Система и способ синхронизации и организации баз данных
Номер патента: 2931
Опубликовано: 31.10.2002
Авторы: Аммар Мостафа Х., Нават Шамкант Б., Мэлик Санджой, Мэхейджен Самир С., Донаху Майкл Дж., Макджоу Фрэнк Х.










Формула / Реферат
1. Способ обновления баз данных в компьютере клиента, содержащий
группирование данных в серверной базе данных на основе выбранных критериев;
назначение одной или нескольких групп в качестве доступных для компьютеров определенных клиентов;
запись изменений данных каждой группы в файл модификации; и
передачу указанного файла модификации в клиентскую компьютерную систему, имеющую местную базу данных, которая содержит выбранные части данных, по меньшей мере, из одной из указанных групп, предназначенных для компьютера клиента;
обновление указанной базы данных клиентской компьютерной системы с использованием необходимой информации из указанного файла модификации.
2. Способ по п.1, отличающийся тем, что дополнительно содержит стадию связывания множества файлов модификации с группой и отслеживание, какие из множества файлов были переданы в конкретные клиентские компьютерные системы.
3. Способ по п.1, отличающийся тем, что стадия группирования данных основана на предварительно выбранных статических критериях.
4. Способ по п.1, отличающийся тем, что стадия группирования данных основана на динамически создаваемых критериях.
5. Способ по п.2, отличающийся тем, что дополнительно содержит стадию связывания уникальных порядковых номеров с каждым из файлов модификации.
6. Способ по п.1, отличающийся тем, что дополнительно содержит стадию обновления местных баз данных клиентской компьютерной системы с использованием файлов модификации, созданных для записи изменений данных внутри групп, которые предназначены для клиентских компьютерных систем.
7. Способ по п.1, отличающийся тем, что дополнительно содержит стадию передачи клиентской компьютерной системой модификаций, выполненных в указанных выбранных частях, в серверную компьютерную систему.
8. Способ по п.7, отличающийся тем, что дополнительно содержит стадию обновления указанной серверной базы данных с помощью указанных модификаций в указанных выбранных частях данных.
9. Способ по п.8, отличающийся тем, что содержит
определение, какие данные групп серверной базы данных были изменены, создание файлов модификации на основе этих изменений и определения, какие выбранные группы предназначены для клиентской компьютерной системы; и
после определения, какие выбранные группы связаны с клиентской компьютерной системой, передачу файлов модификации, связанных с выбранными группами, в клиентскую компьютерную систему,
10. Способ по п.9, отличающийся тем, что дополнительно содержит стадии
оценки файлов модификации в клиентских компьютерных системах для определения, содержат ли данные в первом файле модификации модификации, которые релевантны модификациям, содержащимся во втором файле модификации; и
обработки релевантных модификаций для обеспечения сохранения согласованности между серверной базой данных и местной базой данных.
11. Способ по п.10, отличающийся тем, что стадия обработки включает в себя определение, какие модификации следует стереть при обновлении местной базы данных.
12. Способ по п.11, отличающийся тем, что стадия обработки включает в себя определение, какие транзакции файлов модификации были созданы клиентской компьютерной системой, подлежащей обновлению, и стирание тех модификаций из файлов модификации, которые были созданы клиентской компьютерной системой, подлежащей обновлению.
13. Способ по п.10, отличающийся тем, что стадия обработки включает в себя определение, какие модификации в файлах модификации дублированы в файле модификации, связанном с другой группой, и сохранение одной модификации для дублированных модификаций и стирание других дублированных модификаций.
14. Способ по п.10, отличающийся тем, что стадия обработки включает в себя объединение релевантной информации между файлами для образования транзакции, которая сохраняет согласованность местной базы данных с серверной базой данных.
15. Способ по п.1, отличающийся тем, что стадия записи изменений включает в себя сохранение клиентского списка изменений, которые были модифицированы, начиная с предыдущего периода времени, когда клиентская компьютерная система была соединена с серверной базой данных.
16. Способ по п.1, отличающийся тем, что стадия назначения содержит сохранение индекса клиента клиентской компьютерной системы, при этом указанный индекс клиента связывает каждую клиентскую компьютерную систему с группой данных, которая связывается на основе содержания элементов данных.
17. Способ по п.1, отличающийся тем, что содержит
определение, какая клиентская компьютерная система соединена с серверной базой данных, и определение, какая выбранная группа предназначена для клиентской компьютерной системы; и
после определения выбранной группы, связанной с клиентской компьютерной системой, передачу файлов модификации, связанных с выбранными группами, в клиентскую компьютерную систему.
18. Система для обновления клиентских компьютерных систем на основе данных в центральной компьютерной системе, содержащая
множество клиентских компьютерных систем;
серверную компьютерную систему, содержащую серверную базу данных, при этом указанная серверная база данных содержит данные, которые сгруппированы на основе предварительно выбранных критериев, и каждый клиент приписан к группе;
файл модификации, созданный для каждой группы данных, в которых изменялись данные, в серверной компьютерной системе, при этом указанный файл модификации включает в себя список транзакций модификаций, которые произошли внутри групп данных; и
программный модуль, который обновляет местные базы данных клиентских компьютерных систем на основе изменений в файлах модификации.
19. Система по п.18, отличающаяся тем, что серверная компьютерная система выполнена с возможностью связывания соответствующих клиентов с выбранными группами данных.
20. Система по п.18, отличающаяся тем, что клиентская компьютерная система содержит клиентский программный модуль, выполненный с возможностью оценивания каждого из файлов модификации и обновления местной базы данных на основе оценки и сравнения информации в файлах модификации.
21. Система по п.20, отличающаяся тем, что клиентский программный модуль выполнен с возможностью обновления местной базы данных путем стирания ненужной информации из файлов модификации.
22. Система по п.20, отличающаяся тем, что клиентский программный модуль выполнен с возможностью передачи модификаций, выполненных в указанных выбранных частях, в серверную базу данных; и
серверная компьютерная система выполнена с возможностью обновления серверной базы данных с помощью модификаций указанных выбранных частей данных.

