Способ и устройство для уменьшения влияния ошибок передачи в распределенной системе и в распределенном процессе распознавания речи







Формула / Реферат
1. Способ уменьшения влияния ошибок передачи в распределенном процессе распознавания речи, заключающийся в том, что в распределенном процессе распознавания речи параметры распознавания речи в первом местоположении конфигурируют в векторы, соответствующие дискретизируемым временным кадрам, и эти параметры, переданные из первого местоположения, принимают во втором местоположении для обработки декодером распознавания речи, отличающийся тем, что идентифицируют группу, содержащую один или несколько упомянутых векторов, подвергшихся ошибке передачи, и обрабатывают данные, предназначенные для передачи на декодер распознавания речи, для гарантии того, что по меньшей мере один параметр распознавания речи в идентифицированной группе исключен из окончательной обработки.
2. Способ по п.1, отличающийся тем, что все параметры распознавания речи каждого вектора упомянутой группы исключают из окончательной обработки.
3. Способ по п.1 или 2, отличающийся тем, что при обработке данных, предназначенных для передачи на декодер распознавания речи, заменяют упомянутый по меньшей мере один параметр распознавания речи данными, выбранными таким образом, что их отбраковывают декодером распознавания речи как аномальные.
4. Способ по п.3, отличающийся тем, что выбранные данные содержат один или несколько параметров распознавания речи, имеющих значение, значительно отличающееся от любого значения, которое возникает в естественной речи.
5. Способ по п.3 или 4, отличающийся тем, что параметры распознавания речи квантуют перед передачей и восстанавливают после передачи, при этом квантование ограничивает диапазон возможных значений, которые могут принимать параметры при восстановлении, и упомянутые выбранные данные содержат одно или несколько значений, находящихся вне упомянутого диапазона.
6. Способ по п.5, отличающийся тем, что используют способ разделенного векторного квантования, в котором каждый квантователь выполняет операции на паре параметров распознавания речи, и выбирают упомянутые выбранные данные, содержащие одно или несколько значений, удаленных от каждого центроида квантователя, по меньшей мере, на заданную величину.
7. Способ по любому из пп.3-6, отличающийся тем, что при окончательной обработке осуществляют подстановку значения, предусмотренного по умолчанию, для оценки, формируемой при обработке выбранных аномальных данных.
8. Устройство для уменьшения влияния ошибок передачи в распределенном процессе распознавания речи, причем в распределенном процессе распознавания речи параметры распознавания речи в первом местоположении конфигурируются в векторы, соответствующие дискретизируемым временным кадрам, и эти параметры, переданные из первого местоположения, принимаются во втором местоположении для обработки декодером распознавания речи, отличающееся тем, что содержит средство идентификации для идентификации группы, содержащей один или несколько упомянутых векторов, которые подверглись ошибке передачи, и средство обработки данных для обработки данных, предназначенных для передачи декодеру распознавания речи, для гарантии того, что по меньшей мере один параметр распознавания речи в идентифицированной группе исключен из окончательной обработки.
9. Устройство по п.8, отличающееся тем, что средство обработки данных выполнено с возможностью исключения из окончательной обработки всех параметров распознавания речи каждого вектора из упомянутой группы.
10. Устройство по п.8 или 9, отличающееся тем, что средство обработки выполнено с возможностью замены упомянутого по меньшей мере одного параметра распознавания речи данными, выбранными таким образом, что они отбраковываются декодером распознавания речи, как аномальные.
11. Устройство по п.10, отличающееся тем, что выбранные данные содержат один или несколько параметров распознавания значения, которое может возникнуть в естественной речи.
12. Устройство по п.10 или 11, отличающееся тем, что содержит средство для квантования параметров распознавания речи до передачи и средство для восстановления параметров после передачи, при этом квантование ограничивает диапазон возможных значений, которые могут принимать параметры при восстановлении, а упомянутые выбранные данные содержат одно или несколько значений, находящихся вне упомянутого диапазона.
13. Устройство по п.12, отличающееся тем, что средство квантования выполнено с возможностью осуществления разделенного векторного квантования, при которомкаждый квантователь выполняет операции над парой параметров распознавания речи, а упомянутые выбранные данные содержат одно или несколько значений, удаленных от каждого центроида квантователя, по меньшей мере, на заданную величину.
14. Устройство по любому из пп.8-13, отличающееся тем, что декодер окончательной обработки содержит средство для подстановки значения, предусмотренного по умолчанию, для оценки, сформированной при обработке выбранных аномальных данных.

