312, Shift-JIS, EUC-JP,KSC5601 и расширенный ASCII. 20. Таблица отображения по пп.17, 18 или 19, отличающаяся тем, что записи содержат также сервер DNS верхнего уровня, ответственный за преобразование доменов корневого уровня с типом лингвистического кодирования,представленным в записи. 21. Таблица отображения по любому из пп.17-20, отличающаяся тем, что записи содержат также поле преобразования, предназначенное для преобразования типа кодирования в тип кодирования, совместимый с DNS. 22. Таблица отображения по любому из пп.17-21, отличающаяся тем, что записи содержат также поле времени жизни. 23. Таблица отображения по п.22, отличающаяся тем, что тип кодирования DNS является ASCII или универсальным типом лингвистического кодирования. 24. Устройство, отличающееся тем, что содержит один или несколько процессоров; память, соединенную, по меньшей мере, с одним из процессоров; и один или несколько сетевых интерфейсов,обеспечивающих возможность приема первого запроса к DNS, включающего имя домена в типе кодирования не-DNS, и передачи запроса к DNSDNS, совместимый с протоколом DNS, причем,по меньшей мере, один из процессоров разработан или конфигурирован для преобразования имени домена с типом кодирования не-DNS в имя этого домена с типом кодирования DNS. 25. Устройство по п.24, отличающееся тем,что один или несколько сетевых интерфейсов соединены с сетью так, что обеспечивают устройству возможность осуществлять прием запросов клиентов к DNS, причем запросы клиентов к DNS представляют собой имя домена с типом кодирования не-DNS. 26. Устройство по п.24 или 25, отличающееся тем, что один или несколько сетевых интерфейсов соединены с сетью так, что обеспечивают устройству возможность осуществлять передачу запроса к DNS в стандартный серверDNS, причем запрос к DNS представляет собой имя домена с типом кодирования DNS. 27. Устройство по пп.24, 25 или 26, отличающееся тем, что содержит также таблицу отображения, постоянно находящуюся, по меньшей мере частично, в памяти, причем таблица отображения сопоставляет специфические типы лингвистического кодирования со специфическими цифровыми последовательностями,которые предполагается найти в именах доменов, закодированных в цифровой форме. 28. Устройство по любому из пп.24-27, отличающееся тем, что, по меньшей мере, один процессор конфигурирован или разработан для идентификации типа кодирования имени домена не-DNS, осуществляемой до преобразования этого имени домена из типа кодирования неDNS в тип кодирования DNS.
МПК / Метки
МПК: G06F 17/20
Метки: многоязыковая, наименования, служба, доменов
Код ссылки
<a href="https://eas.patents.su/17-2513-mnogoyazykovaya-sluzhba-naimenovaniya-domenov.html" rel="bookmark" title="База патентов Евразийского Союза">Многоязыковая служба наименования доменов</a>
Предыдущий патент: Блокада cd154 как лечение синдрома ингибирования терапевтических белков
Следующий патент: Система и способ проведения аукциона через компьютерную сеть
Случайный патент: Способ повышения эффективности генного переноса в клетки-мишени с помощью ретровируса