Текст
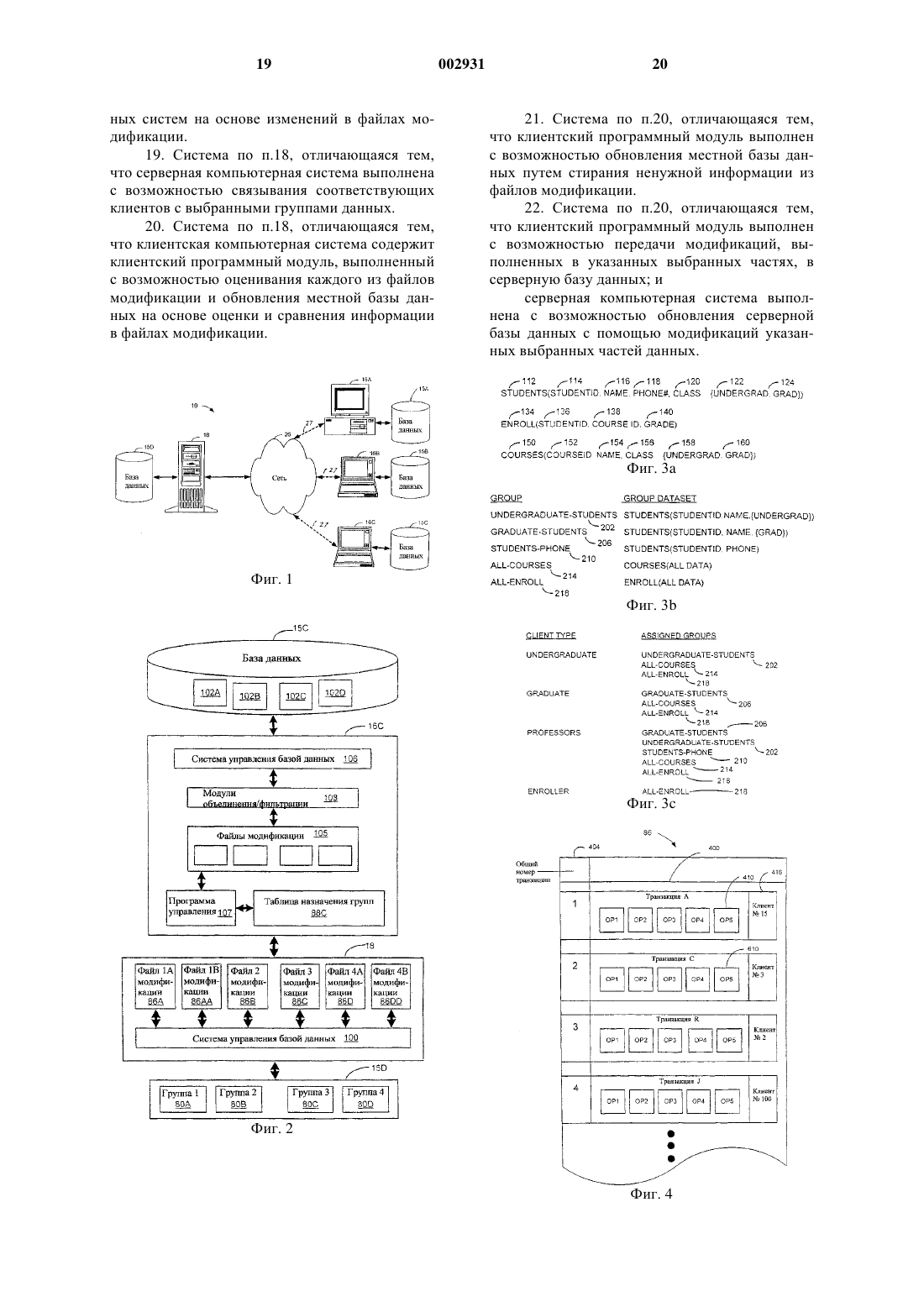
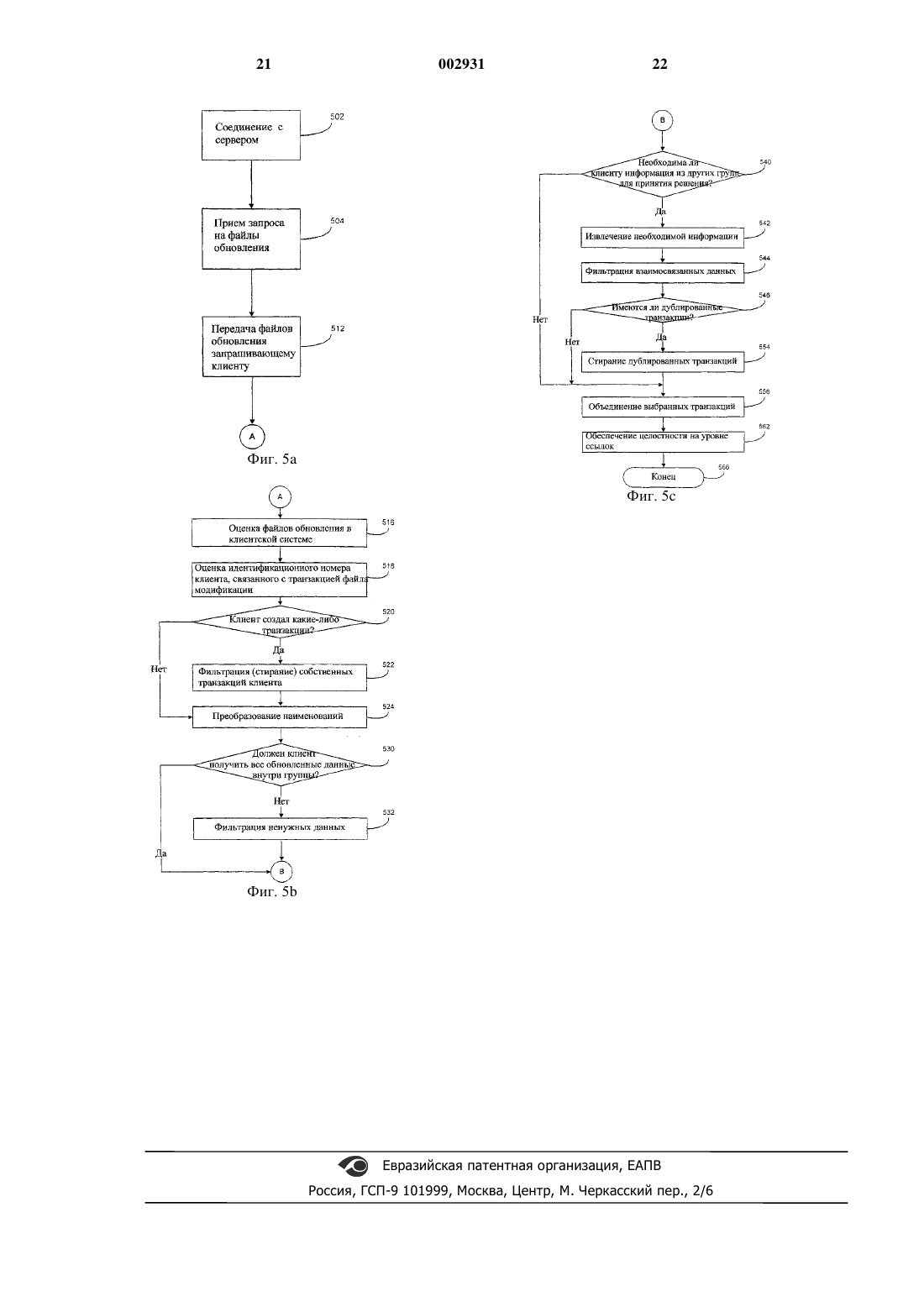
1 Область техники, к которой относится изобретение Данное изобретение относится к способу и системе для обновления баз данных и в частности к способу и системе для синхронизации удаленных баз данных. Уровень техники Во многих корпоративных сетях используют серверную базу данных ("центр") для хранения данных, которые относятся к многим сотрудникам или удаленным пользователям предприятия. Серверная база данных типично доступна для удаленных компьютерных систем("клиентов") для увеличения доступности информации для удаленных пользователей. За счет создания серверной базы данных, к которой могут иметь доступ удаленные компьютерные системы, можно увеличить распределенность информации в компании. Дистанционный доступ в серверную базу данных более затруднен в сетях,где продавцы или многие сотрудники действуют вне офиса. Например, удаленные сотрудники зависят от информации, содержащейся внутри базы данных, для получения информации об изменениях в запасах материалов, ценах и событиях в компании. Вместо того, чтобы оставаться постоянно подключенными к серверной базе данных, что приводит к увеличению телекоммуникационных затрат или к занятости телефонных линий, удаленные пользователи нерегулярно соединяют свои компьютеры с сервером для получения доступа к серверной базе данных. В таких сетях удаленные компьютерные системы обычно хранят часть серверной базы данных на месте для поддержки удаленных запросов, даже когда клиент не соединен с сервером. В этом случае нерегулярное соединение используют для передачи только изменений, вызванных обращением клиента к серверу,и соответствующего набора изменений от сервера к клиенту. Этот тип сети системы удаленных компьютеров называют сетью базы данных с нерегулярным соединением (ICDB). Базы данных с нерегулярным соединением имеют широкое применение в автоматизации торговых операций, обработке страховых претензий и, в целом, для управления мобильной рабочей силой. Важным вопросом связи в компьютерной сети такого типа является своевременный и эффективный обмен информацией между клиентами и серверной базой данных. Часто используют понятие "синхронизация баз данных" для описания процессов сохранения согласованности и целостности данных между серверной базой данных и базами данных клиентов. Имеется много схем синхронизации для сохранения согласованности. В некоторых известных схемах синхронизации баз данных временную метку связывают с обмениваемыми данными и указывают дату передачи последнего обновления. Серверная база данных и база данных клиента используют временную метку для определения, 002931 2 какие записи были модифицированы. Другие схемы используют битовую карту для пометки записей, которые были изменены. В других схемах используют "предыдущие значения" для отслеживания изменений. Обычно передают только те записи, которые были модифицированы после последнего обмена данными. В сетях базы данных с нерегулярным соединением постоянный доступ к прикладной программе требует, чтобы каждый клиент сохранял местную копию совместно используемых данных. Дополнительно к этому при нерегулярном соединении невозможен прямой обмен информацией между клиентами; следовательно, требуется некий посредник для обеспечения связи между клиентами и обмена информацией. Обычно сервер базы данных, схема и данные которого состоят из объединения схем и данных клиентов, выполняет роль этого посредника. Этот сервер постоянно доступен для связи с нерегулярно соединяемыми клиентами. Обновления данных передаются от клиента на сервер. Сервер определяет совокупность клиентов,которые совместно пользуются данными, и ему необходимо получать копию обновлений. Таким образом, при этом "ориентированном на клиентов" подходе сервер должен создавать отдельный комплект данных для каждого клиента. К сожалению, этот подход приводит к усложнению с каждым дополнительным клиентом и ограничен в расширяемости относительно максимального числа клиентов, которые могут поддерживаться сервером, поскольку для каждого дополнительного клиента сервер должен повторять тот же тип обработки, что и для других клиентов. Существуют многие другие технологии для обеспечения надежной синхронизации. Технология обеспечения надежности данных, синхронизованных для удаленных баз данных, описана в патенте США 5 649 195, выданномScott и др. (в последующем патент 195). В этой системе каждый удаленный компьютер содержит тиражируемую копию главной базы данных. Центральный компьютер согласно патенту 195 хранит изменения записей, выполненных в главной базе данных, в течение заданной единицы времени в файле. Каждая запись об изменении для одной и той же единицы времени связывается с одним номером передачи и порядковым номером. Порядковый номер идентифицирует последовательный порядок записей изменений в файле. Последняя запись изменений в последовательном порядке идентифицируется как последняя запись для частного номера передачи. Для следующей единицы времени номер передачи увеличивается на 1 и порядковый номер возвращается в исходное положение. По истечении заданной единицы времени файл записей изменений передается в удаленные тиражируемые копии базы данных. Удаленные компьютеры используют номера передач и поряд 3 ковые номера для проверки порядка записей изменений для определения, все ли записи изменений для передачи были приняты и правильно использованы для обновления удаленной копии базы данных. Другая система для обновления информации в базе данных раскрыта в патенте США 5 491 820, выданном Belove и др. (в последующем патент 820). Патент 820 относится к системе клиент/сервер, которая использует объектноориентированную базу данных в сервере для обеспечения данными нерегулярно соединяемых клиентов. В этой системе объекты данных сохраняются в базе данных. Эти объекты данных могут передаваться клиенту, соединенному с сервером, и затем обновляются после повторного создания связи с сервером. После получения объекта данных клиент связывает время приема с объектом данных. При запросе об обновлении объекта клиент передает перечень объектов данных, подлежащих обновлению,вместе со временем приема каждого объекта. Сервер сохраняет последнее время модификации для каждого объекта данных и сравнивает время приема объекта данных в перечне объектов данных, полученных от клиента, с последним временем его модификации. Сервер создает новые версии этих объектов данных, которые были модифицированы с последнего времени приема. В типичной системе синхронизации отдельный файл, содержащий изменения, подлежащие передаче, создается на сервере для каждого клиента в системе. Это загружает сервер,увеличивая количество обработки, выполняемой в сервере для создания этих файлов, которая прямо пропорциональна числу клиентов в системе. Необходима система синхронизации баз данных, которая позволяет расширять базу данных для использования с возрастающим числом клиентов без отрицательного влияния на производительность сервера. Сущность изобретения В целом, данное изобретение обеспечивает создание способа, который отвечает почти всем необходимым требованиям для хранения и обработки в системе базы данных с нерегулярным