Текст
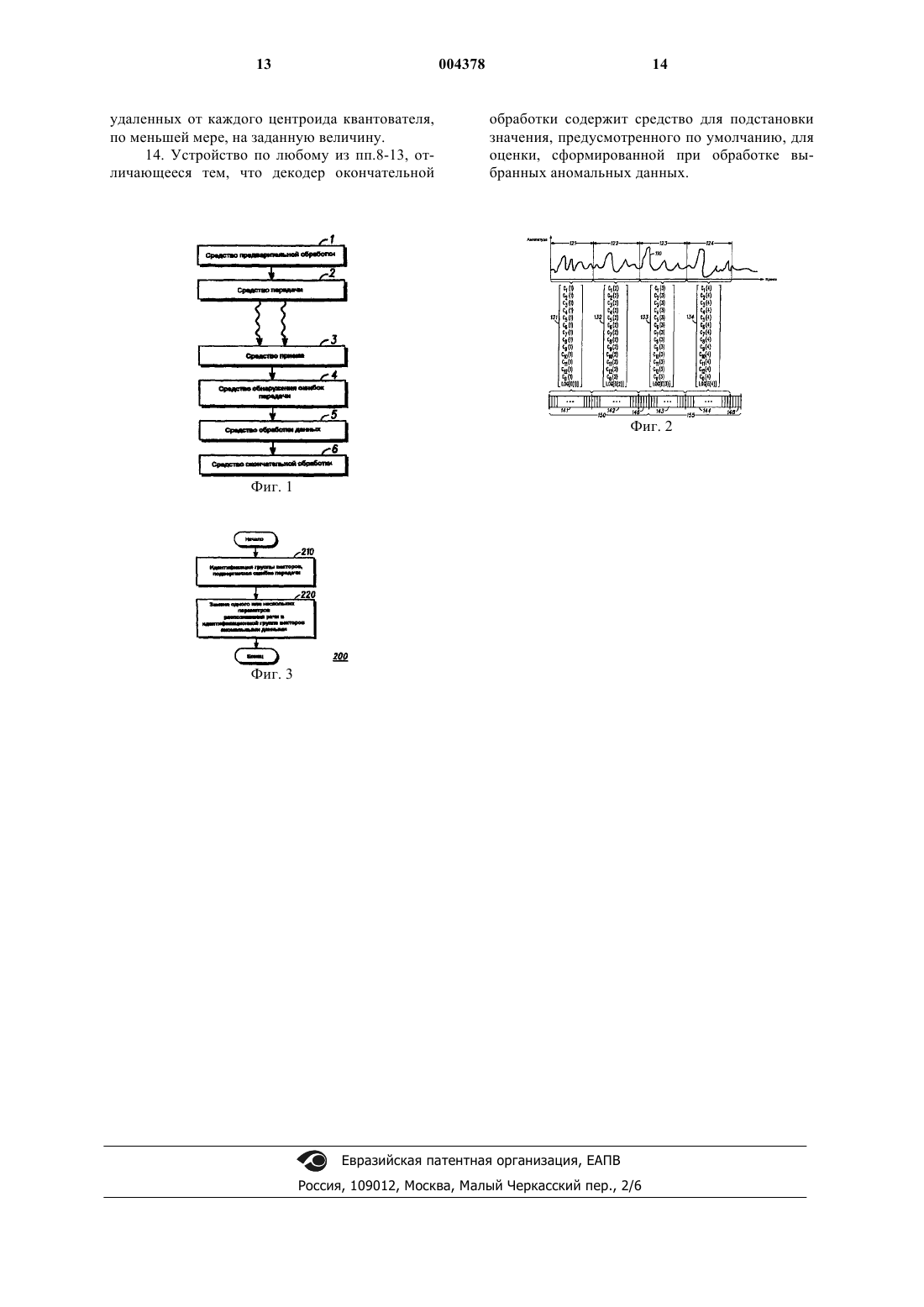
1 Область техники, к которой относится изобретение Настоящее изобретение относится к способу уменьшения влияния ошибок передачи в распределенной системе распознавания речи. Настоящее изобретение относится также к устройству для уменьшения влияния ошибок передачи в распределенной системе распознавания речи. Настоящее изобретение применяется для уменьшения влияния ошибок передачи, воздействующих на параметры распознавания речи при передаче этих параметров через линию радиосвязи, и т.д., но не ограничивается этим. Уровень техники Распознавание речи является процессом,используемым для автоматического распознавания звуков, частей слов, слов или фраз речи. Такой процесс может использоваться в качестве интерфейса между человеком и машиной (автоматом) дополнительно к использованию более распространенных инструментов, например,переключателей, клавиатур, мыши и т.д. или вместо них. Процесс распознавания речи может также использоваться для автоматической выборки информации из некоторых передаваемых речевых данных или сообщения. Для обеспечения автоматического распознавания речи были разработаны разные способы, которые продолжают совершенствоваться. Некоторые из них основаны на расширенных знаниях с соответствующими эвристическими стратегиями, другие используют статистические модели. В стандартном процессе распознавания речи обрабатываемая речь дисктеризируется несколько раз в течение длительности дискретизируемого временного кадра. В стандартном процессе речь может дискретизироваться с частотой в диапазоне 8 - 20 кГц и может иметь место порядка 50 - 100 дискретизируемых кадров в секунду. Дискретизированные значения обрабатываются с использованием алгоритмов для обеспечения параметров распознавания речи. Например, одним видом параметра распознавания речи является коэффициент, известный как кепстральный коэффициент мелодичности звука. Такие параметры распознавания речи конфигурируются в виде векторов, также известных как массивы, которые могут рассматриваться как группы или наборы параметров, сконфигурированных в некотором порядке. Процесс дискретизации повторяется для других дискретизируемых временных кадров. Согласно стандартному формату образуется один вектор для каждого дискретизируемого временного кадра. Параметризация и формирование в векторы, упомянутые выше, составляют операцию,которая может быть определена, как операция предварительной обработки процесса распознавания речи. Описанные выше параметры распознавания речи, сконфигурированные в векторы,затем анализируются согласно способам распо 004378 2 знавания речи при операции, которая может быть определена, как операция окончательной обработки процесса распознавания речи. В процессе распознавания речи, в котором процесс предварительной обработки и процесс окончательной обработки выполняются в одном местоположении, или в одном устройстве, вероятность ошибок, возникающих в параметрах распознавания речи в процессе от предварительной обработки к окончательной обработке, является минимальной. Однако в процессе, известном как распределенный процесс распознавания речи, часть предварительной обработки процесса распознавания речи выполняется на удалении от части окончательной обработки. В первом местоположении речь дискретизируется, параметризуется, и параметры распознавания речи конфигурируются в векторы. Параметры распознавания речи квантуются и затем передаются, например,по линии связи установленной системы связи во второе местоположение. Часто первое местоположение является удаленным терминалом, а второе местоположение - центральной станцией обработки данных. Затем во втором местоположении принятые параметры распознавания речи анализируются в соответствии со способами распознавания речи. Для использования в распределенном процессе распознавания речи могут рассматриваться многие виды линий связи различных систем связи. Одним возможным вариантом является стандартная беспроводная система связи, например, коммутируемая телефонная сеть общего пользования. Другим возможным вариантом является система радио связи, например, Общеевропейская система транковой связи (ОСТ,TETRA). Еще одним возможным вариантом является система сотовой радиосвязи. Возможным вариантом применимой системы сотовой связи является Глобальная система мобильной связи (ГСМ, GSM), другим возможным вариантом являются системы, находящиеся в процессе стандартизации, например, универсальная система мобильной электросвязи (УСМЭ, VMTS). Использование любой линии связи в любой сети связи приводит к возможности возникновения ошибок в параметрах распознавания речи при передаче этих параметров из первого местоположения во второе местоположение по линии связи. В системах связи известны способы обнаружения ошибок, которые обнаруживают наличие ошибки в данной части передаваемой информации. Хорошо известен способ кодирования с использованием циклического избыточного кода. В зависимости от характера