соединением. Сокращение обработки улучшает способность сервера обрабатывать большое количество компьютеров клиентов. В частности,данное изобретение обеспечивает создание способа синхронизации системы клиентских компьютеров с серверной базой данных посредством разделения данных, подлежащих распределению с серверной базы данных, на группы и определяет одну или более групп для каждой клиентской компьютерной системы. Изменения данных в группах хранят для передачи клиентам, подписанным на эти группы. Когда клиентская компьютерная система соединяется с сервером, то она передает изменения, произведенные в своей местной базе 4 данных, на сервер. Тогда сервер может обновить свою базу данных с использованием изменений, переданных клиентом. После выполнения обновлений в своей базе данных сервер определяет, к каким группам относятся выполненные изменения, и создает файлы модификации для этих групп. Затем клиенты могут загружать файлы модификации для каждой из групп, на которые подписан клиент. Поскольку файлы модификации могут содержать избыточные данные, то они оцениваются у клиента для определения, следует ли определенные данные применять и объединять или отбросить. Каждый клиент имеет перечень групп, на которые он подписан. Когда клиент соединяется с сервером, то клиент запрашивает файлы модификации, относящиеся к группам, на которые он подписан, объединяет загруженные файлы модификации, отфильтровывает лишние данные и обновляет свою местную базу данных. Таким образом, задачей данного изобретения является создание способа синхронизации базы данных и системы, которая повышает способность системы серверной базы данных обрабатывать множество клиентских компьютерных систем. Задачей данного изобретения является достижение этого посредством группирования данных для улучшения расширяемости системы базы данных. Краткое описание чертежей Эти и другие задачи следуют для специалистов в данной области техники из последующего описания со ссылками на чертежи, где фиг. 1 изображает схему базы данных с нерегулярным соединением; фиг. 2 - подробную блок-схему компонентов клиента и компонентов сервера, используемых во время обновления клиента сервером; фиг. 3 а, 3b, 3 с - примеры группирования данных в базе данных сервера и взаимосвязи клиентов с этими группами согласно данному изобретению; фиг. 4 - схему формата файла модификации согласно данному изобретению; фиг. 5 а, 5b, 5 с - графическую схему программы процесса, применяемого согласно принципам данного изобретения. Подробное описание изобретения На фигурах одинаковые элементы обозначены одинаковыми позициями, при этом на фиг. 1 показаны базовые компоненты системы 10 базы данных с нерегулярным соединением, используемые в предпочтительном варианте выполнения изобретения. Система 10 базы данных с нерегулярным соединением включает клиентские компьютерные системы 16 а, 16b и 16 с. Каждый клиент имеет прикладные программы и местную базу 15 а, 15b и 15 с данных. Компьютерный сервер 18 содержит прикладные программы и серверную базу 15d данных, которые доступны клиентским компьютерным системам 16 через 5 нерегулярные соединения 27. Сервер 18 выполняет административное программное обеспечение для компьютерной сети и управляет доступом к части или ко всей сети и ее устройствам. Клиентские компьютерные системы 16 совместно используют данные серверной базы данных, хранящейся в компьютерном сервере 18, и могут входить в сервер 18 через Интернет, местную вычислительную сеть (LAN), территориально распределенную сеть (WAN) 26 или через телефонную линию с использованием модема. Сервер 28 может быть соединен с местной вычислительной сетью внутри одной организации. Структура и режим работы системы 10 базы данных с нерегулярным соединением позволяют серверу 18 и серверной базе 15d данных,связанной с ним, более эффективно обслуживать клиентов, чем известные до этого системы. В частности, данное изобретение обеспечивает способ организации данных серверной базы данных в отдельные группы и отслеживание изменений данных в соответствии с группами,вместо отдельных клиентов. Периодически создается файл модификации ("дельта" или "обновление") для каждой группы, содержащий все относящиеся к группе изменения со времени создания последнего файла модификации. Клиентские компьютерные системы 16 связаны с выбранными группами, и когда клиенты соединяются с сервером 18, то файлы модификации,связанные с группой, передаются клиенту или клиентам, связанным с группой, для использования для обновления индивидуальной базы данных каждого клиента. Клиентские компьютерные системы 16 а,16b, 16 с могут быть расположены в удаленных местах. Таким образом, когда пользователь одной из клиентских компьютерных систем 16 желает выполнить обновление с учетом текущей информации в совместно используемой базе данных в сервере 18, то компьютерная система 16 соединяется через территориально распределенную сеть или по телефонной линии с сервером 18 для получения доступа. Преимущественно, данное изобретение обеспечивает создание системы и способа обновления клиентских компьютерных систем, которые позволяют добавлять клиентские компьютерные системы в систему базы данных с нерегулярным соединением без необходимости создания системой базы данных с нерегулярным соединением специфичных файлов модификации для каждого клиента, добавляемого в компьютерную систему. В этой системе данные в сервере могут быть расположены в группах, основанных на содержании или семантике. Одна или более групп назначаются каждому клиенту в зависимости от потребности клиента в данных. Периодически сервер определяет данные, которые были изменены в каждой группе со времени последней оценки, и записывает эти изменения в файл модификации. Когда клиент соединяется с серве 002931 6 ром, то он запрашивает файлы модификации для групп, на которые он подписан, соединяет загруженные файлы модификации, отфильтровывает ненужные данные и обновляет свою местную базу данных. Таким образом, данное изобретение обеспечивает "ориентированный на данные" подход к распределению изменений. При таком подходе сложность сервера базы данных относительно хранения и обработки данных не зависит от количества клиентов, которых необходимо поддерживать, что повышает расширяемость сервера. Вместо того, чтобы следить за данными, запрашиваемыми каждым клиентом, способ позволяет отслеживать изменения подмножеств данных, относящихся к группам. Таким образом, сервер должен лишь отслеживать изменения в этих подмножествах данных вместо отслеживания изменений для отдельных клиентов. Затем клиенты загружают подмножества, которые содержат соответствующие данные, из сервера и отфильтровывают возможные излишние данные, которые не относятся к ним. Поскольку сервер отслеживает ограниченный набор подмножеств, относящихся к группам клиентов вместо действительного количества клиентов,то увеличивается общая расширяемость системы. Синхронизация базы данных На фиг. 2 показана блок-схема первичных компонентов, используемых во время обновления баз данных внутри системы 10 базы данных с нерегулярным соединением. Многие компоненты стандартной компьютерной системы не показаны, такие как адресные буферы, буферы памяти и другие компоненты, поскольку