передаваемой информации при обнаружении наличия ошибки применяются разные способы уменьшения влияния ошибок. В распределенном процессе распознавания речи для уменьшения влияния 3 ошибок передачи не всегда подходят способы уменьшения влияния ошибок, возникающих при передаче информации в другой форме. Причиной этого являются специализированные способы распознавания речи, которыми обрабатываются параметры, следовательно, требуется создание средства для уменьшения влияния ошибок передачи в распределенном процессе распознавания речи. Опубликована патентная заявка Великобритании GB-A-2343777, которая касается уменьшения ошибок в распределенной системе распознавания речи. Известный способ идентифицирует группу, содержащую один или несколько векторов, которые подверглись ошибке передачи. В одном варианте осуществления все вектора заменяются копией предшествующих,или последующих безошибочных векторов, самых близких в порядке приема к заменяемому вектору. Сущность изобретения Настоящее изобретение предлагает средство для уменьшения влияния ошибок передачи в распределенном процессе распознавания речи. Согласно одному аспекту настоящего изобретения предложен способ уменьшения влияния ошибок передачи в распределенной системе распознавания речи, как заявлено в п.1 формулы изобретения. Согласно другому аспекту настоящего изобретения предложено устройство для уменьшения влияния ошибок передачи в распределенной системе распознавания речи, как заявлено в п.8 формулы изобретения. В некоторых вариантах осуществления данные, предназначенные для передачи на декодер окончательной обработки, обрабатываются путем замены по меньшей мере одного параметра распознавания речи, идентифицированного, как подвергшегося ошибке, данными, выбранными таким образом, что они отбраковываются декодером распознавания речи, как аномальные. Такие варианты осуществления предлагают средство для уменьшения влияния ошибок передачи, основанное на функционировании декодера распознавания речи окончательной обработки, не требующее изменения кода окончательной обработки. Альтернативный способ уменьшения влияния ошибок передачи в распределенном процессе распознавания речи состоит в обнаружении ошибок в принятых параметрах и при обнаружении ошибки сигнализации декодеру распознавания речи, используемому при окончательной обработке (декодеру распознавания речи окончательной обработки). Однако при этом потребуется выполнение окончательной обработки с возможностью осуществления действий при этих сигналах. Практически это приведет к необходимости изменения кода окончательной обработки. 4 Дополнительные аспекты изобретения заявлены в зависимых пунктах формулы изобретения. Настоящее изобретение уменьшает влияние ошибок передачи в распределенном процессе распознавания речи. Дополнительные конкретные преимущества станут очевидны из последующего описания и чертежей. Краткое описание чертежей Фиг. 1 схематично изображает устройство для распределенного распознавания речи согласно изобретению. Фиг. 2 схематично изображает используемые в распределенном процессе распознавания речи параметры распознавания речи, сконфигурированные в векторы, соответствующие дискретизируемым временным кадрам. Фиг. 3 изображает блок-схему варианта осуществления настоящего изобретения. Подробное описание вариантов осуществления изобретения На фиг. 1 схематично изображено устройство для распределенного распознавания речи,используемое в варианте осуществления настоящего изобретения. Как описано ниже со ссылкой на фиг. 2, устройство в целом содержит средство 1 предварительной обработки для формирования параметров распознавания речи на основе дискретизированного сигнала речи. Выход средства 1 предварительной обработки соединен со средством передачи, выполненным с возможностью выполнения операций над параметрами распознавания речи и передачи этих параметров вместе с другой необходимой информацией по линии связи к удаленному местоположению. Как упомянуто при описании предшествующего уровня техники, могут быть использованы многие виды линий связи, но предусматривается, что настоящее изобретение должно использоваться, конкретно, в системах мобильной связи. В удаленном местоположении сигналы,переданные по сети связи, принимаются средством 3 приема, выполненным с возможностью передачи переданных данных дальше в средство 4 обнаружения ошибок передачи, выполненное с возможностью идентификации любых параметров распознавания речи, подвергшихся ошибкам передачи при передаче по сети связи. Средство 4 обнаружения ошибок передачи соединено со средством 5 обработки данных, выполненным с возможностью замены данных,соответствующих параметрам распознавания речи, идентифицированным, как подвергшиеся ошибке передачи. Средство 5 обработки данных соединено со средством 6 окончательной обработки, которое содержит декодер, выполненный с возможностью осуществления операций над принятыми параметрами распознавания речи,для завершения распределенного процесса распознавания речи. 5 Ниже более подробно рассмотрен распределенный процесс распознавания речи. Согласно фиг. 2 в распределенном процессе распознавания речи, в котором используется вариант осуществления настоящего изобретения, параметры распознавания речи конфигурируются в векторы, соответствующие дискретизируемым временным кадрам. На фиг. 2 изображена обрабатываемая часть сигнала 110 речи. Сигнал 110 речи изображен в упрощенной форме, поскольку на практике он будет состоять из намного более сложной последовательности дискретных значений. Дискретизируемые временные кадры, из которых на фиг. 2 изображены первый дискретизируемый временной кадр 121, второй дискретизируемый временной кадр 122, третий дискретизируемый временной кадр 123 и четвертый дискретизируемый временной кадр 124,накладываются на сигнал речи, как изображено на фиг. 2. В варианте осуществления, который описан ниже, имеет место 100 дискретизируемых временных кадров в секунду. Сигнал речи дискретизируется неоднократно в течение длительности каждого дискретизируемого временного кадра. В варианте осуществления, который описан ниже, в процессе распознавания речи используется всего четырнадцать параметров распознавания речи. Первые двенадцать параметров являются первыми двенадцатью статическими кепстральными коэффициентами мелодичности звука, т.е. с(m) = [c1(m), c2(m) с 12(m)]T,где m обозначает номер дискретизируемого временного кадра. Тринадцатый используемый параметр распознавания речи является нулевым кепстральным коэффициентом, т.е. c0(m). Четырнадцатый используемый параметр распознавания речи является логарифмической энергетической составляющей, т.е. log[E(m)]. Эти коэффициенты и подробности их использования в процессе распознавания речи известны в данной области технике и не требуют дополнительного описания. Более того, было отмечено, что изобретение может быть выполнено с использованием других комбинаций кепстральных коэффициентов, формирующих параметры распознавания речи, а также с другими наборами или схемами параметров распознавания речи, отличными от кепстральных коэффициентов. Четырнадцать параметров для каждого дискретизируемого временного кадра конфигурируются, или форматируются, в соответствующий вектор, также известной как массив,который изображен на фиг. 2. Вектор 131 соответствует дискретизируемому временному кадру 121, вектор 132 соответствует дискретизируемому временному кадру 122, вектор 133 соответствует дискретизируемому временному кадру 123 и вектор 134 соответствует дискрети 004378 6 зируемому временному кадру 124. Такой вектор, в общем, может выть представлен в виде: Перед передачей из первого местоположения во второе местоположение параметры распознавания речи обрабатываются. В описанном ниже варианте осуществления обработка осуществляется следующим образом. Параметры из вектора 131 квантуются. Квантование осуществляется путем прямого квантования вектора разделенным векторным квантователем. Коэффициенты группируются попарно, и каждая пара квантуется с использованием кодовой книги для векторного квантования (ВК), заданной для этой соответствующей пары. Результирующий набор значений индексов затем используется для представления кадра речи. Пары коэффициентов показаны в виде предварительных параметров в табл. 1 вместе с размером кодовой книги, используемых для каждой пары. Таблица 1. Парные характеристики разделенного векторного квантования Кодовая Размер Весовая матрица Элемент 1 Элемент 2 книга Для определения индекса путем использования взвешенного евклидова кодового расстояния находится ближайший ВК центроид. где qji,i+1 обозначает j-ый кодовый вектор в кодовой книге Qi,i+1, Ni,i+1 является размером кодовой книги, Wi,i+1 является (возможно, идентичной) весовой матрицей, используемой для кодовой книги Qi,i+1, a idxi,i+1(m) обозначает индекс из кодовой книги, выбранный для представления вектора [yi(m), yi+1(m)]T. Образованные индексы затем представляются в виде 44 битов. Эти 44 бита размещаются в первых 44 слотах (временных интервалах) кадра 150 потока битов, обозначенных на фиг. 2 ссылочной позицией 141. Соответствующие 44 бита, образованные для следующего вектора,вектора 132, размещаются в следующих 44 слотах кадра 150 потока битов, обозначенных на фиг. 2 ссылочной позицией 142. Остальные биты кадра 150 потока битов состоят из 4 битов циклического избыточного кода, обозначенных на фиг. 2 ссылочной позицией 146, значение 7 битов определяется так, чтобы известным способом обеспечить обнаружение ошибки для всех 88 предыдущих битов кадра 150 потока битов. Аналогично, 44 бита, полученных из вектора 133, размещаются в первых 44 слотах второго кадра 155 потока битов, обозначенных на фиг. 2 ссылочной позицией 143. Также, соответствующие 44 бита, образованные для следующего вектора, вектора 134, размещаются в следующих 44 слотах кадра 155 потока битов, обозначенных на фиг. 2 ссылочной позицией 144. Остальные биты кадра 155 потока битов состоят из 