эти элементы хорошо известны и не являются необходимыми для понимания данного изобретения. Компьютерные программы и файлы данных,показанные на фиг. 2, используются для выполнения различных стадий данного изобретения. Процесс согласно данному изобретению может выполняться с использованием персональных компьютеров, рабочих станций и серверов. Как указывалось выше, система согласно данному изобретению улучшает способность систем базы данных обрабатывать и обслуживать большее количество клиентов, чем в известных до настоящего времени системах. За счет группирования данных внутри базы 15d данных в группы 80 данных и привязки отдельных файлов 86 модификации (дельта) к каждой группе 80 снижаются непроизводительные затраты, связанные с управлением системы 10 базы данных с нерегулярным соединением, и тем самым улучшается расширяемость системы базы данных. Как показано на фиг. 2, внутри системы 15d базы данных созданы 4 группы 80 а, 80b, 80 с и 80d данных. Элементы данных внутри каждой группы данных не обязательно должны быть исключающими друг друга. То есть группы данных могут содержать ссылки на 7 одни и те же элементы данных. Для каждой из групп 80 данных выделяется ряд файлов 86 модификации. Периодически администратор системы создает новый файл модификации для каждой группы, содержащий все обновления данных, относящихся к группе, со времени создания последнего файла модификации. Файлы 86 а, 86b, 86 с и 86d модификации связаны соответственно с группами 80 а, 80b, 80 с и 80d данных. Файлы 88 аа и 80dd обновления связаны соответственно с файлами 80 а и 80d модификации. Когда выполняются изменения в любом из элементов внутри групп 80a-d данных, то изменения записываются в базе данных. Хотя сотни клиентов могут быть соединены с системой 10 базы данных с нерегулярным соединением, используется относительно небольшое число файлов 86a-d в данном примере для идентификации изменений внутри групп 80a-d данных. В известных до настоящего времени системах система базы данных с нерегулярным соединением должна иметь файлы модификации, связанные с каждым клиентом, и идентифицировать все измененные элементы данных, к которым клиент имеет доступ. Таким образом, в известных до настоящего времени системах система управления базой данных должна хранить и поддерживать множество клиентских файлов для каждого клиента. За счет использования системы согласно данному изобретению, которая группирует элементы данных в группы 80 данных и связывает файлы модификации с каждой из групп данных, преимущественным образом значительно уменьшаются непроизводительные затраты на хранение и обработку в системе базы данных с нерегулярным соединением. Когда клиентская компьютерная система 16 соединена с серверной базой 15d данных, то система 10 управления базой данных обеспечивает интерфейс между серверной базой 15d данных и клиентской компьютерной системой 16 с. Следует отметить, что случай с клиентской компьютерной системой 16 с репрезентативен и для клиентских компьютерные систем 16 а и 16b. Клиентская компьютерная система 16 с также имеет систему 106 управления базой данных, которая обеспечивает интерфейс между местной базой 15 с данных и другими компьютерными системами. В системе 10 базы данных с нерегулярным соединением клиентская компьютерная система 16 сохраняет части данных,содержащихся в базе данных. Части данных,используемые в клиентской компьютерной системе 16, можно рассматривать как подмножество данных серверной базы данных, которые хранятся в местной базе 15 с данных. Местная база 15 с данных содержит информацию, относящуюся к процессам клиентской компьютерной системы 16 с. Клиентская компьютерная система 16 с извлекает данные из соответствующих групп 80 данных, и данные записываются в местную базу 15 с данных. Аналогичным 8 образом, когда модифицируются элементы данных внутри местной базы 15 с данных, то модификации передаются в серверную базу 15d данных из клиентской компьютерной системы 16 с,которые используются для обновления серверной базы 15d данных. Во время передачи информации из местной базы 15 с данных или из серверной базы 15d данных передаваемые данные синхронизируются с соответствующей базой данных. Клиентская компьютерная система 16 с,получающая доступ к серверной базе 15d данных, содержит перечень или таблицу 88 с множества групп, которые ей необходимы. Клиентская компьютерная система входит в контакт с серверной системой и запрашивает текущие файлы модификации для групп, относящихся к клиентской компьютерной системе. Модуль 107 программы управления управляет работой клиентской компьютерной системы 16 с. Во время соединения клиентская компьютерная система 16 с может передавать изменения данных и транзакции в серверную базу 15d данных, которые затрагивают данные в серверной базе 15d данных. Изменения данных, которые произошли в клиентской компьютерной системе 16 с, которые затрагивают данные в серверной базе 15d данных, указываются с помощью файлов 105 модификации. Затем серверная база 15d данных обновляется с использованием изменений из клиентской компьютерной системы и выполняются соответствующие изменения в файлах модификации, связанных с группами, данные которых модифицированы клиентом. Система 100 управления базой данных может осуществить доступ к соответствующим файлам модификации, которые связаны с группами данных, к которым клиент имеет доступ. Эти файлы модификации содержат последовательность транзакций и последовательность операций, которые произошли в соответствующих группах данных. Файлы 86 модификации,которые соответствуют группам данных, к которым имел доступ клиент, передаются затем в клиентскую компьютерную систему 16 с. В известных до настоящего времени системах единственный клиентский файл передавался от системы управления клиентской базой данных. В отличие от известных до настоящего времени систем базы данных с нерегулярным соединением, передается множество файлов модификации, которые связаны с выбранными группами данных, в клиентскую компьютерную систему. Клиентская компьютерная система 16 с оценивает каждый из файлов модификации для определения того, какие обновления будут стерты, реорганизованы или объединены для правильной синхронизации, как более подробно будет описано ниже, местной базы 15 с данных с серверной базой 15d данных. Клиентская компьютерная система 16 может отфильтровывать и/или объединять файлы 80 модификации для обеспе 9 чения целостности базы данных. Система 106 управления базой данных использует модуль 108 фильтрации для фильтрации и объединения множества файлов модификации, принятых из системы 100 управления базой данных. Как показано на фиг. 2, с одной группой может быть связано более одного файла модификации. Для каждого множества или серий файлов модификации, связанных с одной группой, таких как файлы 86 а и 86 аа модификации,каждому из этих файлов модификации придаются порядковые номера. Когда клиентская компьютерная система 16 с получает доступ к серверу 18, клиентская компьютерная система передает на сервер порядковый номер последнего файла обновления, полученного от сервера. Затем сервер передает только те файлы модификации, которые не передавались ранее в клиентскую компьютерную систему 16 с, на