4 битов циклического избыточного кода, обозначенных на фиг. 2 ссылочной позицией 148. Такая конфигурация повторяется для последующих векторов. Описанный выше формат кадров потока битов, в котором битовые данные из двух векторов конфигурируются в один объединенный кадр потока битов, приведен в качестве возможного варианта. Например, альтернативно, данные каждого вектора могут быть сконфигурированы в один кадр потока битов,содержащий биты обнаружения ошибки только для этого вектора. Аналогично, количество слотов на кадр потока битов приведено в качестве возможного варианта. Следует также отметить,что описанный выше способ сжатия векторов приведен в качестве возможного варианта. Следует отметить, что описанные выше кадры потока битов не должны быть приняты за кадры передачи, которые затем используются при передаче данных потока битов по линии связи системы связи, в которой осуществляется передача данных из первого местоположения во второе местоположение, например, временные кадры, используемые при множественном доступе с временным разделением каналов (МДВР) системы сотовой радиосвязи ГСМ, используемой в описанных здесь вариантах осуществления. В рассматриваемом возможном варианте первое местоположение представляет удаленная абонентская станции, а второе местоположение,то есть принимающее местоположение, представляет централизованная станция обработки данных, которая может быть расположена, например, в базовой станции системы сотовой связи. В описываемых вариантах осуществления параметры распознавания речи передаются между первым местоположением и вторым местоположением по линии радиосвязи. Однако очевидно, что сущность первого местоположения и второго местоположения будет зависеть от вида рассматриваемой системы связи и от конфигурации осуществленного в ней распределенного процесса распознавания речи. Во втором местоположении после приема кадры потока битов восстанавливаются из формата, в котором они передаются. Следовательно, выше описан распределенный процесс распознавания речи, в котором параметры распознавания речи конфигурируются в векторы, соответствующие дискретизируе 004378 8 мым временным кадрам, и упомянутые параметры распознавания речи, переданные из первого местоположения, принимаются во втором местоположении. Блок-схема 200 на фиг. 3 иллюстрирует способ уменьшения влияния ошибок передачи в таком процессе распознавания речи, согласно рассматриваемому варианту осуществления. Согласно фиг. 3 функциональный блок 210 иллюстрирует операцию идентификации группы, содержащей один или несколько упомянутых векторов, подвергшихся ошибке передачи. В рассматриваемом варианте осуществления обнаружение ошибки выполняется путем сравнения 4 битов циклического избыточного кода, например, 146, 148 с содержимым соответствующих кадров 150, 155 потока битов, с использованием известных способов циклического избыточного кодирования. В рассматриваемом возможном варианте будет идентифицирован любой кадр потока битов, подвергшийся ошибке передачи. Следовательно, в рассматриваемом возможном варианте идентифицированная группа векторов состоит из двух векторов, являющихся парой векторов из одного кадра потока битов. Если в другом возможном варианте каждый кадр потока битов со средством обнаружения ошибок содержит только один вектор, то идентифицированной группой векторов должен быть один вектор. Очевидно, что конкретная форма и техническое обоснование,определяющие количество векторов в идентифицированной группе, будут зависеть от разных способов, которыми векторы сконфигурированы в потоки битов, и, более того, от используемого способа обнаружения ошибок. Более конкретно,способы обнаружения ошибок, отличные от циклического избыточного кодирования, применяемого в рассматриваемом варианте осуществления, могут предусматривать другие количества векторов в идентифицируемой группе. Также для любой заданной конфигурации потока битов на определение количества векторов в идентифицируемой группе могут оказать влияние второстепенные проектные решения по обработке ошибочной информации. Например,согласно рассматриваемому варианту осуществления, для сохранения мощности обработки может быть принято решение рассматривать только ошибку, содержащуюся в группах кадров потока данных, даже если средство обнаружения ошибок реально может обеспечить обнаружение ошибки более конкретно. Параметры распознавания речи восстанавливаются из кадров потока битов путем выполнения процедуры, обратной описанной выше процедуре векторного квантования. Более конкретно, из потока битов получают индексы и с их использованием восстанавливаются векторы в следующей форме: Функциональный блок 220 иллюстрирует следующую операцию рассматриваемого варианта осуществления, операцию замены одного или нескольких параметров распознавания речи в идентифицированной группе векторов аномальными данными, как описано подробно ниже. В рассматриваемом варианте осуществления разные этапы обработки данных выполняются в таком порядке, чтобы все принятые параметры распознавания речи были восстановлены из кадров потока битов и временно сохранены перед заменой аномальными данными одного или нескольких из этих параметров. Однако следует отметить, что, альтернативно, один или несколько параметров распознавания речи могут быть заменены путем замены соответствующим образом информации потока битов до действительного, реального восстановления параметров распознавания речи, включая вновь введенные замены, из формата потока битов. Для специалистов в данной области техники очевидно, что декодеры распознавания речи,используемые для выполнения окончательной обработки, обычно выполнены таким образом,что при приеме вектора параметров распознавания речи, соответствующего дискретизируемому временному кадру, который дает аномально высокую оценку при его сравнении с эталонами слов декодера, этот кадр (т.е. вектор параметров) отбраковывался декодером. Затем обычный декодер распознавания речи заменит оценку или вероятность, соответствующие этому кадру, на значение, предусмотренное по умолчанию. Стандартные декодеры распознавания речи,используемые при окончательной обработке,обычно обеспечиваются возможностью отбраковки кадров, чтобы решить проблему с кадрами, искаженными шумом. В настоящем изобретении имеющаяся у декодеров распознавания звука окончательной обработки возможность отбраковывать аномальные или не подобные речи кадры используется для уменьшения влияния ошибок передачи. Следовательно, эта система имеет преимущество в том, что исчезает необходимость адаптации декодера распознавания речи окончательной обработки для решения проблемы с ошибками передачи и, следовательно, исчезает потребность в изменении кода окончательной обработки. В то же время исчезает необходимость изменения процесса распознавания речи путем использования более активных способов исправления ошибок, которое оказывает неблагоприятное воздействие на процесс распознавания речи. Как отмечено выше в рассматриваемом варианте осуществления при идентификации, что кадр 150, 155 потока битов подвергся ошибке передачи, становится известным, что один или 10 несколько параметров распознавания речи в каком - либо из двух соответствующих векторов 131, 132, 133, 134 подвергся ошибке передачи. В рассматриваемом варианте осуществления все параметры речи в идентифицированной группе из двух векторов заменяются набором предварительно вычисленных значений, выбранных так, что они сильно отличаются от любых значений, которые могут возникнуть в естественной речи и, следовательно, будут отбракованы декодером окончательной обработки как аномальные. Следовательно, как описано выше,кодер окончательной обработки подставит оценку, заданную по умолчанию, и не возникнет ошибочных данных, влияющих на процесс распознавания речи. В описанном выше процессе векторного квантования векторный квантователь выполняет операции над парами кепстральных параметров. При этом процессе каждый векторный квантователь ограничивает диапазон возможных значений, которые могут быть декодированы для соответствующих пар кепстральных параметров при упомянутом выше процессе восстановления векторов. В рассматриваемом варианте осуществления этот факт используется для выбора аномальных данных. Альтернативные значения для каждого кепстрального параметра определяются, как значения, которые лежат вне допустимого диапазона и превышают некоторое пороговое расстояние от всех центроидов квантователя. Это, в свою очередь, гарантирует, что при приеме кадра, т.е. вектора параметров, содержащего эти альтернативные предварительно вычисленные значения, декодер окончательной обработки будет регистрировать очень высокую оценку и отбраковывать этот кадр, предпочтя оценку, предусмотренную по умолчанию, как упомянуто выше. В рассматриваемом варианте осуществления каждый кадр 150, 155 потока битов содержит два вектора, и способ обнаружения ошибок ассоциирует обнаруженную ошибку передачи с каждым из двух векторов. Следовательно, при определении, что эти кадры 150, 155 подверглись ошибке передачи, осуществляется замена вычисленных альтернативных значений для кепстральных параметров в каждом из двух векторов. Однако, как упомянуто выше, при использовании других способов обнаружения ошибок может потребоваться замена кепстральных параметров в одном векторе или возникнуть необходимость замены параметров в большем количестве векторов. В описанном выше варианте осуществления этапы обработки данных выполняются программируемым устройством цифровой обработки сигналов, например, одним из устройств семейства DSP56xxx (торговая марка) фирмы Моторолла. В качестве альтернативы, может быть использована интегральная схема прикладной ориентации (специальная интегральная схема 11 СИС, ASIC). Также существуют другие возможности. Например, может использоваться интерфейсный блок, осуществляющий взаимодействие между радиоприемником и компьютерной системой, формирующей часть процессора распознавания