основе порядкового номера, полученного из клиентской компьютерной системы 16 с. Сервер передает только те файлы модификации, порядковый номер которых больше, чем порядковый номер, принятый от клиентской компьютерной системы. Может быть создан отдельный файл 86 модификации для группы, когда количество транзакций, содержащихся в файле, превосходит определенное количество, после истечения определенного периода времени или после того,как определенный ряд соединенных клиентских компьютерных систем завершат выполнение изменений данных определенных групп. Другие схемы определения, когда необходимо создавать несколько файлов модификации для групп,хорошо известны для специалистов в данной области техники и находятся внутри объема данного изобретения. На фиг. 3 а, 3b и 3 с показана основная схема группирования клиентов. Примеры группирования, показанные на фиг. 3 а, 3b и 3 с, описаны в терминах реляционной базы данных и технологий программирования реляционной базы данных. Группирование данных можно выполнять различными способами. Подходящее группирование для конкретной системы зависит от многих факторов, включая скорость обработки сервера, объема диска сервера и пропускной способности сети. Технологии группирования можно разделить на две категории: динамическую и статическую. При статическом группировании, показанном на фиг. 3 а, 3b и 3 с, группы данных известны заранее. При статическом группировании администратор может задавать группы. Клиентская компьютерная система подписана или связана с выбранными группами. Статическое группирование уменьшает требования к обработке в сервере при выполнении распределения файлов модификации, независимо от соединенных клиентов. Для специалистов в данной области техники известно, что горизонтальные или вертикальные сегменты отношений данных 10 называются фрагментами и задаются заранее с помощью схемы разделения на части. Фрагменты содержаться в одной или более группах. Можно использовать также динамическое группирование, хотя оно и не показано. При динамическом группировании количество и структура групп зависят от постоянно меняющихся признаков, таких как текущий набор транзакций и/или текущий набор соединенных клиентов. В одном типе динамического группирования отдельные группы существуют для каждой транзакции и клиентская компьютерная система подписывается на группы в зависимости от применяемых транзакций. Такой тип группирования называется ориентированным на транзакции группированием. Другим типом динамического группирования является ориентированное на объем группирование. В ориентированном на объем группировании образуется минимальное количество групп для обеспечения того, чтобы клиенты имели возможность, подписавшись на минимальное число групп, получать минимальное количество лишних данных. Динамические технологии группирования помогают уменьшить ширину полосы и обработку по фильтрации у клиента посредством передачи только данных, относящихся к текущему набору соединенных клиентов. Однако такие технологии требуют обычно большего объема обработки в сервере, поскольку сервер динамично координирует группирования для обслуживания комбинаций клиентов и данных. В ориентированном на объем группировании сервер координирует обновления групп для распространения для каждого набора соединенных клиентов. В ориентированных на транзакции сетях сервер связывается с каждым клиентом отдельно для обработки операций обновления для каждого соответствующего клиента. На фиг. 3 а показан способ, с помощью которого можно организовывать серверные данные. Список 112 обучающихся (STUDENTS) содержит идентификационный номер 114 обучающегося (STUDENTID), имя 116 (NAME),номер 118 телефона (PHONE) и переменную для 120 класса (CLASS), которая может быть студентами 122 (UNDERGRAD) или аспирантами 124 (GRAD). Общая схема сервера также включает в себя список 134 зачислений (ENROLL),который включает в себя идентификационный номер 136 обучающихся (STUDENTID), идентификационный номер 138 курса (COURSEID) и идентификационный номер 140 степени(GRADE). Другая запись схемы устройства серверных данных включает в себя запись 150 курсов (COURSES), которая включает в себя идентификационный номер 152 курса (COURSEID),наименование 154 курса (NAME) и переменную запись 156 классов (CLASS), которая содержит перечень 158 студентов (UNDERGRAD) и перечень 160 аспирантов (GRAD). 11 На фиг. 3b показана таблица идентификаторов групп. Показаны идентификаторы 202,206, 210, 214 и 218, связанные с или выделенные для групп данных базы данных. Идентификатор 202 студентов включает в себя информацию 112 об обучающихся, где класс определен как студенты 122 без номера 118 телефона. Идентификатор 204 группы аспирантов включает в себя информацию 112 об обучающихся, где класс определен как аспиранты 124, без номера 118 телефона. Идентификатор 206 группы номеров телефонов обучающихся включает в себя список 112 обучающихся с указанием только идентификационных номеров 114 обучающихся и номеров 118 телефонов. Группа 212 идентификаторов всех курсов включает в себя все данные о курсах в записи 150. Класс 216 всех зачисленных включает в себя все данные списка 134 зачислений. На фиг. 3 с показано распределение клиентов по группам. В эту таблицу сначала получает доступ система управления серверной базой данных для определения, какие файлы 86 модификации должны быть выбраны для клиента. Студенты (UNDERGRADUATE) распределены на группу 202 студентов (UNDERGRADUATESTUDENTS), группу 214 всех курсов (ALLCOURSES) и группу 218 всех зачислений (ALLENROLL). Аспиранты (GRADUATE) распределены на группу 206 аспирантов (GRADUATESTUDENTS), группу 214 всех курсов (ALLCOURSES) и группу 218 всех зачислений (ALLENROLL). Профессоры клиенты (PROFESSORS) распределены на группу 206 аспирантов(ENROLLER) распределены на группу 218 данных всех зачислений (ALL-ENROLL). Эти группы данных и связи используются для обновления и синхронизации компьютеров внутри системы 10 базы данных с нерегулярным соединением. Сервер 18 обрабатывает пакетированные обновления, полученные от клиентов 16, и выполняет обновления в сервере 18 для создания дельта-файла для каждой группы на основе знания данных, которые используются совместно с каждым клиентом. На фиг. 3 с показан файл 86 модификации (дельта-файл). Файл 86 идентификации для клиента содержит все операции с набором данных, которые относятся к изменениям данных групп, к которым относится клиент. Файл 86 модификации включает в себя последовательность транзакций, таких как транзакция А, транзакция С, транзакция R и транзакция J, каждая из которых идентифицируется уникальным общим порядковым номером (например, 1, 2, 3, 4, 5,), который указывает порядок выполнения транзакций в сервере 18. Ка 002931 12 ждая транзакция представляет последовательность операций 410, и каждая операция имеет уникальный порядковый номер, такой как ОР 1,ОР 2, ОР 3, ОР 4 и ОР 5, которые указывают порядок выполнения операции внутри транзакции. Каждая операция относится только к одному фрагменту. Каждая транзакция идентифицирует клиентскую компьютерную систему 16, в которой она была впервые выполнена, как часть записи транзакции. Идентификационный номер 416 клиента связан с транзакцией. За