речи окончательной обработки. ФОРМУЛА ИЗОБРЕТЕНИЯ 1. Способ уменьшения влияния ошибок передачи в распределенном процессе распознавания речи, заключающийся в том, что в распределенном процессе распознавания речи параметры распознавания речи в первом местоположении конфигурируют в векторы, соответствующие дискретизируемым временным кадрам,и эти параметры, переданные из первого местоположения, принимают во втором местоположении для обработки декодером распознавания речи, отличающийся тем, что идентифицируют группу, содержащую один или несколько упомянутых векторов, подвергшихся ошибке передачи, и обрабатывают данные, предназначенные для передачи на декодер распознавания речи,для гарантии того, что по меньшей мере один параметр распознавания речи в идентифицированной группе исключен из окончательной обработки. 2. Способ по п.1, отличающийся тем, что все параметры распознавания речи каждого вектора упомянутой группы исключают из окончательной обработки. 3. Способ по п.1 или 2, отличающийся тем,что при обработке данных, предназначенных для передачи на декодер распознавания речи,заменяют упомянутый по меньшей мере один параметр распознавания речи данными, выбранными таким образом, что их отбраковывают декодером распознавания речи как аномальные. 4. Способ по п.3, отличающийся тем, что выбранные данные содержат один или несколько параметров распознавания речи, имеющих значение, значительно отличающееся от любого значения, которое возникает в естественной речи. 5. Способ по п.3 или 4, отличающийся тем,что параметры распознавания речи квантуют перед передачей и восстанавливают после передачи, при этом квантование ограничивает диапазон возможных значений, которые могут принимать параметры при восстановлении, и упомянутые выбранные данные содержат одно или несколько значений, находящихся вне упомянутого диапазона. 6. Способ по п.5, отличающийся тем, что используют способ разделенного векторного квантования, в котором каждый квантователь выполняет операции на паре параметров распознавания речи, и выбирают упомянутые выбранные данные, содержащие одно или не 004378 12 сколько значений, удаленных от каждого центроида квантователя, по меньшей мере, на заданную величину. 7. Способ по любому из пп.3-6, отличающийся тем, что при окончательной обработке осуществляют подстановку значения, предусмотренного по умолчанию, для оценки, формируемой при обработке выбранных аномальных данных. 8. Устройство для уменьшения влияния ошибок передачи в распределенном процессе распознавания речи, причем в распределенном процессе распознавания речи параметры распознавания речи в первом местоположении конфигурируются в векторы, соответствующие дискретизируемым временным кадрам, и эти параметры, переданные из первого местоположения, принимаются во втором местоположении для обработки декодером распознавания речи, отличающееся тем, что содержит средство идентификации для идентификации группы,содержащей один или несколько упомянутых векторов, которые подверглись ошибке передачи, и средство обработки данных для обработки данных, предназначенных для передачи декодеру распознавания речи, для гарантии того, что по меньшей мере один параметр распознавания речи в идентифицированной группе исключен из окончательной обработки. 9. Устройство по п.8, отличающееся тем,что средство обработки данных выполнено с возможностью исключения из окончательной обработки всех параметров распознавания речи каждого вектора из упомянутой группы. 10. Устройство по п.8 или 9, отличающееся тем, что средство обработки выполнено с возможностью замены упомянутого по меньшей мере одного параметра распознавания речи данными, выбранными таким образом, что они отбраковываются декодером распознавания речи,как аномальные. 11. Устройство по п.10, отличающееся тем,что выбранные данные содержат один или несколько параметров распознавания значения,которое может возникнуть в естественной речи. 12. Устройство по п.10 или 11, отличающееся тем, что содержит средство для квантования параметров распознавания речи до передачи и средство для восстановления параметров после передачи, при этом квантование ограничивает диапазон возможных значений, которые могут принимать параметры при восстановлении, а упомянутые выбранные данные содержат одно или несколько значений, находящихся вне упомянутого диапазона. 13. Устройство по п.12, отличающееся тем,что средство квантования выполнено с возможностью осуществления разделенного векторного квантования, при котором каждый квантователь выполняет операции над парой параметров распознавания речи, а упомянутые выбранные данные содержат одно или несколько значений, 13 удаленных от каждого центроида квантователя,по меньшей мере, на заданную величину. 14. Устройство по любому из пп.8-13, отличающееся тем, что декодер окончательной 14 обработки содержит средство для подстановки значения, предусмотренного по умолчанию, для оценки, сформированной при обработке выбранных аномальных данных.