счет использования порядковых номеров 404 транзакций компьютерная система 16 может реконструировать порядок выполнения операций, произошедших в сервере 18, независимо от фрагментации операций в файле 400 модификации. Поскольку каждая операция выполняется с помощью одного фрагмента, то нет взаимных зависимостей между этими операциями, за исключением зависимостей от внешнего ключа. Взаимосвязанные операции без зависимости от внешнего ключа могут быть расположены в любом порядке. Взаимосвязанные операции сохраняют последовательный порядок в сервере. При предположении, что внешний ключ выводится из отношения, называемого"родительским отношением", а первичный ключ из отношения, называемого "дочерним отношением", взаимосвязанные операции с отношениями, связанными с внешним ключом, располагаются так, что вставка в родительские отношения предшествует соответствующей вставке в дочернее отношение; и стирание в дочерних отношениях предшествует соответствующему стиранию в родительских отношениях. Фильтрация Как указывалось выше, различные группы данных могут содержать информацию, которую конкретный клиент не должен получать, или информацию, которую клиент уже имеет. Например, если клиент выполняет изменение данных внутри базы данных, то клиент уже имеет изменение или запись изменения, которое было выполнено в базе данных. Следовательно, когда файлы модификации, которые содержат все операции, которые были выполнены, включают в себя операции обновления, выполненные конкретным клиентом, то операции, выполненные конкретным клиентом, не должны обрабатываться или использоваться, когда клиентская компьютерная система 16 принимает файлы 86 модификации для связанных с ними групп данных. Следовательно, клиентская компьютерная система 16 выполняет фильтрацию, распределение и объединение операций для обеспечения целостности местной базы данных при выполнении обновлений. Типы обработки, выполняемой в клиентской компьютерной системе 16,включают в себя отражательную фильтрации,схемы распределения, фильтрацию внутренних взаимосвязей,фильтрацию взаимосвязей,фильтрацию дубликатов, соединение операций 13 и расположение с обеспечением целостности на уровне ссылок. Ниже приводится описание фильтрации с использованием примеров групп,показанных на фиг. 3 а, 3b и 3 с. Отражательная фильтрация относится к клиентской компьютерной системе, оценивающей файлы 86 модификации для транзакций,которые были переданы в клиентскую компьютерную систему и были первоначально выполнены в клиентской компьютерной системе. Схема распределения является процессом, с помощью которого клиент применяет конверсию синонимов к наименованиям групп, которые названы по другому в местной базе 15 с данных, чем в серверной базе 15d данных. Это обеспечивает правильное согласование групп во время обновления для обеспечения целостности данных для групп внутри баз данных. Фильтрация данных для отношений, основанных на данных, являющихся внутренними для отношения,называется фильтрацией внутренних взаимосвязей. Фильтрация внутренних взаимосвязей отфильтровывает избыточные данные колонки и строки, которые могут быть переданы клиенту. Например, студенты получают данные из отношения зачислений; однако, студенты не авторизованы на просмотр данных об аспирантах. Поэтому информация об аспирантах изымается или стирается из группы списка зачислений,когда она передается студентам. Аналогичным образом, аспиранты получают все данные из курсовых записей; однако, аспиранты авторизованы только на просмотр информации об аспирантах. В примере, показанном на фиг. 3 а, 3b,3 с, фильтрация группы курса для студентов означает, что информация об аспирантах стирается или изымается."Фильтрация данных" группы, которая используется совместно, на основе данных в другой таблице базы данных, называется фильтрацией взаимосвязей. Фильтрация взаимосвязей осуществляется, поскольку не все лишние данные отфильтровываются с помощью данных внутри группы. Например, студенты должны получать только данные группы 218 всех зачислений; однако, для определения того, предназначена ли группа 134 зачислений для студента,необходимо определить идентификационный номер курса с использованием группы 134 курса. В показанном на фиг. 3b примере группирования студент получает данные о зачислениях в группе 218 всех зачислений. Затем студент использует группу 214 курса для определения,какие данные о зачисленных должны быть отфильтрованы. Удаление дубликатов относится к процессу обнаружения и стирания/удаления копий транзакций. Копии транзакций возникают, потому что одни и те же данные могут повторяться более чем в одной группе. В показанных на фиг. 3 а, 3b, 3 с примерах профессоры совместно используют группу 202 студентов,группы 206 аспирантов, и группы 210 телефо 002931 14 нов обучающихся. Например, исключение одного обучающегося приводит к тому, что транзакция будет передана дважды профессору, поскольку группа 210 телефонов обучающихся и группы 202 студентов по определению основаны на списке 112 обучающихся. В каждой из этих групп присутствует идентификационный номер обучающегося. Поэтому клиентпрофессор должен обнаружить копию транзакции и выполнить одно стирание для местной базы 15d данных."Соединение операций" включает в себя соединение операций, которые были разделены при размещении в группы. Операции транзакций могут быть разделены при помещении в группы. Клиенты должны проверять, что эти операции объединены для сохранения целостности. Рассмотрим, например, следующую последовательность операций в сервере.ID=1000; последовательность операций разделяется на следующие последовательности для групп студентов и телефонов обучающихся соответственно:ID=1000. Клиент-профессор должен объединить транзакции из студентов и телефонов обучающихся так, чтобы (1) вставки были объединены в одну вставку, (2) исключались стирания копий и (3) объединенная вставка выполнялась перед стиранием."Расположение с обеспечением целостности на уровне ссылок" включает в себя обработку файлов модификации для обеспечения того,чтобы транзакции, которые ссылаются на другие группы, сохраняли свою целостность во время объединения транзакций. При транзакции объединения клиент должен учитывать ограничения, накладываемые требованием сохранения целостности на уровне ссылок. Выполнение транзакций не по порядку у клиента может приводить к отклонениям операций у клиента, которые были разрешены на сервере, что приводит к разрушению целостности данных клиента. Рассмотрим две вставки на сервере:INSERT (1001, 6555) INTO Enroll. Эти две вставки получат клиентыаспиранты соответственно в группах "Все курсы" и "Все зачисления". Следует учесть, что"Курсы. Идентификационный номер курса" яв 15 ляется внешним ключом для "Зачисления. Идентификационный номер курса"; следовательно, необходимо сохранить порядок вставок,в частности кортеж для таблицы "Курсы" должен быть вставлен перед вставлением кортежа"Зачисления". В целом, необходимо сохранять определенный порядок операций с различными взаимоотношениями, на которые распространяются ограничения, связанные с необходимостью сохранения целостности на уровне ссылок. Процессы, выполняемые в системе базы данных с нерегулярным соединением На фиг. 5 а, 5b и 5 с показаны процессы,выполняемые согласно данному изобретению. Эти процессы описывают процесс, используемый для соединения клиентских компьютерных систем 16 с группами данных серверной базы 15d данных во время соединения серверной базы 15d данных с клиентской компьютерной системой 16. Процессы описывают также процесс синхронизации между базами данных системы базы данных с нерегулярным соединением. На стадии 502 клиентская компьютерная система 16 соединяется с сервером 18. На стадии 504 сервер 18 принимает запрос на обновление от клиентской компьютерной системы. На стадии 512 файлы 86 модификации передаются в запрашивающую клиентскую компьютерную систему 16. На стадии 516 клиентская компьютерная система 16 начинает анализ файлов 400 модификации для определения, какие данные из файла 86 модификации необходимо отфильтровать, объединить, стереть или подвергнуть другой модификации. На стадии 518 процесс оценивает идентификационный номер клиента и файл модификации, и на стадии 520 процесс определяет, создавала ли клиентская компьютерная система 16 какие-либо транзакции в файле модификации. Если клиент создал какие-либо транзакции, то процесс переходит на стадию 522, в которой отфильтровываются транзакции, созданные клиентом. Затем процесс переходит на стадию 524. Однако, если на стадии 520 будет установлено,что ни одна из транзакций не создана клиентом,то процесс переходит на стадию 524. На стадии 524 клиентская компьютерная система при необходимости выполняет преобразование синонимов или наименований в системе базы данных клиента, как указывалось выше. Затем процесс переходит на стадию 530. На стадии 530 процесс определяет, должен ли клиент получить все данные, содержащиеся в группе. Процесс переходит на стадию 532, в которой отфильтровываются все дубликаты данных. Затем процесс переходит на стадию 540. Однако, если на стадии 530 будет установлено, что клиент должен получить все данные, содержащиеся в группе данных, то процесс переходит непосредственно на стадию 540. На стадии 540 процесс определяет, необходима ли клиентской компьютерной системе 16 16 информация из других групп для выполнения надежного обновления местной базы 15 с данных. Если клиенту 16 необходима информация из других групп для обновления определенной информации, то процесс переходит на стадию 542, в которой информация, необходимая для выполнения обновлений, извлекается из других групп. Процесс переходит на стадию 544. На стадии 544 процесс отфильтровывает взаимосвязанные данные для нахождения необходимой информации, как указывалось выше. Процесс переходит на стадию 546. На стадии 546 процесс определяет, копировались ли транзакции. Если на стадии 546 не будет обнаружено копий транзакций, то процесс переходит на стадию 556. Однако, если на стадии 546 будет установлено, что транзакции копированы, то дубликат информации стирают на стадии 554. На стадии 556 процесс определяет, есть ли необходимость объединять какие-либо операции, обнаруженные в файлах модификации, и при необходимости объединяет файлы. Затем процесс переходит на стадию 562, на которой оценивается целостность на уровне ссылок файлов модификации. Процесс заканчивается на стадии 566. Приведенные описания даны только в качестве примеров и не должны ограничивать принципы или объем данного изобретения. Для специалистов в данной области техники из описания следуют многие модификации, изменения или продолжения описанных специальных вариантов выполнения без выхода из объема изобретения, определяемого прилагаемой формулой изобретения. ФОРМУЛА ИЗОБРЕТЕНИЯ 1. Способ обновления баз данных в компьютере клиента, содержащий группирование данных в серверной базе данных на основе выбранных критериев; назначение одной или нескольких групп в качестве доступных для компьютеров определенных клиентов; запись изменений данных каждой группы в файл модификации; и передачу указанного файла модификации в клиентскую компьютерную систему, имеющую местную базу данных, которая содержит выбранные части данных, по меньшей мере, из одной из указанных групп, предназначенных для компьютера клиента; обновление указанной базы данных клиентской компьютерной системы с использованием необходимой информации из указанного файла модификации. 2. Способ по п.1, отличающийся тем, что дополнительно содержит стадию связывания множества файлов модификации с группой и отслеживание, какие из множества файлов были переданы в конкретные клиентские компьютерные системы. 17 3. Способ по п.1, отличающийся тем, что стадия группирования данных основана на предварительно выбранных статических критериях. 4. Способ по п.1, отличающийся тем, что стадия группирования данных основана на динамически создаваемых критериях. 5. Способ по п.2, отличающийся тем, что дополнительно содержит стадию связывания уникальных порядковых номеров с каждым из файлов модификации. 6. Способ по п.1, отличающийся тем, что дополнительно содержит стадию обновления местных баз данных клиентской компьютерной системы с использованием файлов модификации, созданных для записи изменений данных внутри групп, которые предназначены для клиентских компьютерных систем. 7. Способ по п.1, отличающийся тем, что дополнительно содержит стадию передачи клиентской компьютерной системой модификаций,выполненных в указанных выбранных частях, в серверную компьютерную систему. 8. Способ по п.7, отличающийся тем, что дополнительно содержит стадию обновления указанной серверной базы данных с помощью указанных модификаций в указанных выбранных частях данных. 9. Способ по п.8, отличающийся тем, что содержит определение, какие данные групп серверной базы данных были изменены, создание файлов модификации на основе этих изменений и определения, какие выбранные группы предназначены для клиентской компьютерной системы; и после определения, какие выбранные группы связаны с клиентской компьютерной системой, передачу файлов модификации, связанных с выбранными группами, в клиентскую компьютерную систему,10. Способ по п.9, отличающийся тем, что дополнительно содержит стадии оценки файлов модификации в клиентских компьютерных системах для определения, содержат ли данные в первом файле модификации модификации, которые релевантны модификациям, содержащимся во втором файле модификации; и обработки релевантных модификаций для обеспечения сохранения согласованности между серверной базой данных и местной базой данных. 11. Способ по п.10, отличающийся тем, что стадия обработки включает в себя определение,какие модификации следует стереть при обновлении местной базы данных. 12. Способ по п.11, отличающийся тем, что стадия обработки включает в себя определение,какие транзакции файлов модификации были созданы клиентской компьютерной системой,подлежащей обновлению, и стирание тех моди 002931 18 фикаций из файлов модификации, которые были созданы клиентской компьютерной системой,подлежащей обновлению. 13. Способ по п.10, отличающийся тем, что стадия обработки включает в себя определение,какие модификации в файлах модификации дублированы в файле модификации, связанном с другой группой, и сохранение одной модификации для дублированных модификаций и стирание других дублированных модификаций. 