МПК / Метки
МПК: G10L 15/26
Метки: влияния, речи, системе, распределенной, распределенном, ошибок, уменьшения, распознавания, процессе, способ, устройство, передачи
Код ссылки
<a href="https://eas.patents.su/8-4378-sposob-i-ustrojjstvo-dlya-umensheniya-vliyaniya-oshibok-peredachi-v-raspredelennojj-sisteme-i-v-raspredelennom-processe-raspoznavaniya-rechi.html" rel="bookmark" title="База патентов Евразийского Союза">Способ и устройство для уменьшения влияния ошибок передачи в распределенной системе и в распределенном процессе распознавания речи</a>
Способ и устройство передачи сообщения в мобильной системе связи

Номер патента: 2912
Опубликовано: 31.10.2002
Автор: Иванов Валерий Филиппович
МПК: H04B 7/26
Метки: мобильной, устройство, передачи, способ, сообщения, системе, связи
Формула / Реферат:
1. Способ передачи сообщения в мобильной системе связи, заключающийся в формировании (38) подвижным средством связи (1), например радиотелефоном, кодированного этим сообщением, например, посредством модуляции, электромагнитного излучения, имеющего заданные значения мощности и частоты, отличающийся тем, что формируют (39) подвижным средством связи (1) кодированное сообщением вспомогательное излучение, при этом используют для каждого подвижного...
Система и способ автоматизированной записи речи с использованием двух экземпляров преобразования речи и автоматизированной коррекции

Номер патента: 4352
Опубликовано: 29.04.2004
Авторы: Флинн Томас П., Квин Чарльз, Кан Джонатан
МПК: G10L 15/26
Метки: способ, использованием, преобразования, записи, речи, система, экземпляров, двух, коррекции, автоматизированной
Формула / Реферат:
1. Система для автоматизации услуг по записи речи для одного или нескольких речевых пользователей, содержащая средство для приема файла речевого ввода от текущего пользователя, причем упомянутый текущий пользователь является одним из упомянутых одного или нескольких речевых пользователей, первое средство для автоматического преобразования упомянутого файла речевого ввода в первый письменный текст, причем упомянутое первое средство...
Система передачи данных из скважины с использованием модуляции импеданса (варианты), способ и устройство для передачи

Номер патента: 2894
Опубликовано: 31.10.2002
Автор: Хадсон Стивен Мартин
МПК: H04B 13/02, E21B 47/12
Метки: варианты, передачи, данных, скважины, импеданса, использованием, способ, модуляции, устройство, система
Формула / Реферат:
1. Система передачи данных, содержащая средства генерирования сигнала для генерирования и подачи в сигнальную цепь сигнала, представляющего подлежащие передаче данные, причем средства генерирования сигнала содержат средства генерирования опорного сигнала и модулирующие средства для модуляции опорного сигнала с целью кодирования таким образом подлежащих передаче данных, причем модулирующие средства содержат средства модуляции эффективного...
Способ и устройство для обнаружения факсимильной передачи

Номер патента: 1602
Опубликовано: 25.06.2001
Авторы: Сих Гилберт К., Джон Джонни К.
МПК: H04N 1/327, H04Q 7/32, H04M 1/723...
Метки: передачи, факсимильной, способ, устройство, обнаружения
Формула / Реферат:
1. Устройство передачи речевых и факсовых данных по каналу цифровой связи, содержащее - детектор факсимильного сообщения, выполненный с возможностью отличать данные факсимильного сообщения от речевых данных и конфигурируемый для приёма сигнала, содержащего речевые данные или данные факсимильного сообщения, - мультиплексор, связанный с детектором факсимильного сообщения и выполненный с возможностью выбора между источником выполняемого кода для...
Способ выделения сейсмических сигналов, а также определения и коррекции геометрических и статических ошибок в сейсмических данных

Номер патента: 1766
Опубликовано: 27.08.2001
Автор: Мартин Федерико
МПК: G01V 1/36
Метки: также, коррекции, статических, определения, выделения, сейсмических, способ, данных, сигналов, геометрических, ошибок
Формула / Реферат:
1. Способ автоматического выделения сейсмических сигналов с практически линейными осями синфазности в данных, полученных с применением многоэлементных систем наблюдений, причем для сборок трасс с общим элементом, по меньшей мере, один элемент данных включает источник и, по меньшей мере, еще один элемент данных включает приемник, включающий следующие операции: вычисление комплексной огибающей трасс сборки; сортировку сборок по первой элементной...
Предыдущий патент: Контроль и управление установкой пенной флотации
Следующий патент: Способ запроса электронной информации
Случайный патент: Улучшенное определение экспрессии mage-a