14. Способ по п.10, отличающийся тем, что стадия обработки включает в себя объединение релевантной информации между файлами для образования транзакции, которая сохраняет согласованность местной базы данных с серверной базой данных. 15. Способ по п.1, отличающийся тем, что стадия записи изменений включает в себя сохранение клиентского списка изменений, которые были модифицированы, начиная с предыдущего периода времени, когда клиентская компьютерная система была соединена с серверной базой данных. 16. Способ по п.1, отличающийся тем, что стадия назначения содержит сохранение индекса клиента клиентской компьютерной системы,при этом указанный индекс клиента связывает каждую клиентскую компьютерную систему с группой данных, которая связывается на основе содержания элементов данных. 17. Способ по п.1, отличающийся тем, что содержит определение, какая клиентская компьютерная система соединена с серверной базой данных, и определение, какая выбранная группа предназначена для клиентской компьютерной системы; и после определения выбранной группы,связанной с клиентской компьютерной системой, передачу файлов модификации, связанных с выбранными группами, в клиентскую компьютерную систему. 18. Система для обновления клиентских компьютерных систем на основе данных в центральной компьютерной системе, содержащая множество клиентских компьютерных систем; серверную компьютерную систему, содержащую серверную базу данных, при этом указанная серверная база данных содержит данные,которые сгруппированы на основе предварительно выбранных критериев, и каждый клиент приписан к группе; файл модификации, созданный для каждой группы данных, в которых изменялись данные,в серверной компьютерной системе, при этом указанный файл модификации включает в себя список транзакций модификаций, которые произошли внутри групп данных; и программный модуль, который обновляет местные базы данных клиентских компьютер 19 ных систем на основе изменений в файлах модификации. 19. Система по п.18, отличающаяся тем,что серверная компьютерная система выполнена с возможностью связывания соответствующих клиентов с выбранными группами данных. 20. Система по п.18, отличающаяся тем,что клиентская компьютерная система содержит клиентский программный модуль, выполненный с возможностью оценивания каждого из файлов модификации и обновления местной базы данных на основе оценки и сравнения информации в файлах модификации. 20 21. Система по п.20, отличающаяся тем,что клиентский программный модуль выполнен с возможностью обновления местной базы данных путем стирания ненужной информации из файлов модификации. 22. Система по п.20, отличающаяся тем,что клиентский программный модуль выполнен с возможностью передачи модификаций, выполненных в указанных выбранных частях, в серверную базу данных; и серверная компьютерная система выполнена с возможностью обновления серверной базы данных с помощью модификаций указанных выбранных частей данных.
МПК / Метки
МПК: G06F 17/30
Метки: баз, способ, синхронизации, организации, данных, система
Код ссылки
<a href="https://eas.patents.su/12-2931-sistema-i-sposob-sinhronizacii-i-organizacii-baz-dannyh.html" rel="bookmark" title="База патентов Евразийского Союза">Система и способ синхронизации и организации баз данных</a>
Система и способ использования администратора данных рабочей области для доступа, обработки и синхронизации сетевых данных

Номер патента: 2411
Опубликовано: 25.04.2002
Автор: Мендез Дэниел Дж.
МПК: G06F 17/30
Метки: данных, использования, система, области, синхронизации, администратора, доступа, обработки, рабочей, сетевых, способ
Формула / Реферат:
1. Способ синхронизации данных с удаленной станцией, базирующийся на использовании компьютера, заключающийся в том, что загружают данные из удаленной станции, запрашивают администратора данных рабочей области о разрешении обработки данных и создают тем самым обработанные данные и синхронизируют обработанные данные с данными, хранящимися в удаленной станции. 2. Способ по п.1, отличающийся тем, что дополнительно осуществляют запрос администратора...
Система сбора, регистрации данных и выдачи записанных в зу средств, устройство сбора и регистрации данных для нее и способ эксплуатации системы

Номер патента: 2002
Опубликовано: 22.10.2001
Автор: Костерке Райнхард
МПК: G07C 9/00, G07F 17/42
Метки: регистрации, система, сбора, системы, эксплуатации, нее, записанных, средств, устройство, выдачи, способ, данных
Формула / Реферат:
1. Система сбора, регистрации данных и выдачи записанных в ЗУ средств, содержащая а) устройство (1) сбора и регистрации служебной и персонифицированной информации, которое имеет - устройство считывания (8, 10), по меньшей мере, с одним блоком считывания первых записанных в ЗУ персонифицированных и мобильных средств, - устройство (4) ручного ввода данных, - устройство (2) управления вводом определенных персонифицированных данных в режиме...
Способ сокращения объема памяти, требуемого базой данных для хранения данных, и создания базы данных

Номер патента: 1826
Опубликовано: 27.08.2001
Автор: Эль-Газзар Амин
МПК: G06F 17/30
Метки: сокращения, объема, базой, способ, создания, данных, хранения, памяти, базы, требуемого
Формула / Реферат:
1. Способ сокращения объема памяти, требуемого базой данных для хранения информации, отличающийся тем, что - сохраняемые единицы информации распределяют по точкам пересечения строк и столбцов, по меньшей мере, двумерной растровой матрицы, - размещенным в растровой матрице единицам информации присваивают индивидуальные координаты цвета и - сформированную таким путем матрицу изображения сохраняют в качестве базы данных или части базы данных. 2....
Способ и система оценивания набора данных (варианты)

Номер патента: 1738
Опубликовано: 27.08.2001
Автор: Нелсон Филипп К.
МПК: G06F 17/30
Метки: варианты, система, набора, оценивания, способ, данных
Формула / Реферат:
1. Способ оценки набора данных для определения того, удовлетворяет ли этот набор данных один или несколько из множества запросов, причем содержание набора данных описывают с помощью одной или нескольких частей сведений, запросы группируют в исполнительный план из запросов, в котором каждый запрос связан с одним или несколькими другими запросами, каждый из множества запросов включает в себя одно или несколько запросных условий, каждое из которых...
Устройство, система и способ передачи и отображения собранных данных скважины, в близком к реальному масштабе времени в удаленном местоположении

Номер патента: 1613
Опубликовано: 25.06.2001
Авторы: Альварадо Хуан С., Краевич Даниелли С.П., Провост Дж.Томас
МПК: H04L 29/06, G06F 17/40
Метки: скважины, система, собранных, передачи, отображения, данных, способ, времени, близком, реальному, устройство, местоположении, удаленном, масштабе
Формула / Реферат:
1. Система визуального наблюдения данных каротажной диаграммы скважины в близком к реальному масштабе времени первичном местоположении (40) и удаленном местоположении (100), имеющая первичное местоположение (40), имеющее устройство (422) представления данных и первое средство (60, 70) отображения, выполненные с возможностью приема сигналов из первого устройства (422) представления данных и визуального наблюдения представленных каротажных...